Умеет ли человечество писать алгоритмы? Безошибочные алгоритмы и язык ДРАКОН -3
Программирование микроконтроллеров, Бизнес-модели, Программирование, Алгоритмы, Recovery Mode, Визуальное программирование
Рекомендация: подборка платных и бесплатных курсов Smm — https://katalog-kursov.ru/
Содержание
Введение
1. Трагедия Боинга 737 МАХ
2. Безошибочность алгоритмов
3. Язык ДРАКОН
4. Визуальное структурное программирование
5. Аксиоматический метод
6. ДРАКОН-конструктор
7. Алгоритмическая логика
8. Доказательство правильности
9. Семейство ДРАКОН-языков
10. Автоматное программирование
11. Учебное пособие по языку ДРАКОН для вузов
12. Недостатки языка ДРАКОН
13. В чем сила языка ДРАКОН
14. На руках разработчиков алгоритмов кровь сотен людей
15. Литература
Аннотация. О чем пойдет речь?
Речь пойдет об визуальном алгоритмическом языке ДРАКОН, который опирается на мантру безошибочности.
ДРАКОН — это попытка покончить с пагубными привычками мэйнстрима, когда заказчик и исполнитель с трудом понимают друг друга, когда тестирование и отладка занимают много времени, когда продукты сдаются заказчику со скрытыми дефектами и порождают болезненные доработки. Такое положение следует решительно изменить.
Конечно, это не просто и серебряной пули нет. А может, все-таки есть, хоть и не серебряная?
ДРАКОН-методология покоится на двух китах: когнитивной эргономике (наглядность) и неклассической теории алгоритмов (надежность). Это не просто наглядность и надежность. Это стремление достичь амбициозную цель: сверхвысокую наглядность и безошибочность, которая раньше считалась невозможной.
Чтобы докопаться до истины и показать возможность разумного пути к безошибочному будущему, стоит начать с анализа крупнейшей по числу жертв алгоритмической трагедии в истории человечества.

Телестудия Роскосмоса.
Кадр из фильма «Жирограф и ДРАКОН Пилюгина».
.

Сколько стоят ошибки в алгоритмах
Умеют ли люди писать алгоритмы? В корпорации Боинг трудятся умные люди высочайшей квалификации. Они, несомненно, умеют писать алгоритмы.
Но с ошибками.
Сколько стоят ошибки? Немало. Фирма Boeing согласилась выплатить 2,5 миллиарда долларов, чтобы избавиться от суда об утаивании проблем с самолетом Боинг 737 MАХ от авиационного регулятора FAA.
И всего-навсего 500 миллионов долларов (из этих денег) достанутся семьям погибших в авиакатастрофах компаний Ethiopian Airlines и Lion Air.
Цель — безошибочность
Ошибки в алгоритмах и программах — острая проблема. Исправление промахов и ошибок приводит к дополнительным затратам труда и времени, перерасходу средств и порою к дополнительным издержкам, как у Боинга. Отчасти это объясняется тем, что понятие алгоритма, его свойства и нотации разрабатывались без учета проблемы человеческих ошибок.
Эффективная и удобная нотация для записи алгоритмов до сих пор не создана. Нотации, конечно, есть, но они с неумолимой неизбежностью воспроизводят ошибки.
Новая нотация
Актуальная задача — предложить новую нотацию и показать, что она содействует безошибочности. Этого мало. В новую нотацию нужно встроить незаметный для пользователей математический аппарат, предотвращающий ошибки.
Чтобы подчеркнуть важность понятия «безошибочный алгоритм», полезно проанализировать инцидент с самолетом Боинг 737 МАХ, алгоритмы которого оказались ошибочными и привели к катастрофе.
Макроалгоритмы
Макроалгоритмы — это алгоритмы в широком смысле. Макроалгоритмы делятся на компьютерные алгоритмы (которые выполняются компьютерами) и жизнеритмы, выполняемые людьми.
Макроалгоритм большой человеко-машинной системы содержит взаимоувязанные и согласованные между собой алгоритмы и жизнеритмы.
Примером большой человеко-машинной системы служит фирма Боинг, огромная фирма, на которой трудятся 150 000 человек. Это люди высочайшей квалификации, обладающие огромными знаниями. Что же их подвело?

Что случилось с лайнером Боинг 737 MAX
Сайт корпорации Боинг
Через считанные минуты после взлета, когда надо было срочно набирать высоту, произошло невероятное — автоматическая система управления внезапно направила нос самолета к земле. Экипаж изо всех сил пытался выровнять лайнер и избежать катастрофы. Но все было тщетно. Автоматика была непреклонна и по крутой траектории вела воздушное судно вниз — навстречу неминуемой гибели.
Трагедия повторилось дважды: 29 октября 2018 года в Индонезии и спустя полгода, 10 марта в Эфиопии. Погибли 346 человек: все пассажиры и оба экипажа. Выживших не было.
В тисках конкуренции
Знаменитая американская корпорация Боинг была озабочена конкуренцией с мощной европейской фирмой Эйрбас. Соперничество двух авиагигантов всегда было напряженным. Самолеты Боинг 737 и европейский А320 стали рабочими лошадками мира пассажирских перевозок.
Они тысячами летали на маршрутах короткой и средней дальности по всей планете. Их продажи были для обоих концернов надежным источником дохода. Рынок был поделен примерно поровну. Но обновленный лайнер А320 грозил нарушить равновесие и вывести Эйрбас далеко вперед.
Новые А320 обещали быть существенно дешевле в эксплуатации. В последние годы расходы на топливо составляли почти 25% операционных расходов авиакомпаний. Эйрбас обещал, что новые самолеты будут на 15% экономичнее прежних.
Новые двигатели на лайнере Боинг 737 MAX
Заказы на новый самолет, названный A320neo, посыпались на европейский концерн. Спрос на лайнер 737 между тем заметно снизился. Боинг не мог оставить это без ответа.
Современные двигатели гораздо тише и экономичнее своих предшественников, но по технологическим причинам они гораздо больше в диаметре.
Боинг собирался установить на самолетах 737 МАХ наиболее экономичные двигатели LEAP производства фирмы CFM. Но Эйрбас его опередил.
Коммерческое самоубийство
Как только было объявлено, что Эйрбас будет использовать более бережливые двигатели на новом самолете А320, у Боинга не осталось выхода. Поступить иначе означало совершить коммерческое самоубийство.
И работа закипела! Однако под низко расположенное крыло лайнера 737 новый двигатель не влезал. Его пришлось выдвинуть на пилоне вперед и вверх. Это решило одну проблему, но создало другую.
Новое распределение веса и аэродинамика крыла с двигателем придали самолету необычные характеристики управляемости. У лайнера 737 МАХ обнаружилась тенденция сильно задирать нос, особенно если угол атаки (угол между осью фюзеляжа и землей) слишком велик.
Слишком большой угол атаки
Это очень неприятно. Излишне большой угол атаки может привести к сваливанию — то есть к тому, что набегающий поток воздуха перестанет создавать подъемную силу, которая поддерживает самолет в воздухе. И он начнет стремительно терять высоту. Летчики тщательно избегают подобных ситуаций.
Опытные пилоты-испытатели обнаружили, что новый самолет 737 МАХ управляется совсем не так, как предыдущие поколения 737-й модели. Значит, прежние навыки пилотирования здесь не годятся.
Что делать? Создавать учебный тренажер-симулятор нового лайнера и переучивать сотни пилотов? Но ведь это лишнее время и огромные расходы.
Зачем понадобилась система MCAS
Творческая мысль на выдумки хитра. Находчивые инженеры Боинга придумали палочку-выручалочку под названием «Улучшение характеристик системы маневрирования» — Maneuvering Characteristics Augmentation System (MCAS). Она должна была убрать головную боль и сделать лайнер 737 МАХ похожим в управлении на предыдущие самолеты.
Заодно программа MCAS устраняла недочеты в аэродинамике. Она автоматически предотвращала свойственные лайнеру 737 МАХ попытки самостоятельно задрать нос, когда угол атаки чрезмерно велик. Тем самым устраняется опасность сваливания, вызванная задранным носом.
Гладко было на бумаге, да забыли про овраги
При этом разработчики подчеркивают, что система MCAS не является системой предотвращения сваливания, а нужна для того, чтобы «улучшить горизонтальную стабильность самолета, чтобы он походил в управлении на остальные лайнеры 737-й модели».
Хотя между предыдущим поколением и лайнером 737 МАХ есть значительные отличия, но — благодаря замечательной системе MCAS — пилоты, летавшие на старых Боингах, могли чувствовать себя уверенно. От них требовалось совсем немного: пройти короткий онлайн-курс обучения на флешке — и можно спокойно сесть за штурвал нового самолета.
Так было задумано и допущено к полетам. Но, как говорится, гладко было на бумаге.

— Отличный мозг! Но в чем дело? Почему люди не умеют писать безошибочные алгоритмы?
.
Что получилось на самом деле
В кабине раздавались новые сигналы тревоги. Командир безуспешно пытался восстановить контроль над самолетом. Надо срочно набирать высоту! Но как?
Когда капитан Яред Гетачу пытался поднять нос Боинга, электронные системы опускали его обратно.
Просто тянуть штурвал на себя оказалось недостаточно. Он щелкнул переключателем на штурвале — это должно было восстановить аэродинамический баланс самолета и направить его вверх. Увы, спустя несколько секунд переключатель автоматически вернулся в исходное положение.
Штурвал затрясся — механическое предупреждение о том, что ситуация становится угрожающей: самолет опасно близок к сваливанию. Звуковая сигнализация продолжала трезвонить о потере высоты.
Пилоты отключили часть электронных систем и стали управлять самолетом вручную. Но контролировать самолет становилось все труднее. К этому моменту он набрал скорость. Аэродинамические силы, удерживающие его в воздухе, стали настолько велики, что противиться им с помощью ручного управления стало невозможно.
Игра со смертью в кабине Боинга
Пилоты снова включили электронику, и капитан вновь попытался поднять нос Боинга с помощью переключателя на штурвале. На какое-то время это помогло: самолет вновь начал набирать высоту.
Но затем набор высоты прекратился — снова вмешались компьютеры, которые упрямо гнули свое. Новое предупреждение извещало о том, что самолет движется со слишком большой скоростью — он начал пикировать к земле.
В отчаянии капитан Гетачу обратился к помощнику, и они вдвоем налегли на штурвалы в надежде выровнять самолет силой собственных мускулов.
Но и эта последняя попытка не удалась. Самолет продолжал набирать скорость, пикируя все круче, пока не врезался в землю на скорости более 800 километров в час. Всего через шесть минут после взлета.
На те же грабли
Пятью месяцами ранее такой же Боинг 737 MAX индонезийской компании Lion Air вылетел обычным рейсом из Джакарты. Полет в город на западе Индонезии должен был занять около часа. Но спустя несколько минут после взлета пилоты оказались в похожей ситуации.
Самолет, казалось, жил своей жизнью, норовя снизиться, несмотря на усилия пилотов заставить его набрать высоту. Они не понимали, что происходит. Каждый раз, когда они поднимали нос самолета вверх, спустя несколько секунд автоматика упорно толкала его вниз.
Проблемы с управлением летающего дьявола
Это произошло более 20 раз подряд. На земле диспетчеры забеспокоились, глядя на экраны радаров — Боинг явно терял высоту. Один из пилотов сообщил, что у них возникли проблемы с управлением.
Пытаясь разобраться, экипаж растерялся еще больше — приборы командира и второго пилота показывали разную высоту полета. Пилоты не знали точно, на какой высоте они летят и с какой скоростью.
В конце концов, они полностью потеряли контроль над самолетом. Он вошел в крутое пике и на большой скорости врезался в воды Яванского моря.
Серьезный просчет руководства фирмы Боинг и FAA в области безопасности полетов
Потеря двух новых самолетов, трагическая гибель свыше 300 человек, запрет на продолжение полетов и отказ ряда авиакомпаний от закупок новых самолетов 737 МАХ явились тяжелым ударом для Боинга.
Одновременно это выявило упущения в работе Федеральной авиационной администрации США — Federal Aviation Administration (FAA), которая отвечает за безопасность и сертификацию самолетов и летчиков.
Почему вопиющие ошибки в области безопасности самолетов и подготовки пилотов остались незамеченными? Было начато расследование в конгрессе США, ФБР и других инстанциях.
Сенатор Блюменталь: «Они находились в летающих гробах»
На слушаниях в конгрессе расчеты фирмы Боинг и ее руководителя Денниса Мюленбурга подверглись яростной критике.
Сенатор Ричард Блюменталь заявил:
«У этих пилотов не было шансов. У этих кем-то любимых людей не было шансов. Они находились в летающих гробах».
Здесь я должен прервать рассказ и вернуться к теме.
Нас интересует проблема алгоритмов. Какую роль сыграли алгоритмы в трагедии лайнера 737 МAX?
Причина авиационного инцидента связана с низким качеством и неполнотой алгоритмов и жизнеритмов.
Алгоритмы на скамье подсудимых. На руках разработчиков алгоритмов кровь сотен людей
Применительно к лайнеру 737 МАХ слово «жизнеритм» можно трактовать как бизнес-процесс. Имеются в виду бизнес-процессы в широком смысле слова, описывающие функционирование не только коммерческих фирм, но и государственных учреждений (FAA), а также взаимодействие между ними.
При традиционном подходе алгоритмическая часть бизнес-процесса зачастую описывается не строго и эргономически не удовлетворительно.
В случае с лайнером 737 МАХ анализ алгоритмов и жизнеритмов не позволил выявить погрешности проектирования и своевременно устранить их. Не позволил предотвратить беду и спасти людей.
Алгоритмы и жизнеритмы
Алгоритмы и жизнеритмы — абстрактные понятия. Однако они должны быть четко описаны и представлены в строгой удобочитаемой форме. Они должны быть пригодны для быстрого чтения и понимания. Если это не так, появляются разночтения и взаимное непонимание — предвестники беды.
Иными словами, все алгоритмические подробности и оттенки алгоритмов и жизнеритмов должны быть тщательно проработаны и аккуратно изложены. Потому что от точности и эргономичности описаний и моделей может зависеть жизнь людей.
Кризис самолета 737 МАХ или кризис понятия «алгоритм»
Алгоритмы находятся внутри компьютеров и выполняются автоматически. Жизнеритмы описывают поведение людей в разнообразных бизнес-процессах. Нужно иметь и то, и другое. Необходимо тщательно сопрягать алгоритмы и жизнеритмы.
При создании и эксплуатации самолета 737 МАХ понятие «жизнеритмы» охватывает следующую группу процессов:
— внутренние бизнес-процессы фирмы Боинг, описывающие взаимодействие работников различных отделов и подразделений фирмы друг с другом;
— бизнес-процессы, регламентирующие взаимодействие сотрудников фирмы Боинг и Федеральной авиационной администрации FAA;
— бизнес-процессы, описывающие взаимодействие сотрудников Боинга с авиакомпаниями и другими контрагентами;
— бизнес-процессы, регламентирующие обучение и сертификацию пилотов самолета 737 МАХ, в том числе, в критических и нештатных ситуациях полета.
Жесткое требование
Анализ алгоритмов и жизнеритмов должен показывать реальное состояние дел и демонстрировать упущения, ошибки и слабые места.
Это очень жесткое требование. Двойная авария лайнера 737 МАХ показала, что данное требование не выполняется. Алгоритмы и жизнеритмы не позволили заблаговременно выявить и устранить недостатки, допущенные при разработке и эксплуатации самолета 737 МАХ.
Почему? Может быть, понятие алгоритма нуждается в уточнении?

Анализ понятия «алгоритм»
Уже говорилось, что понятие алгоритма, его свойства и нотации создавалось без оглядки на проблему ошибок. Между тем ошибки, упущения и слабые места во многих случаях являются постоянным спутником сложных алгоритмов и сложных программных комплексов. Однако увидеть, обнаружить и заблаговременно исправить подобные недостатки трудно, что ведет к лишним издержкам.
Ошибочные алгоритмы никому не нужны. Алгоритм с ошибкой — это не алгоритм.
Актуальной задачей является уточнение понятия «алгоритм» исходя из требования безошибочности. Это требование относится не только к одиночным алгоритмам, но и к алгоритмическим системам, содержащим сотни и тысячи взаимодействующих алгоритмов.
Входит ли нотация в понятие алгоритма
Алгоритм — сложное понятие, в котором можно выделить:
— определение алгоритма (интуитивное и формальное);
— свойства алгоритма;
— нотации, т. е. способы записи алгоритма.
До сих пор свойства и нотации алгоритма рассматривались и изучались в отрыве от потребностей практики, которая заинтересована в сокращении числа ошибок. Это имело негативные последствия.
Недооценка проблемы безопасности открыла путь к использованию нежелательных методов разработки алгоритмов — небезопасных методов, порождающих ошибки. Такое положение следует признать неприемлемым.
Комплексная программа уменьшения числа ошибок
Наряду с устоявшимся понятием «алгоритм» целесообразно ввести понятие «безошибочный алгоритм». Речь идет не просто о термине, а о нацеленной в будущее комплексной программе значительного сокращения ошибок в алгоритмах за счет использования новых (когнитивно-эргономических и формальных) методов. Программа называется «подавление ошибок» и здесь не описана.
«Нет-нет-нет, мы хотим сегодня! Нет-нет-нет, мы хотим сейчас!». Я понимаю, но статья имеет пределы.
Свойства и нотация безошибочных алгоритмов
Свойства и нотация безошибочных алгоритмов должны:
— оцениваться с учетом требования безошибочности, которое следует считать приоритетным;
— тщательно выбирать и рекомендовать такой способ записи алгоритма, который предотвращает ошибки;
— запрещать способы записи, содействующие появлению ошибок (или присваивать им низкую оценку).
Создание безошибочных алгоритмов следует начинать с разработки эргономичной нотации, которая способна предотвращать ошибки.
Повторю все ту же мантру безошибочности. В новую нотацию нужно встроить незаметный для пользователей математический аппарат, предотвращающий ошибки.
Понятность и понимаемость безошибочного алгоритма
Следует различать два свойства алгоритма: понятность и понимаемость. Свойство «понятность» говорит о том, что алгоритм должен быть понятен компьютеру, т. е. состоять из инструкций, входящих в его систему команд. Это разумное и очевидное свойство алгоритма.
К сожалению, при этом зачастую выпадает из поля зрения не менее важное свойство «понимаемость алгоритма» для человека. Имеется в виду человек, который читает или изучает алгоритм с целью выявления ошибок, упущений, слабых мест и иных недостатков.
Такая проверка может проводиться в любое время в процессе жизненного цикла алгоритма. Проверку могут проводить разные люди: автор алгоритма, его руководитель, заказчик, специалисты по сопровождению (эксплуатации) алгоритма и др.
Понимаемость (understandability) алгоритма для человека (в отличие от понятности для компьютера) означает удобочитаемость, то есть ясность, доходчивость, пригодность алгоритма для быстрого и легкого понимания и выявления ошибок.
Зачем нужна понимаемость
Понимаемость есть совокупность свойств алгоритма, характеризующая затраты усилий пользователя на понимание логической концепции этого алгоритма (ГОСТ 28806-90).
Чтобы облегчить выявление ошибок при зрительной проверке за столом, указанные затраты должны быть минимальными.
Отсюда следует, что понимаемость есть свойство алгоритма минимизировать интеллектуальные усилия, необходимые для его понимания при зрительном восприятии алгоритма человеком. Понимаемость необходима при создании безошибочных алгоритмов.
Если бы алгоритмы и жизнеритмы (бизнес-процессы) фирмы Боинг и FAA обладали надлежащим качеством и свойством «понимаемость», то ошибки, упущения и слабые места в самолете 737 МАХ были бы своевременно выявлены и устранены, катастрофа не произошла бы, а пассажиры и экипажи остались бы живы.

Задачи становятся все сложнее.
Их все труднее понять. Понимание — это труд. Производительность этого труда недопустимо мала.
Необходимы новые: когитивнно-эргономические и формальные методы, чтобы облегчить понимание.
.
Дискуссия о понимании алгоритмов
— Можно ли читать алгоритмы, как увлекательную повесть, быстро и с удовольствием?
— Нет, нельзя.
— Как сделать алгоритмы легкими и удобными для изучения?
— Увы, это невозможно.
— Почему?
— Потому что алгоритмы очень трудны и предназначены для вдумчивого, серьезного, медленного чтения, обеспечивающего глубокое понимание.
— Все это так, но жизнь идет вперед и ставит новые задачи. То, что вчера было невозможно, завтра станет возможным. Жизнь требует, чтобы сложные алгоритмы стали удобными для людей — дружелюбными, понятными, доходчивыми (people-friendly, user-friendly). Алгоритмы должны быть легкими для быстрого восприятия и усвоения, пригодными для быстрого выявления ошибок.
Почему алгоритмы трудны для понимания
Низкая понимаемость алгоритмов и программ — важный недостаток современного программирования.
Джозеф Фокс, руководитель отделения федеральных систем IBM, у которого в подчинении было 4400 человек, объясняет, в чем дело:
«Некий превосходный программист спроектировал и написал программу определения орбитальных характеристик искусственного спутника Земли. Он первым закончил программирование, все работало правильно, память попусту не тратилась. Программа была написана на языке Фортран и занимала около четырех страниц плотного фортрановского текста. Он знал свою программу вдоль и поперек.
«Через три месяца его попросили добавить к программе несколько новых функций. Он достал документацию (описание программы) и принялся ее изучать. Три или четыре дня он пытался понять, что же происходит в его программе. А ведь он ее сам написал! Сколько бы сил он потратил, если бы это была чужая программа!».
Разве можно с этим мириться?
Эта удивительная история подтверждает простую истину: алгоритм вещь сложная и понять его непросто. Оказывается, даже сам автор программы спустя три месяца не сумел расшифровать свой собственный алгоритм.
Чтобы прочитать всего четыре страницы и докопаться до истины, превосходному программисту пришлось изрядно помучиться. И потратить три или четыре дня.
Отсюда следует неутешительный вывод.
Глядя на исходный текст программы, понять сложный алгоритм очень трудно. А быстро понять — невозможно.
Разве это хорошо? Разве можно с этим мириться?
Метод проб и ошибок: чему учит история авиации
История авиации — это история замечательных достижений и одновременно история катастроф и человеческих трагедий.
Анализируя неудачу лайнера 737 МАХ, можно указать два варианта развития событий:
— традиционный подход к исследованию причин катастроф и аварий и исправлению недостатков;
— принципиально новый подход к безошибочности, опирающийся на Комплексную программу уменьшения числа ошибок.
Первый вариант ведет к успеху методом проб и ошибок, где проба — это очередная катастрофа, причем платить приходится жизнями людей.
Второй вариант нацелен на поиск более рационального решения. При этом важную роль играет новая нотация, специально предназначенная для создания безошибочных алгоритмов.
Не забудьте про мантру безошибочности.
Нотация безошибочного алгоритма
Нотация алгоритма — это система обозначений, позволяющая записать, прочитать и понять алгоритм.
Кому интересно, можно полистать мою книгу «Учись писать, читать и понимать алгоритмы. Алгоритмы для правильного мышления».
При обычном подходе к выбору нотации требование об отсутствии ошибок не ставится и не рассматривается. Такой подход уязвим для критики, ибо позволяет использовать для записи алгоритмов любую подходящую нотацию, например:
— естественный язык (включая словесно-формульную запись);
— псевдокод;
— язык программирования;
— блок-схему согласно ГОСТ 19.701-90 (ISO 5807-85);
— схему деятельности (activity diagram) языка UML;
— диаграмму Несси-Шнейдермана и т. д.
Все нотации не годятся
Все нотации из этого списка имеют существенные недостатки. Они не обладают свойством эргономичности и не могут использоваться для безошибочных алгоритмов.
Новый способ записи должен быть эргономичным и значительно более эффективным. Новая нотация способна обеспечить почти полное отсутствие ошибок. При этом используется батарея новых методов подавления ошибок, которая здесь не описана.

— Что делает этот чудак?
— Изобретает новую нотацию.
.
Когнитивно-эргономический подход
Цель — облегчить и ускорить понимание алгоритмов и выявление ошибок.
Для этого необходимо устранить или ослабить когнитивные затруднения, то-есть трудности понимания алгоритмов.
Когнитивно-эргономический подход — это рабочий метод, дающий полезные плоды — улучшение понимаемости алгоритмов и программ, предотвращение многих ошибок, повышение производительности сложного интеллектуального труда.
Не надо путать. Когнитивно-эргономический подход и синтаксический сахар — разные вещи.

Можно ли создать алгоритмический язык, способный предотвращать ошибки
Показано, что заданным требованиям удовлетворяет визуальный алгоритмический язык ДРАКОН.
На Хабре: Визуальное программирование на языке ДРАКОН.
В Википедии: ДРАКОН.
In Wikipedia: DRAKON.
Книга: Алгоритмы и жизнеритмы на языке ДРАКОН. Разработка алгоритмов. Безошибочные алгоритмы.
Как и все прочие языки, ДРАКОН опирается на математику и логику. Однако сверх того, он самым тщательным образом учитывает когнитивные вопросы. Благодаря систематическому использованию когнитивно-эргономических методов ДРАКОН приобрел уникальные эргономические характеристики.
В будущем он сможет претендовать на звание чемпиона по критерию «понимаемость алгоритмов и программ» (в классе императивных языков).
Язык ДРАКОН. Алгоритмическая макроконструкция «силуэт»
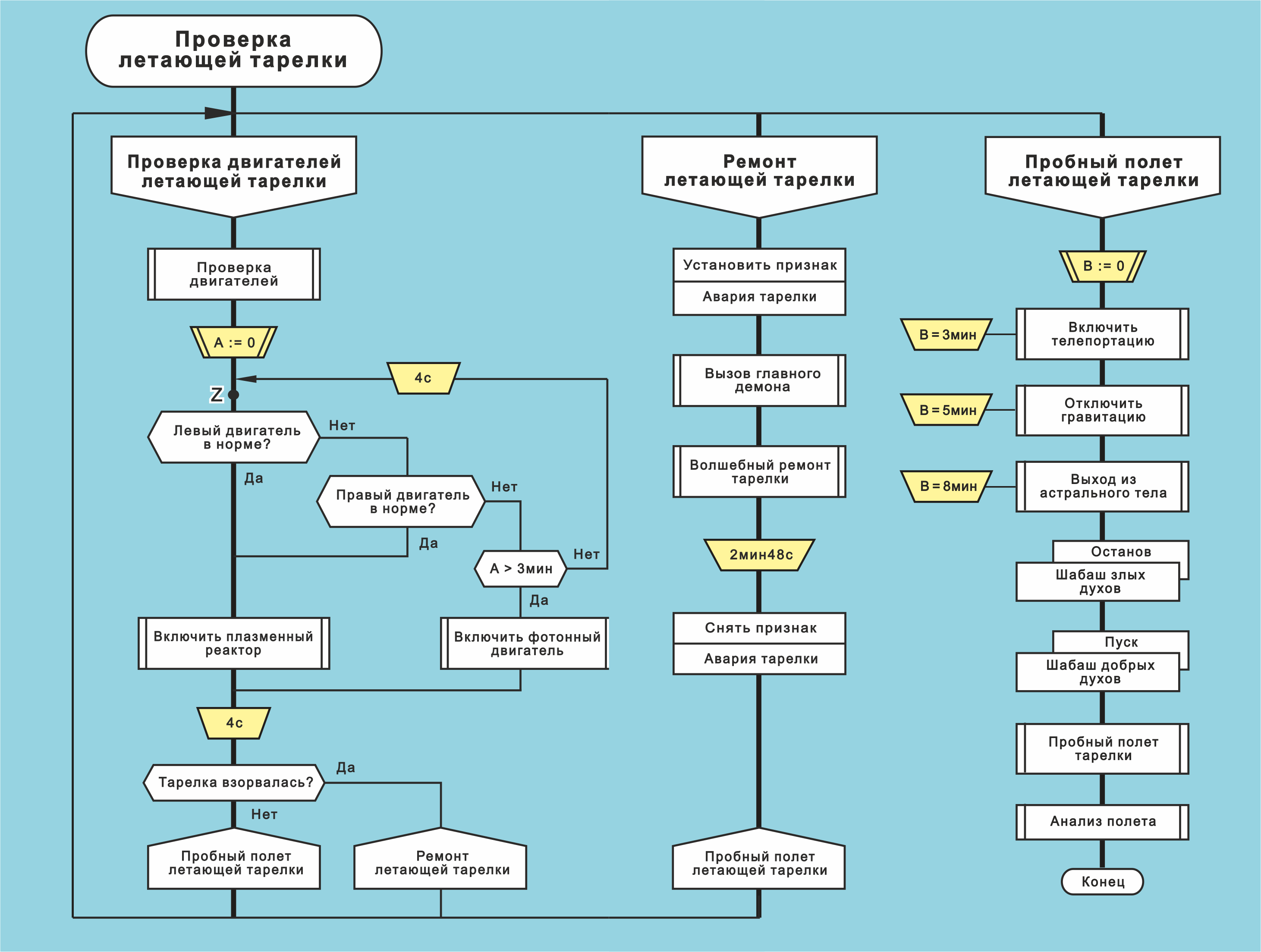
Рис. 1. Алгоритм «Проверка летающей тарелки»
Язык ДРАКОН. Алгоритмическая макроконструкция «примитив»
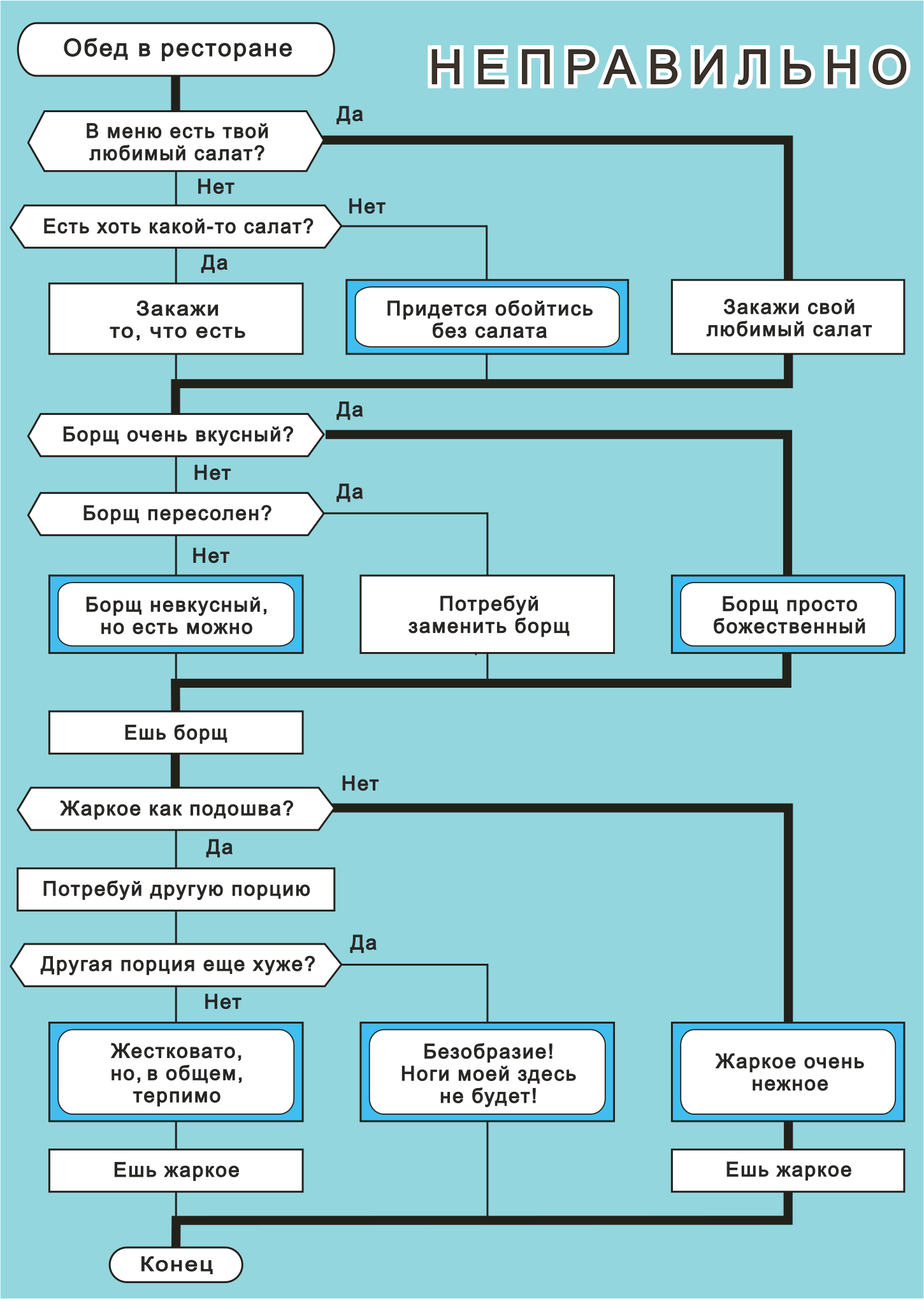
Рис. 2. Плохой дракон-алгоритм.
а) Нарушено правило «Чем правее, тем хуже».
б) Нарушенр правило: «Главный маршрут должен идти по шампуру».
Главный маршрут (жирная линия) все время петляет и делает зигзаги.
Его трудно проследить взглядом.
Главный маршрут — это царская дорога (happy path). Это наиболее благоприятный маршрут алгоритма.
.

Рис. 3. Хороший дракон-алгоритм.
Он получен в результате улучшения схемы на рис. 2 с помощью операции «рокировка».
а) Выполняется правило «Чем правее, тем хуже».
б) Главный маршрут прямой как стрела. Он идет по шампуру.
.
Предшественники: Эдсгер Дейкстра, Бертран Мейер, Игорь Вельбицкий
Потенциально опасные текстовые средства потока управления можно заменить на безопасные визуальные средства управления.
Начнем с истории. В 1968 году Эдсгер Дейкстра в журнале «Communications of the ACM» указал, что оператор goto, используемый во многих языках программирования высокого уровня, является основным источником ошибок и потому должен быть запрещен.
Затем Бертран Мейер выявил еще два опасных элемента — операторы break и continue, который также следует запретить как замаскированные goto. По словам Мейера, это те же старые «goto в овечьей шкуре».
Еще дальше идет Игорь Вельбицкий, который считает, что из программирования следует исключить:
«ключевые слова-паразиты и соответствующие им конструкции языков типа: goto, if, for, while, break, begin-end, {-} и т. д… Эти конструкции являются основным источником ошибок и проблем в современном программировании».
Язык ДРАКОН продолжает и развивает традицию, начатую Дейкстрой и продолженную Вельбицким и Мейером. Традицию, направленную на выявление и изгнание потенциально опасных операторов управления, которые могут послужить причиной ошибок.
В чем идея
Идея проста и сводится к двум положениям:
— надо выявить потенциально опасные служебные слова, логические скобки и знаки пунктуации, используемые в операторах управления, и запретить их;
— вместо них следует использовать безопасную графику.

Визуальное (двумерное) структурное программирование
Приведем список исключенных из языка ДРАКОН опасных элементов, обеспечивающих управление вычислительным процессом. Сюда относятся:
— служебные слова goto, break, continue, if, then, else, case, of, switch, while, do, repeat, until, for, foreach, loop, exit, when, last и их аналоги;
— логические скобки begin end, { };
— знаки пунктуации: круглые скобки, квадратные скобки, косые скобки, двоеточие, точка с запятой.
Все они подлежат замене на математически строгую графику управления. Графика реализует ту же самую функцию, что и забракованные элементы.
Замена текстовых операторов на их точные графические эквиваленты означает, что язык ДРАКОН использует двумерное (2d) структурное программирование. Последнее можно рассматривать как дальнейшее развитие одномерного (1d) структурного программирования, которое создали Эдсгер Дейкстра, Тони Хоар, Оле-Йохан Дал и др.
«Чем вам ключевые слова, логические скобки и знаки пунктуации помешали?»
Правило Эшфорда гласит:
«Бесполезно стремиться направить внимание на важнейшие характеристики, если они окружены лишними, не относящимися к ним визуальными раздражителями, мешающими восприятию главного».
Опасный катализатор ошибок
Отрицательную роль перечисленных текстовых операторов управления можно охарактеризовать как «опасный катализатор ошибок», ибо они:
— отвлекают внимание программиста, затрудняют понимание смысла программы, делают работу программиста трудной;
— засоряют визуальную картину программы, создают визуальные помехи, фактически являясь ненужными, паразитными элементами, без которых можно обойтись;
— с неумолимой неизбежностью провоцируют появление ошибок.
Впрочем, указанные текстовые операторы никуда не исчезают и продолжают тянуть свою лямку как рабочие лошадки. Просто человек их не видит и не пишет. И не смотрит на них, как мы не смотрим на исполняемый код после компиляции.
Человек рисует графические операторы управления (дракон-схемы похожи на блок-схемы) и работает с ними.
Какова цель
Цель заключается в том, чтобы улучшить способность языков проектирования и программирования предупреждать появление ошибок.
Нужно существенно увеличить надежность программно-математического обеспечения. Ниже показано, что операторы, провоцирующие ошибки, можно обезопасить.
Сравнение текста и графики для оператора while

Слева имеются паразитные элементы (while и две скобки). Справа их нет

Рис. 4. Оператор while можно удалить и заменить на управляющую графику языка ДРАКОН
В си-программе на рис. 4 имеются избыточные элементы, которые можно изъять с целью улучшения исходного кода программы. Вот они:
— while;
— две круглые скобки;
— две фигурные скобки.
Си-оператор на рис. 4 слева содержит загромождающие паразитные элементы, отсутствующие в дракон-операторе справа. Следствием является неоправданное усложнение си-оператора, которое засоряет программу и отвлекает внимание программиста.
В дракон-программе избыточные (паразитные) знаки не нужны. Вместо них используются линии формального чертежа. Эргономичный чертеж гораздо лучше, чем текст, показывает маршруты алгоритма, а также петлю обратной связи и тело цикла.
Катализатор ошибок. Анализ операторов switch, case, break

Рис. 5. Оператор switch, case, break можно удалить и заменить на управляющую графику ДРАКОНа
На рис. 5 слева показана си-программа с операторами switch, case, break, а справа — эквивалентная дракон-программа. В си-программе используется большое количество ненужных ключевых слов и знаков пунктуации:
— switch,
— case (два раза),
— break (два раза),
— две фигурные скобки,
— две круглые скобки,
— три двоеточия,
— пять точек с запятой.
Указанные слова и знаки для языка Си являются обязательными элементами исходного текста программы. Обойтись без них невозможно, они должны соответствовать формальным правилам синтаксиса языка Си, которые проверяются при компиляции в ходе лексического и синтаксического анализа.
С точки зрения языка ДРАКОН, дело обстоит принципиально по-другому. То, что важно и необходимо для Си, язык ДРАКОН рассматривает как лексический и синтаксический мусор, как слова-пустышки и знаки-паразиты, как бессмысленные, ненужные и вредные элементы, которые подлежат изъятию и удалению. Потому что они являются катализаторами ошибок.
Расчет
Приведем количественный расчет. В си-программе на рис. 5 использовано 55 символов (characters) без пробелов, а в дракон-программе всего 19, т. е. в 2,9 раза меньше. Благодаря графике дракон-программа легче для восприятия, в ней проще разобраться и заметить ошибку.
Дополнительное удобство для чтения программного кода связано с тем, что размещение символов в пространстве подчиняется строгим правилам эргономичной декомпозиции и правилам отделения фигуры от фона.

Мышление пора менять
ДРАКОН должен удовлетворять требованию безошибочности алгоритмов. Такое требование предъявляется к языку впервые. Оно символизирует принципиально новый подход к разработке алгоритмического языка.
Требование не выполняется, но стимулирует изменение мышления.
Впрочем, почему не выполняется? Вот народные отзывы из сети:
Участник vtral:
Язык Дракон — это способ визуального описания алгоритмов, исключающий ошибки.
Сергей Иголкин (Orthodox):
Дракон, на самом деле — чертовски хорош.
Не тем, что красивые диаграммки. Или охрененные разнообразные возможности (хотя хватает).
А тем, что главную свою цель обеспечивает — сложные алгоритмы писать и отлаживать без ошибок.
Индивидуальный предприниматель Сергей Ефанов:
Переписал на ДРАКОНе довольно запутанную функцию из реального проекта.
Функция заработала сразу!
Более того, при переносе алгоритма в дракон-схему, я обнаружил, что у меня в ней была ошибка! Эта функция работала уже довольно давно, не в одной сотне изделий. Ошибка не была фатальной, она возникала редко, и компенсировалась переподключением к серверу. Но она была!
В тексте на Си ее было незаметно. А при попытке перенести алгоритм на дракон-схему, ошибка стала не просто заметной — алгоритм в этом месте «не вырисовывался»!
Что значит «алгоритм не вырисовывался»?
Это значит, что ДРАКОН срывает с ошибки шапку-невидимку и делает ее видимой. Ошибка как бы выпрыгивает из чертежа, бьет разработчика кулаком в нос и громовым голосом кричит: «Вот она я! Заметь меня!».
Больше того, умная программа ДРАКОН-конструктор (интеллектуальный графический редактор) во многих случаях не дает человеку ошибиться. Физически не позволяет.
Каким образом? В программу заложены правила рисования дракон-алгоритмов (визуальное логическое исчисление), которые она строго соблюдает. Отступление от правил невозможно. Если человек попытается нарушить правила и совершить ошибку, ДРАКОН-конструктор откажется повиноваться и не станет рисовать глупости.
Именно это означает фраза Сергея Ефанова «алгоритм не вырисовывался».
Это пример того, как работает мантра безошибочности.
Дракон-схемы и блок-схемы
Чем отличаются дракон-схемы от блок-схем? Это все равно, что спросить: «Чем отличается человек от обезьяны».
Чтобы не тратить много слов, приведу два отзыва из сети.
Роман Озеров: «Я на ДРАКОНе работаю уже 6 лет. Любое создание программы начинаю с него и при отладке работаю только с ним.
Скорость разработки, качество возрастает в разы!
ДРАКОН это сила, но многие не догоняют, думают, что это обычная блок-схема».
Участник dvuugl: Если нужно рисовать алгоритм, теперь только и только на Драконе. Считаю, что он должен стать государственным стандартом для блок-схем вместо существующего.
Удивительно, что авторы книг продолжают использовать прежние схемы, на которые после Дракона без ужаса смотреть невозможно».

Специальный математический аппарат: визуальный аксиоматический метод (визуальная формальная система)
Мантра безошибочности включает специальный математический аппарат — логическое исчисление. Особенность в том, что это визуальное логическое исчисление.
В языке ДРАКОН есть две визуальных аксиомы:
— аксиома-силуэт,
— аксиома-примитив.
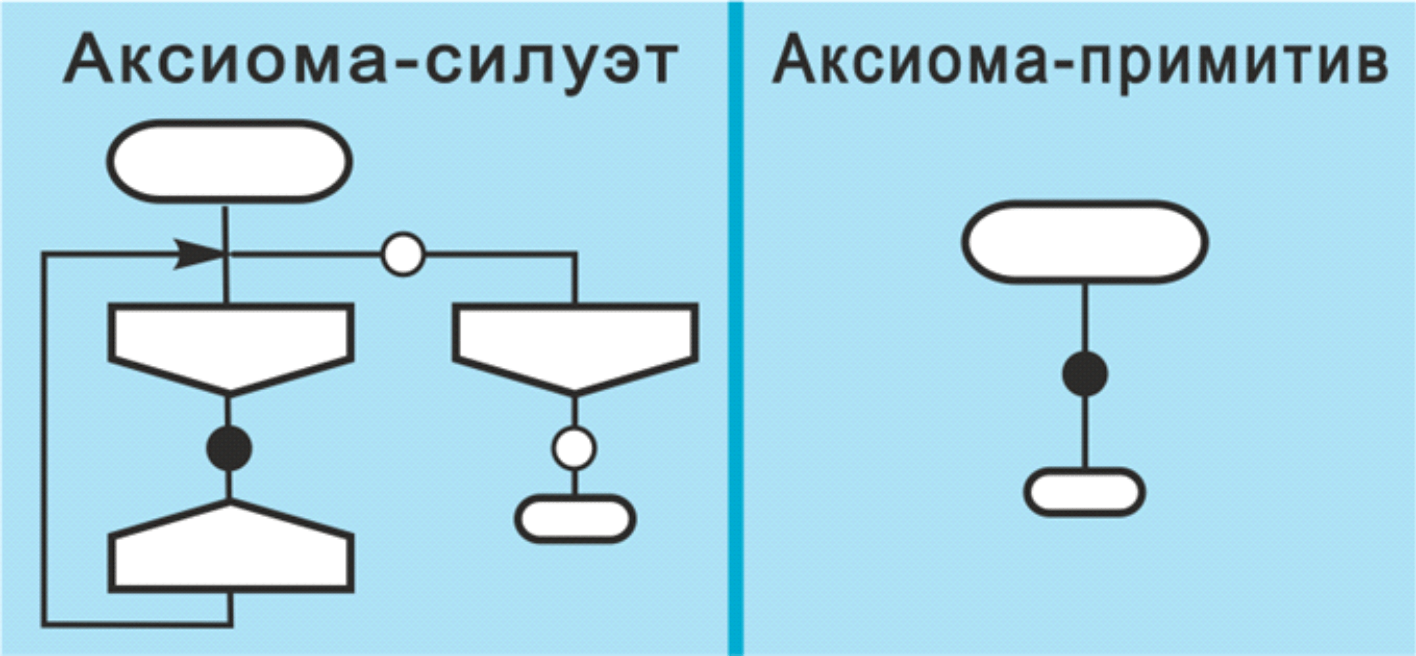
Рис. 6. Аксиома-силуэт и аксиома-примитив служат заготовками для построения силуэта и примитива соответственно.
Кружками показаны валентные точки.
.
Любой дракон-алгоритм силуэт (см. рис. 1) логически выводится из аксиомы-силуэт с помощью правил вывода (визуального логического вывода).
Любой дракон-алгоритм примитив (см. рис. 3) логически выводится из аксиомы-примитив точно так же — с помощью визуального логического вывода.
Что значит «выводится»? Это значит, что графика макроконструкций силуэт и примитив является визуальной теоремой. Доказанной теоремой. Ее не надо доказывать, так как она уже доказана в силу свойств логического исчисления.
Данное исчисление называется «исчислением икон».
Причем здесь аксиоматический метод?
Ответ под спойлером:
Spoiler
Ершов Ю.Л., Палютин Е.А. Математическая логика. —
М.: Наука, 1079. — 320 с. — С.12, 13.Основным итогом деятельности в области оснований математики можно считать становление математической логики как самостоятельной математической дисциплины, а принципиальным достижением математической логики — разработку современного аксиоматического метода, который может быть охарактеризован следующими тремя чертами:
1. Явная формулировка исходных положений (аксиом) той или иной теории.
2. Явная формулировка логических средств (правил вывода), которые допускаются для последовательного построения (развертывания) этой теории.
3. Использование искусственно построенных формальных языков для изложения всех положений (теорем) рассматриваемой теории…Введение и использование подходящих обозначений было на протяжении всей истории математики весьма важной и продуктвной процедурой…
Основным объектом изучения в математической логике являются различные исчисления.
В понятие исчисления входят такие основные компоненты, как:
а) язык (формальный) исчисления;
б) аксиомы исчисления;
в) правила вывода…Еще одним замечательным достижением математической логики является нахождение математического определения понятию алгоритма…
Изучение исчислений составляет синтаксическую часть математической логики…
Наряду с синтаксическим изучением исчислений проводится также семантическое изучение формальных языков математической логики.
Основным понятием семантики является понятие истинности для выражений (формул, секвенций и т. п.) формального языка.
Валентные точки языка ДРАКОН
«Основной недостаток блок-схем заключается в том, что они не приучают к аккуратности при разработке алгоритма. Ромб можно поставить в любом месте блок-схемы, а от него повести выходы на какие угодно участки.
Так можно быстро превратить программу в запутанный лабиринт, разобраться в котором через некоторое время не сможет даже сам ее автор».
В языке ДРАКОН подобные чудеса невозможны, в частности, благодаря институту валентных точек. Последние служат для предотвращения ошибок.

Рис. 7. На анимации валентные точки показаны желтыми кружками.
Иконы и макроиконы можно вводить только в валентные точки и больше никуда.
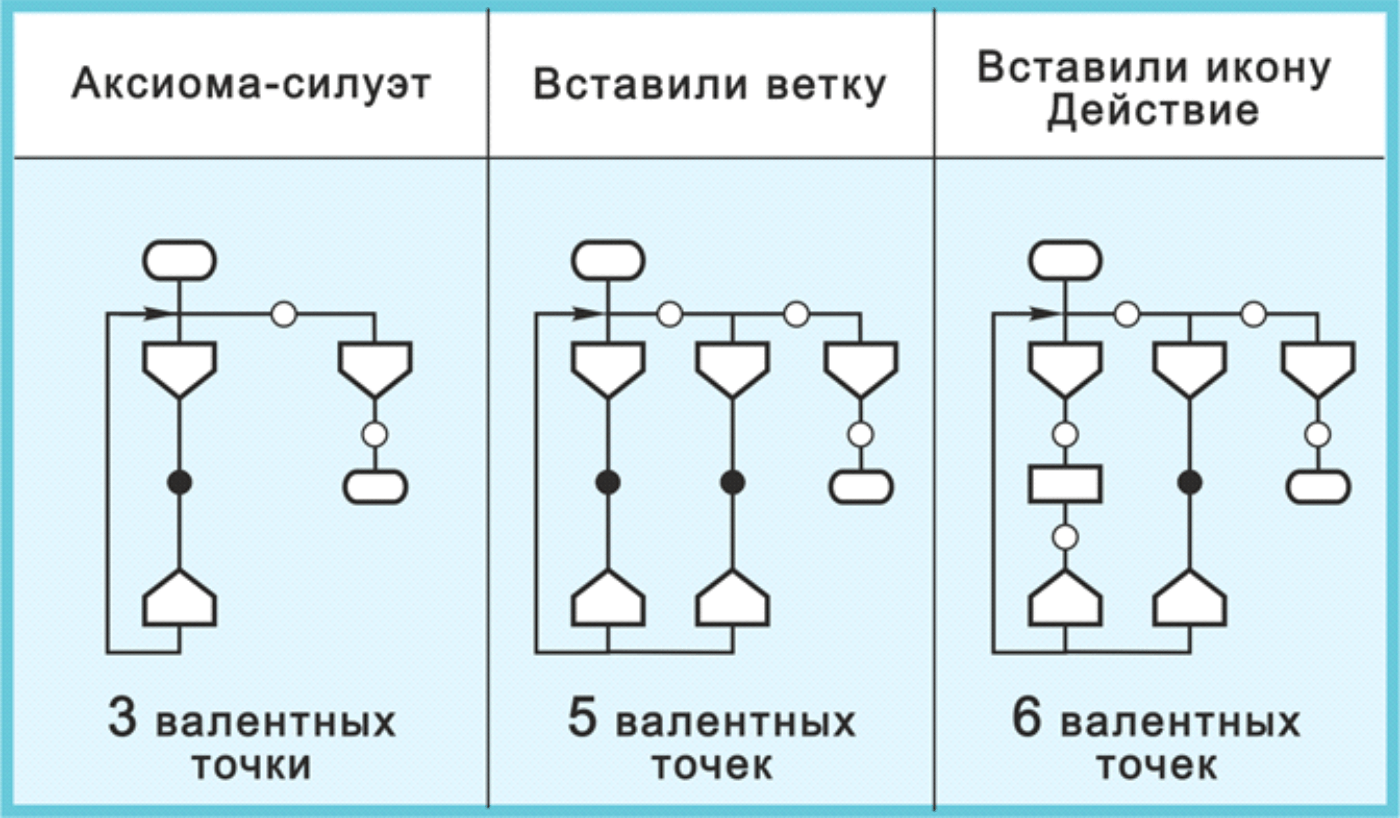
Рис. 8. Размножение валентных точек при проектировании дракон-алгоритма
Формализация точек размещения икон
Валентные точки можно рассматривать как точки размещения икон, или точки ввода икон.
На каждом шаге построения алгоритма происходит размножение валентных точек. Процесс размножения показан на рис. 8.
В аксиоме-силуэт всего 3 валентных точки. После добавления конструкции «Ветка» будет уже 5 точек. А после вставки иконы Действие число точек увеличивается до 6 (рис. 8). Дальнейший процесс построения силуэта приводит к монотонному росту числа валентных точек.
Это значит, что иконы можно вставлять не куда угодно, а только в строго определенные места. Для каждой валентной точки определен список икон, которые разрешается вставить в данную конкретную точку.
Ввод иконы производится так. Сначала происходит разрыв соединительной линии в выбранной пользователем валентной точке. Затем в место разрыва вставляется икона.
Все списки (списки валентных точек и списки разрешенных икон) хранятся в памяти прораммы ДРАКОН-конструктор, который осуществляет визуальный логический вывод. Таким образом, описанная операция строго формализована и защищена от многих ошибок.
Математический чертеж дракон-алгоритма
Математический чертеж алгоритма — это чертеж, для которого определены:
— формальное описание алфавита графических фигур (икон и макроикон), причем иконы заданы вместе с отростками, что исключает неоднозначность;
— формальное описание синтаксиса, то есть соединительных линий между фигурами;
— визуальное логическое исчисление, позволяющее из аксиомы-силуэт и аксиомы-примитив строить формализованный чертеж алгоритма методом логического вывода.
Язык ДРАКОН разработан исходя из этих предпосылок.

Интеллектуальный ДРАКОН-конструктор
Попробуйте бесплатный онлайн ДРАКОН-конструктор DrakonHub. Вот инструкция.
Вы убедитесь, что процесс рисования происходит удобно, легко и с большой скоростью.
Забудьте о линиях! Не царское это дело — рисовать линии
Во избежание ошибок пользователю запрещено рисовать соединительные линии между иконами на дракон-схеме. Потому что он такого нарисует — мама не горюй!
Все соединительные линии автоматически создает интеллектуальная программа ДРАКОН-конструктор.
Почему она интеллектуальная? Потому что использует специальный математический аппарат — визуальное логическое исчисление (исчисление икон).
Как работает ДРАКОН-конструктор
Ответ показан на анимациях (рис. 9 и рис. 10). Слева панель инструментов (toolbar).
Рис. 9 демонстрирует скорость работы. Рис. 10 поясняет, как переделать уже сделанное.
Оба рисунка показывают работу с макроконструкцией примитив. Редактирование силуэта происходит точно так же.
Переход от примитива к силуэту и обратно производится кнопкой на тулбаре внизу справа.

Рис. 9. ДРАКОН-конструктор позволяет создать сложный алгоритм в наглядном виде и очень быстро

Рис. 10. ДРАКОН-конструктор позволяет переделывать алгоритм (удалять, вставлять и переставлять графические фигуры) очень быстро
При этом вообще не надо думать о соединительных линиях между фигурами.
Все проблемы с соедительными линиями ДРАКОН-конструктор решает самостоятельно, автоматически без участия человека.
На анимации видно, что пользователь не провел ни одной соединительной линии! Тем не менее все линии образовались, причем образовались правильно, без ошибок.
Правила ДРАКОНа
Язык ДРАКОН содержит большое число правил. К счастью, их не надо учить и запоминать. Почему? Потому что правила знает назубок, хранит в своей памяти и скрупулезно выполняет программа ДРАКОН-конструктор.
Вот пример. В дракон-схемах запрещено пересечение линий, обрывы линий и внутренние соединители. Запрет выполняется автоматически. Конструктор гарантирует отсутствие пересечений на основе строгой математической теории — исчисления икон.

Визуальная алгоритмическая логика языка ДРАКОН. Математическая логика в алгоритмах. Визуальная алгебра логики
Это большая тема и в рамках статьи изложить ее невозможно. Будут даны лишь самые краткие пояснения.
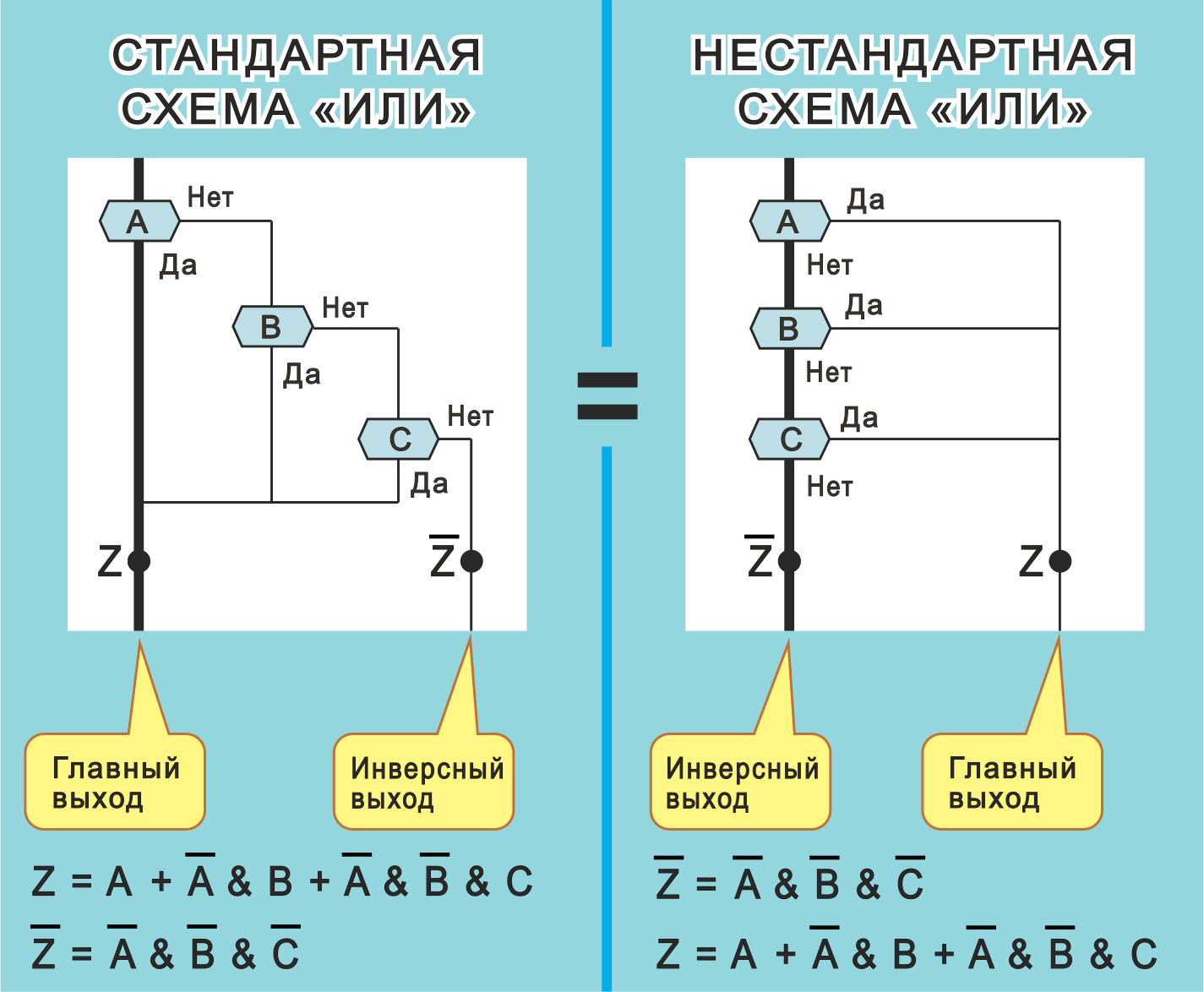
Рис. 11. Стандартный (слева) и нестандартный (справа) алгоритм «ИЛИ»
Классическая (текстовая) и неклассическая (визуальная) алгебра логики
Укажем различие между классическим и неклассическим вариантами алгебры логики (на примере дизъюнкции).
В классическом варианте используется линейная запись логической функции «ИЛИ», которая не показывает свою инверсию и принципиально не может описать инверсный маршрут алгоритма (рис. 11, в самом низу).
В неклассическом случае применяется графическая запись логической функции «ИЛИ» (рис. 11), которая изображает одновременно как главный, так и инверсный выходы.
Зададим вопрос: какой принцип используется для разграничения успеха и неудачи?
Классический вариант использует «принцип отделения единицы (Истина) от нуля (Ложь)». Если функция равна 1 — это хорошо, если равна 0 — плохо.
Неклассический вариант использует «принцип переключателя маршрутов». Если выбран главный выход, это хорошо, если инверсный — плохо.
Стандартный и нестандартный логический алгоритм «ИЛИ»
Стандартный логический алгориитм «ИЛИ» для N логических переменных — это алгоритм, содержащий N икон Вопрос, которые:
— расположены лесенкой;
— в каждой иконе Вопрос содержится одна логическая переменная.
Стандартный алгоритм «ИЛИ» для трех логических переменных представлен на рис. 11, слева.
Нестандартный логический алгоритм «ИЛИ» для N логических переменных — это алгоритм, полученный с помощью рокировки стандартного алгоритма «ИЛИ». На рис. 11 (справа) показан нестандартный алгоритм для случая трех переменных.
Стандартная и нестандартная схемы «ИЛИ» равносильны. Они описывают один и тот же алгоритм.
Четыре маршрута стандартного алгоритма ИЛИ. Формулы маршрутов
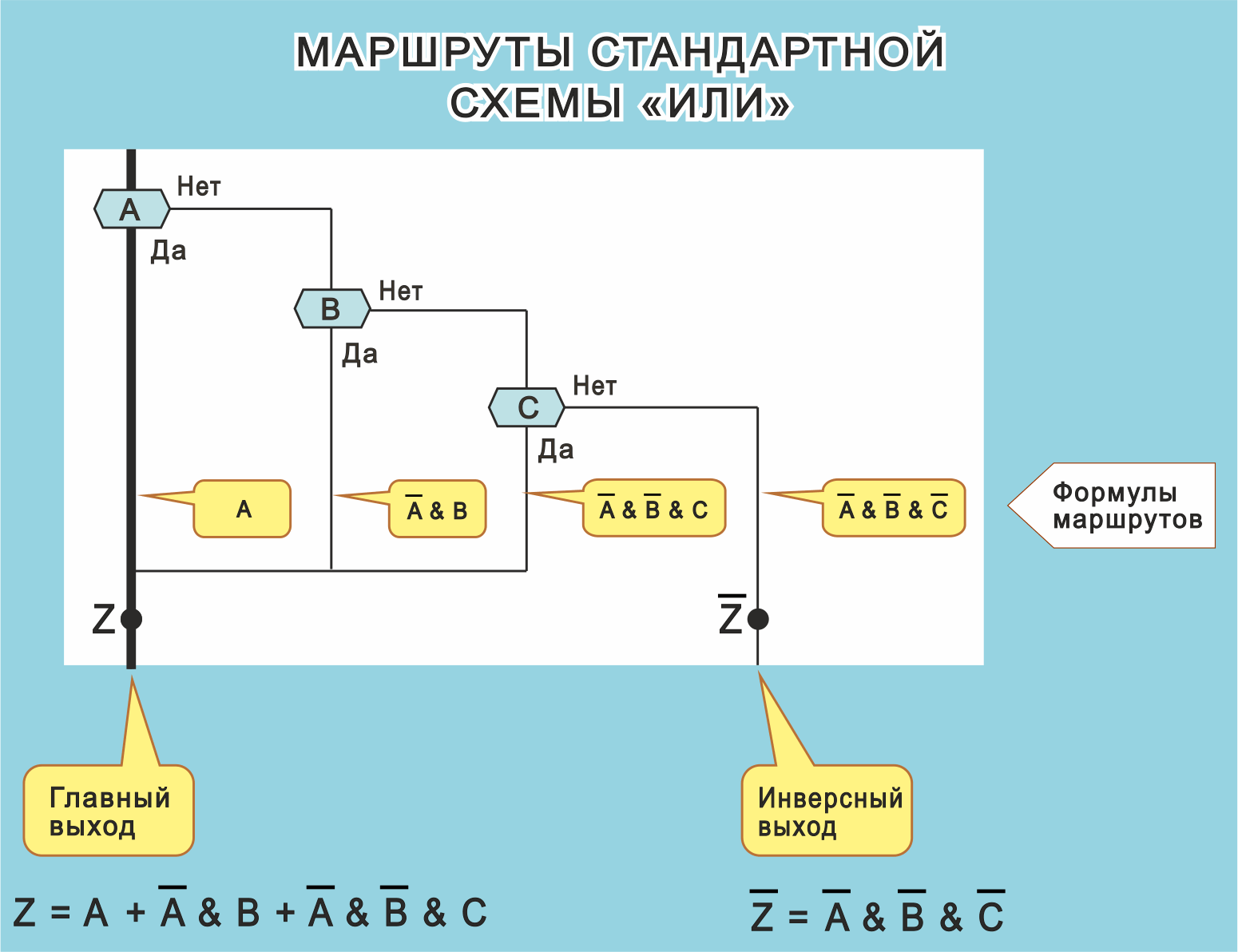
Рис. 12. На схеме «ИЛИ» показаны четыре формулы маршрутов (в четырех желтых выносках). Каждая формула — это конъюнкт.
Алгоритм ИЛИ на рис. 12 имеет четыре маршрута. Для каждого из них можно построить формулу маршрута в виде конъюнкта.
Первый маршрут идет по шампуру и имеет формулу “А да”. Слово «да» означает, что буква А берется без отрицания, как показано в левой выноске.
Второй маршрут идет правее с формулой “A нет B да”. Преобразовав в конъюнкт, получим ¬A & B
Третий маршрут идет еще правее и имеет формулу “A нет B нет С да”. После преобразования в конъюнкт, получим ¬A & ¬B & C
Наконец, четвертый маршрут (крайний справа) имеет формулу “A нет B нет С нет” и превращается в конъюнкт: ¬A & ¬B & ¬C. Последний маршрут задает инверсный выход.
Стандартный и нестандартный логический алгоритм «И»

Рис. 13. Стандартный (слева) и нестандартный (справа) алгоритм «И»
Стандартная логическая схема «И» для N логических переменных — это схема, содержащая N икон Вопрос, которые:
— расположены на одной вертикали;
— в каждой иконе Вопрос содержится одна переменная.
Стандартная схема «И» для трех логических переменных представлена на рис. 13, слева.
Нестандартная логическая схема «И» для N логических переменных — схема, полученная с помощью рокировки стандартной схемы «И».
На рис. 13 (справа) дан пример нестандартной схемы для трех переменных.
Стандартная и нестандартная схемы «И» равносильны. Они описывают один и тот же алгоритм.
Принципиальный дефект (ахиллесова пята) текстового программирования
В текстовом программировании (textual programming)), чтобы правильно выразить логическую мысль, во многих случаях приходится использовать логическое отрицание, которое служит катализатором ошибок. Обойтись без этого приема (без логического отрицания) в текстовом программировании невозможно.
Визуальное программирование на языке ДРАКОН лишено этого недостатка. Чтобы избавиться от логического отрицания, надо (всего лишь!) поменять местами «Да» и «Нет» на выходах иконы Вопрос.
Такой прием называется произвольным расположением «Да» и «Нет» на выходах иконы Вопрос.
Расстановка «Да» и «Нет» на выходах иконы Вопрос в алгоритме «И»
Глядя на рис. 13 (слева), можно заметить, что нижние выходы у трех икон Вопрос помечены словом «Да». Является ли такой подход обязательным? Можно ли изменить расстановку «Да» и «Нет» и поменять их местами?
Да, можно. Чтобы убедиться в этом, на рис. 14 (слева) показан другой вариант — возле иконы B мы изменили расстановку «Да» и «Нет» на противоположную.
На что повлияло такое изменение?
Во-первых, на нестандартную схему «И», где возле иконы В также изменилась расстановка «Да» и «Нет» (рис. 14, справа). Во-вторых, изменение затронуло формулу главного и инверсного выхода (над буквой B либо появился, либо исчез знак отрицания).
Подведем итоги. Пользователь имеет право расставлять слова «Да» и «Нет» по своему усмотрению. Принцип построения логической схемы «И» (как стандартной, так и не стандартной) при этом остается неизменным. Разумеется, нестандартная схема всегда должна выводиться из стандартной с помощью рокировки.

Рис. 14. Стандартный (слева) и нестандартный (справа) алгоритм «И».
Произвольное расположение «Да» и «Нет» на выходах икон Вопрос позволяет удалить неоправданные связки отрицания, которые являются катализаторами ошибок
Логические связки желательно устранить из дракон-алгоритмов
Как известно, логическое отрицание представляет определенную трудность для понимания.
В связи с этим Эдвард Йодан советует:
«Если это возможно, избегайте отрицаний в булевых [логических] выражениях. Представляется, что их понимание представляет трудность для многих программистов».
В похожие ловушки часто попадают не только программисты. Трудности испытывают и многие другие люди.
Опасность ошибочного понимания провоцируют не только знаки отрицания, но и другие связки.
Поэтому Йодан расширяет и усиливает свою мысль:
«Избегайте без нужды использования сложных булевых выражений… Даже если нет неоднозначностей, такие выражения обычно с трудом понимают все, за исключением их автора».Сходные предостережения делает не только Йодан.
Его поддерживает Гленфорд Майерс:
«Распространенным источником ошибок является использование логических операций И и ИЛИ».
Возникает вопрос: можно ли устранить подобные источники ошибок? Существует ли радикальное средство, позволяющее ликвидировать опасные места, спрятанные в логических выражениях и провоцирующие появление ошибок?
К счастью, от этой неприятности можно избавиться. Ниже будет показано, что логическое отрицание (и другие логические связки) можно безболезненно изъять из графических логических выражений.
Рекомендации эргономики
Эргономика позволяет сделать алгоритмы (дракон-схемы) более легкими и удобными для понимания. Глядя на эргономичную дракон-схему, человек может сказать: «Посмотрел — и сразу понял!».
Многие люди испытывают трудности, когда видят внутри икон Вопрос сложные логические формулы, содержащие знаки И, ИЛИ, НЕ. Таким людям можно помочь, исключив эти нежелательные знаки.
Удаление логических связок из алгоритмов
Дракон-алгоритм, содержащий внутри икон Вопрос логические знаки И, ИЛИ, НЕ, всегда можно преобразовать в эквивалентный дракон-алгоритм, не содержащий указанных знаков.
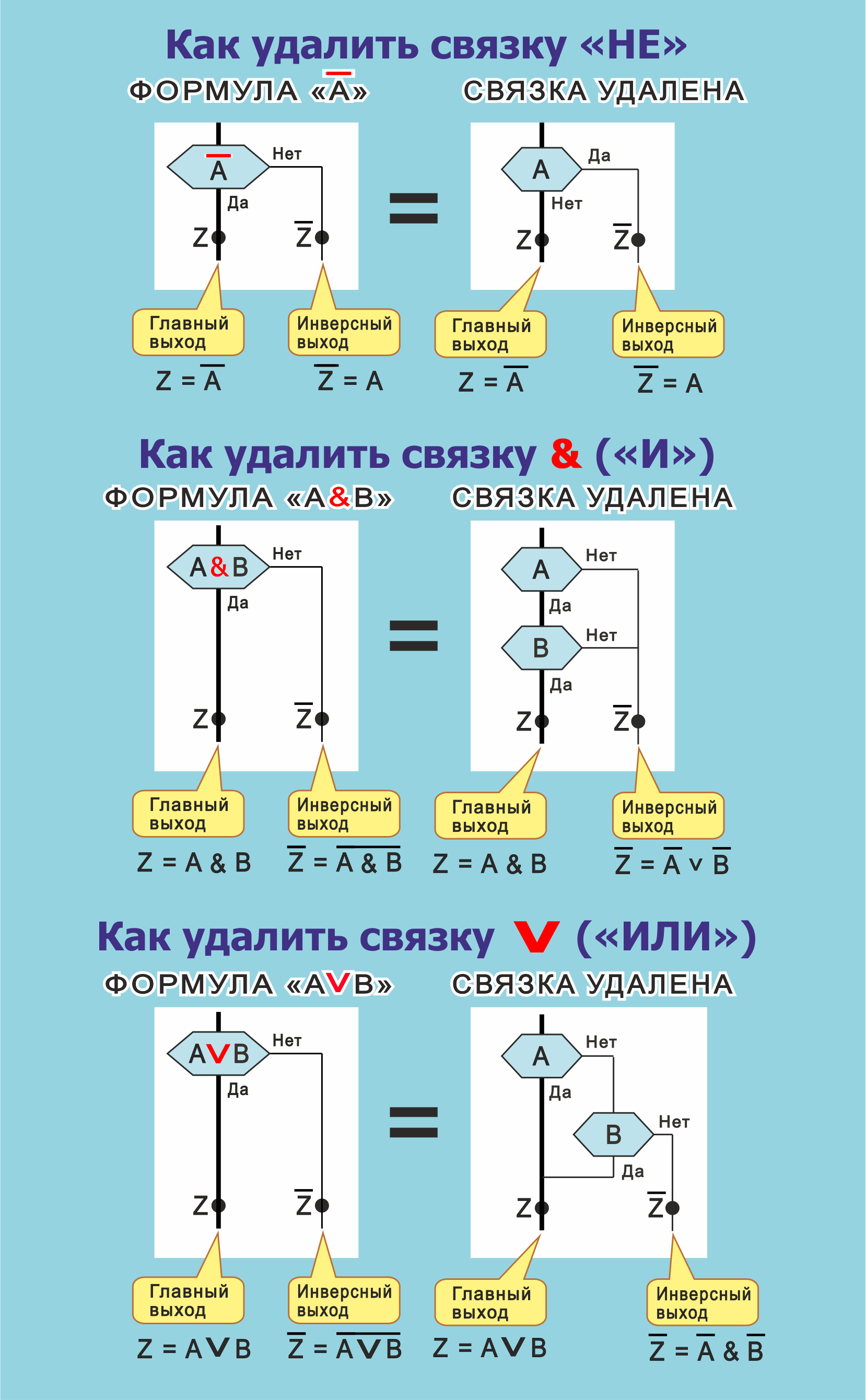
Рис. 15. Удаление логических связок с целью предотвращения ошибок
Конъюнкция без знака конъюнкции

Рис. 16. Выполняется конъюнкция без знака конъюнкции.
Комментарий в рамке облегчает понимание и страхует от ошибок
.
Дизъюнкция без знака дизъюнкции

Рис. 17. Выполняется дизъюнкция без знака дизъюнкции.
Комментарий облегчает чтение и ускоряет отладку программы
.
Визуальная логика. Визуализация сложной логической функции
На рис. 18 вверху показана сложная логическая функция Z. Она содержит семь логических связок, а именно: четыре конъюнкции &, одну дизъюнкцию V и два отрицания (верхняя черта).
При визуализации мы должны удалить все семь связок.
Результат визуализации формулы Z показан на рис. 18 на главном выходе дракон-алгоритма. Легко видеть, что в дракон-алгоритме логические связки полностью отсутствуют.
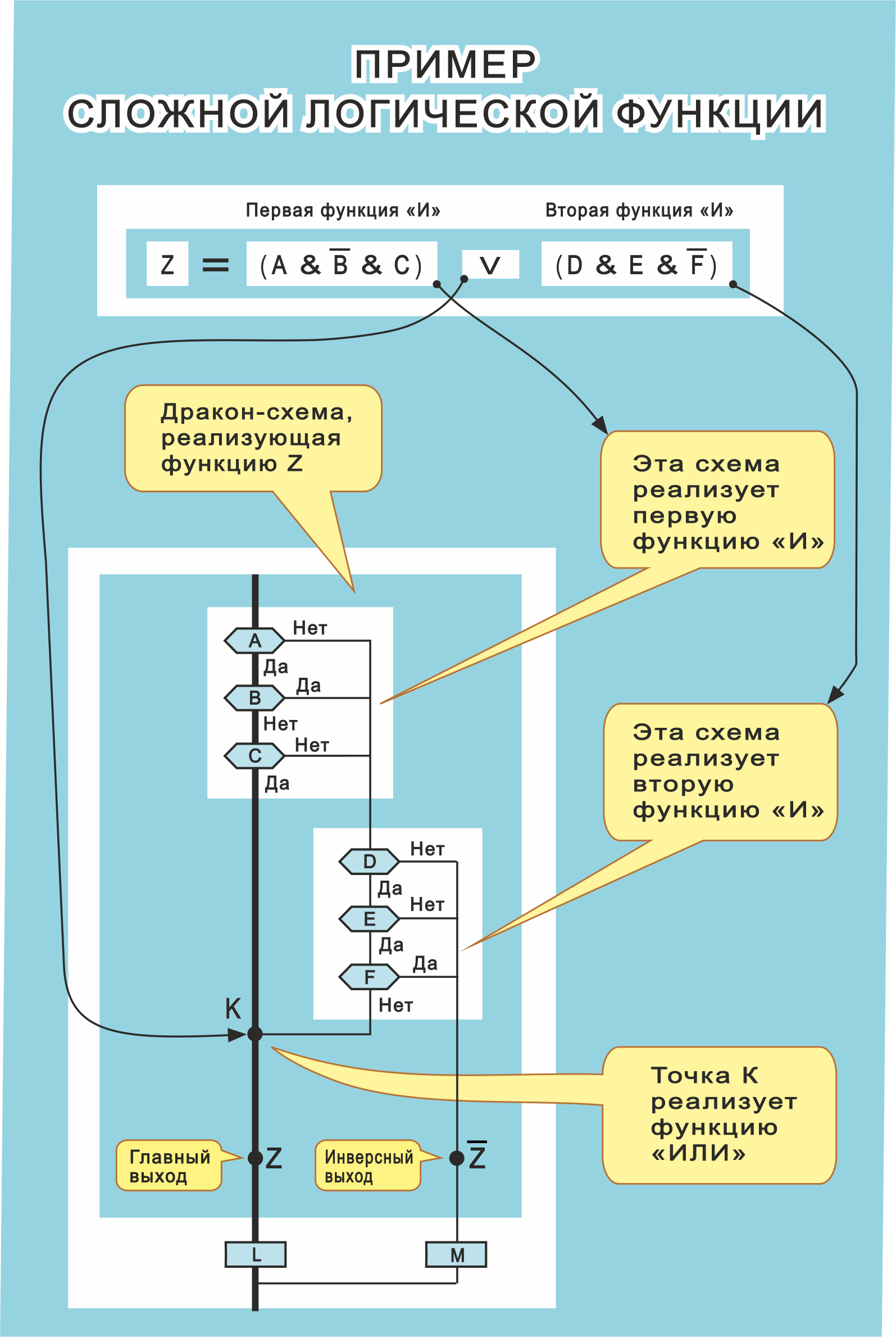
Рис. 18. Как нарисовать дракон-алгоритм для сложной логической функции
Мантра безошибочности
В языке ДРАКОН предусмотрено много средств для обеспечения безошибочности. Некоторые из них (но не все) описаны выше.
Полную совокупность средств безошибочности языка ДРАКОН для краткости можно назвать мантрой безошибочности.

Частичное доказательство правильности дракон-алгоритмов
Роберт Андерсон подчеркивает:
«целью многих исследований в области доказательства правильности программ является… механизация таких доказательств».Дэвид Грис указывает:
«доказательство должно опережать построение программы».
Объединив оба требования, получим, что автоматическое доказательство правильности должно опережать построение алгоритма. Нетрудно убедиться, что метод исчисления икон обеспечивает частичное выполнение этого требования.
Известно, что логический вывод позволяет применить к аксиомам правила вывода и получить строго доказанные теоремы.
Визуальный логический вывод, следуя этой схеме, берет за основу две визуальных аксиомы языка ДРАКОН (аксиому-силуэт и аксиому-примитив). Применяя к ним визуальные правила вывода, получим шампур-схему, т. е. графический каркас дракон-алгоритма.
Во внутренних алгоритмах ДРАКОН-конструктора закодировано исчисление икон. Поэтому любая шампур-схема, построенная с его помощью и не содержащая критических точек, является истинной, то есть правильно построенной. Этот результат означает, что:
ДРАКОН-конструктор осуществляет частичное автоматическое доказательство правильности шампур-схем.
К сожалению, данный метод позволяет доказать правильность шампур-схемы и только. Это составляет лишь часть от общего объема работы, которую нужно выполнить, чтобы доказать правильность дракон-алгоритма на 100%.
Мантра экономичности (без дополнительной затраты времени, средств и ресурсов)
Здесь необходима оговорка. Частичное доказательство правильности дракон-алгоритма с помощью «ДРАКОН-конструктора» осуществляется автоматически и достигается совершенно бесплатно, так как дополнительные затраты труда, времени и ресурсов не требуются.
Так что полученный результат (почти безошибочное автоматическое проектирование графики дракон-алгоритмов) следует признать значительным достижением.
Программно-алгоритмические ошибки и средства борьбы с ними
Ошибки в алгоритмах и программах (software bugs, logic errors) доставляют много неудобств специалистам и пользователям. Для предотвращения, поиска и исправления ошибок используют разнообразные средства:
— требования к программному обеспечению (software requirements);
— спецификация требований программного обеспечения (software requirements specification);
— просмотр кода (code review);
— статический анализ кода (static code analysis);
— тестирование (software testing);
— тестирование на основе модели (model-based testing);
— отладка (debugging);
— защитное программирование (defensive and secure programming);
— рефакторинг (refactoring);
— система отслеживания ошибок (bug tracking system);
— формальная верификация (formal verification);
— контрактное программирование (design by contract);
— проверка моделей (model checking);
— стандарт оформления кода, стиль программирования (coding standard, coding convention, programming style).
Указанные средства обладают несомненными достоинствами, однако они не снимают проблему. Сохраняется потребность в разработке новых средств противодействия ошибкам.
Метод исчисления икон и метод удаления логических связок могут дополнить этот список для случая визуального программирования.
Брифинг
Под спойлером даны краткие сведения об исчислении икон и автоматическом доказательсте.
1. Для предотвращения ошибок разработан специальный математический аппарат — визуальное логическое исчисление под названием «исчисление икон».
2. Данное исчисление является разделом визуальной математической логики.
3. Графический синтаксис языка ДРАКОН представляет собой исчисление икон.
4. Исчисление икон является теоретическим обоснованием языка ДРАКОН.
5. Графика дракон-алгоритмов играет важную роль.
6. Визуальное логическое исчисление служит для защиты графики от ошибок.
7. Исчисление икон реализовано во внутренних алгоритмах «ДРАКОН-конструктора».
8. Программа «ДРАКОН-конструктор» осуществляет частичное автоматическое доказательство правильности графики дракон-алгоритмов.
9. Почти безошибочное автоматическое проектирование графики дракон-алгоритмов является полезным достижением, повышающим производительность труда при практическом работе.

Семейство ДРАКОН-языков. Гибридные языки
ДРАКОН — не один язык, а целое семейство, которое может включать неограниченное число ДРАКОН-языков. В состав семейства входит универсальный визуальный алгоритмический язык (являющийся языком моделирования, а не программирования), а также гибридные языки программирования.
Императивную (процедурную) часть языка ДРАКОН можно присоединить к некоторым языкам программирования и получить гибридные языки, например:

Рис. 19. Примеры гибридных языков программирования ДРАКОН-семейства
Как построить гибридный язык Дракон-Си
Чтобы построить язык Дракон-Си, надо по определенным правилам соединить графический синтаксис ДРАКОНа с текстовым синтаксисом языка Си. При этом Си рассматривается как целевой язык (target language). Нужно сделать следующее:
— использовать синтаксис целевого языка (синтаксис языка Си) в качестве текстового синтаксиса гибридного языка Дракон-Си;
— удалить из текстового синтаксиса гибридного языка Дракон-Си все элементы, которые заменяются управляющей графикой ДРАКОНа;
— создать транслятор из дракон-схемы в исходный код языка Си.
Любой гибридный язык (например, Дракон-Си) почти полностью сохраняет концепцию, структуру, типы данных и другие особенности целевого языка (Си). При этом в строго определенном числе случаев текстовая нотация целевого языка заменяется на визуальную. Такой прием позволяет существенно улучшить эргономический облик языка и сократить число ошибок.
ДРАКОН играет роль защитного фильтра
Применяя гибридный язык, например, Дракон-Си, пользователь начинает работу с дракон-алгоритмом и получает все преимущества языка ДРАКОН, связанные с безошибочностью.
Известно, что Си — небезопасный язык. По мнению экспертов,
«не вызывает сомнений, что Си – изобилующий потенциальными опасностями и не вполне прозрачный для восприятия человеком язык».
Суть в том, что ДРАКОН сразу исключает многие ошибки, связанные с потоком управления, логикой и условными операторами. ДРАКОН (в составе гибридного языка Дракон-Си) служит «входной дверью» в язык Си. Такая «дверь» устраняет часть ошибок, присущих Си и тем самым играет роль защитного фильтра, не пропускающего ошибки.
Свойство защиты относится не только к Си, но и к любому целевому гибридному языку, входящему в ДРАКОН-семейство.
ДРАКОН — это новый способ работать с существующими языками программирования
Что такое ДРАКОН: язык программирования или нет? Здесь имеется заблуждение, которое необходимо устранить.
Некоторые рассматривают ДРАКОН как еще один язык программирования. Дескать, сейчас есть N языков программирования, например 9000 языков, а появился ДРАКОН, их стало на единицу больше N + 1 (9001). Это не совсем так.
ДРАКОН — это ИНОЙ способ работать с уже существующими языками программирования.
ДРАКОН работает не в одиночку, а в паре с чем-то (Мы с Тамарой ходим парой).
Что это значит?
Возьмем к примеру язык Си. Это значит, что в графических иконах ДРАКОНа мы пишем код на языке Си (без управляющих операторов, разумеется). Затем графический ДРАКОН-алгоритм (с сишным кодом) транслируется в исходный код языка Си, после чего компилируется в исполняемый код.
Это называется Гибридный язык Дракон-Си.
Вместо Си могут быть другие языки Java, JavaScript и т. д. Много вариантов.

Автоматное программирование на языке ДРАКОН
Алгоритмическая макроконструкция силуэт представляет собой конечный автомат и способна работать в двух режимах:
— императивное программирование;
— автоматное программирование.
Смотри статью Автоматное программирование на языке ДРАКОН.

Учебное пособие по языку ДРАКОН для вузов «Алгоритмические языки и программирование: ДРАКОН»
Под спойлером краткие сведения об учебном пособии.
Рецензенты:
Терехов А. Н. — доктор физико-математических наук, профессор, заведующий кафедрой системного программирования математико-механического факультета Санкт-Петербургского государственного университета;
Тюгашев А. А. — доктор технических наук, заведующий кафедрой прикладной математики, информатики и информационных систем Самарского государственного университета путей сообщения.
Паронджанов В. Д. Алгоритмические языки и программирование: ДРАКОН : учебное пособие для вузов. — Москва : Издательство Юрайт, 2020. — 430 с. — (Высшее образование).
ISBN 978-5-534-13146-8 (Издательство Юрайт)
Аннотация Улучшенные блок-схемы (дракон-схемы) позволяют быстро и без усилий изучить алгоритмы и жизнеритмы. Рассмотрены линейные, разветвленные, циклические и параллельные алгоритмы с примерами в виде наглядных и легко запоминающихся чертежей.
Эргономичные дракон-алгоритмы, понятные с первого взгляда, помогут быстро освоить секреты мастерства. Даны примеры бизнес-процессов, потоков работ, клинических алгоритмов. Курс алгоритмической логики изложен с помощью удобных и привлекательных чертежей. Представлены алгоритмы реального времени и новый перспективный метод программирования без ошибок. Двести элегантных рисунков и схем помогут читателям самостоятельно создавать алгоритмы и жизнеритмы.
Содержание учебного пособия соответствует актуальным требованиям Федерального государственного образовательного стандарта высшего образования.
Для начинающих программистов, непрограммистов, программистов-любителей, студентов, бизнесменов и топ-менеджеров.
Рекомендовано Учебно-методическим отделом высшего образования в качестве учебного пособия для студентов высших учебных заведений, обучающихся по ИТ, инженерно-техническим направлениям
Книга будет доступна на образовательной платформе «Юрайт» urait.ru, а также в мобильном приложении «Юрайт.Библиотека»

Первый недостаток: отсутствует фирма, поддерживающая и развивающая язык ДРАКОН и его инструменты
Язык ДРАКОН находится на начальном этапе развития. Он существует как идея (в Википедии ДРАКОН, DRAKON представлен на десяти языках), но он пока еще не существует как товарный продукт.
Нет никакой фирмы, которая разрабатывает, поддерживает и совершенствует язык ДРАКОН и развивает его инструменты. Этим занимаются энтузиасты, которые где-то работают full time, а в свободное время выкраивают время для ДРАКОНа. В сети «В контакте» группа ДРАКОНа насчитывает всего 300 человек, на официальном форуме ДРАКОНа столько же. Это очень мало.
Второй недостаток: инструменты ДРАКОНа имеют экспериментальный характер и нуждаются в совершенствовании
Доступны для использования четыре ДРАКОН-конструктора
для программирования:
1. ИС Дракон (коммерческая программа)
разработчик Геннадий Тышов (Россия, Северодвинск);
2. DRAKON Editor с открытым исходным кодом (public domain)
разработчик Stepan Mitkin (Норвегия);
3. Drakon.Tech с открытым исходным кодом (public domain)
разработчик Stepan Mitkin (Норвегия);
без программирования:
4. DrakonHub с открытым исходным кодом (public domain)
разработчик Stepan Mitkin (Норвегия).
Существуют еще два ДРАКОН-конструктора, которые недоступны для использования:
Артем Бразовский (Белоруссия, Минск) создал свой ДРАКОН-конструктор и использует его для коммерческих целей.
Oleg Garipov (США, Нью-йорк) разработал для своих целей собственный ДРАКОН-конструктор, но не раскрывает его.
И последнее. Эдуард Ильченко разработал публичный ДРАКОН-конструктор «Фабула» и хранил программу в облаке. Увы, он скоропостижно ушел из жизни, и ссылка стала недоступной.
Третий недостаток: отсутствует стандарт языка ДРАКОН
В качестве стандарта используются книги:
1. Паронджанов В. Д. Алгоритмы и жизнеритмы на языке ДРАКОН. Разработка алгоритмов. Безошибочные алгоритмы. — М.: Препринт, 2019. — 374 с.
2. Паронджанов В. Д. Учись писать, читать и понимать алгоритмы. Алгоритмы для правильного мышления. Основы алгоритмизации. — М.: ДМК Пресс, 2012, 2014, 2016. — 520 с.
Четвертый недостаток: микроскопическая (почти нулевая) доля рынка
Приведу примеры коммерческого использования языка ДРАКОН, по которым можно составить впечатление об его присутствии на рынке.
1-й и 2-й примеры. Предприниматель Алексей Муравицкий, системный интегратор фирмы ОВЕН
использует ДРАКОН-технологию в нефтегазовой промышленности, пищевой промышленности, теплоэнергетике
для программирования ПЛК при разработке шкафов управления установками и насосами
1. На видео показана установка глубокой переработки широкой фракции легких углеводородов (ШФЛУ) Южно-Балыкского газоперерабатывающего завода компании «Сургутнефтегаз»и шкаф управления установкой, где используется управляющая программа, 70%-80% которой написано на языке ДРАКОН.
Программа загружается в энергонезависимую память Сенсорного программируемого контроллера СПК 107 М01 фирмы ОВЕН.
2. На видео показан шкаф управления насосами объемного действия частотно-регулируемого электропривода на кустовой насосной станции Азнакаевского нефтегазодобывающего управления компании «Татнефть», где используется управляющая программа, 70%-80% которой написано на языке ДРАКОН. Программа загружается в энергонезависимую память сенсорного программируемого контроллера СПК 107 фирмы ОВЕН.
3-й пример. Предприниматель Сергей Ефанов
использует ДРАКОН-технологию уже 10 лет (с 2010 года) в торговле и других отраслях
при программировании микроконтроллеров: PIC (Microchip), MSP430 (Texas Instruments), STM32 (STMicroelectronics).
За это время с помощью ДРАКОН-конструктора «ИС Дракон» Ефанов сделал несколько десятков проектов:
— торговые автоматы,
— контрольно-кассовые машины,
— блоки защиты электродвигателей,
— GPS-трекеры,
— GSM-устройства
— и др.
4-й пример. Паулюс Добожинскас (Литва), руководитель коммерческого медицинского учебного центра
использует язык ДРАКОН для поточного (9000 человек в год) автономного обучения медиков в симуляционном классе без активного участия преподавателей и инструкторов.
Об успехах Добожинскаса по применению ДРАКОНа рассказано в статье Русской службы ВВС и на рекламном видео (на английском языке с русскими субтитрами).
5-й пример. Специалисты из Поволжского медицинского университета и Института Федеральной службы безопасности России
используют язык ДРАКОН для противодействия новой коронавирусной инфекции COVID-19.
Под спойлером представлен конспект статьи о разработке 17 клинических алгоритмов на медицинском алгоритмическом языке ДРАКОН для лечения больных коронавирусом (респираторной терапии). Алгоритмы были успешно использованы для обучения реманиматологов-анестизиологов за неделю до открытия (перепрофилирования) клиник для приема больных коронавмрусом.
Медицинский алгоритмический язык ДРАКОН против пандемии
Обучение анестезиологов-реаниматологов
В статье описана роль языка ДРАКОН при создании алгоритмов респираторной терапии. Лечение поражения лёгких при COVID-19 является трудной проблемой для анестезиологов-реаниматологов. Рост числа больных, нуждающихся в интенсивной терапии и искусственной вентиляции легких, привел к нехватке специалистов, владеющих протективной вентиляцией легких.
Возникла необходимость переподготовки врачей отделений реанимации и интенсивной терапии. Многие анестезиологи-реаниматоло-ги не являются специалистами в области респираторной терапии при осложненных формах COVID-19. Они нуждаются в дополнительных знаниях для эффективного лечения осложнённых форм и снижения летальности пациентов. Им нужна серьезная переподготовка, нужен специальный учебный курс.
Язык ДРАКОН помог врачам качественно разработать алгоритмы респираторной терапии
Группа авторов из Приволжского исследовательского медицинского университета и Института ФСБ России (Сморкалов А.Ю., Чистяков С.И., Горох О.В., Певнев А.А.) изучила медицинский язык ДРАКОН и разработала учебный курс «Интенсивная терапия осложнённых форм коронавирусной инфекции». Они составили Программу дополнительного обучения врачей анестезиологов-реаниматологов, в которой реализован комплексный подход к обучению с использованием симуляционных технологий.
Для выполнения Программы с помощью языка ДРАКОН были разработаны алгоритмы респираторной терапии и лечения осложненных форм у больных с новой коронавирусной инфекцией.
Реализация Программы позволила быстро и качественно подготовить специалистов для работы в отделениях реанимации с пациентами COVID-19. Был выработан единый подход к проведению респираторной терапии, что в свою очередь, совместно с комплексной терапией позволило добиться в одной из клиник нулевой летальности.
Результаты опубликованы в статье: «Особенности реализации программы дополнительной подготовки врачей по специальности “анестезиология-реаниматология” “Интенсивная терапия осложненных форм новой коронавирусной инфекции”».
Статья убедительно демонстрирует практическую значимость языка ДРАКОН. Ниже представлено сокращенное изложение статьи.
Сокращения
COVID-19 — coronavirus disease 2019;
ИВЛ — искусственная вентиляция легких;
НИВЛ — неинвазивная искусственная вентиляция легких;
НИМВЛ — неинвазивная масочная искусственная вентиляция легких;
ОДН — острая дыхательная недостаточность;
ОРДС — острый респираторный дистресс-синдром;
ОРИТ — отделение реанимации и интенсивной терапии.
Поражения лёгких при COVID-19. Тяжёлые и крайне тяжёлые пациенты
Проблема поражения лёгких при вирусной инфекции, вызванной COVID-19, связана с тем, что больные, нуждающиеся в реанимационной помощи по поводу развивающейся дыхательной недостаточности, обладают целым рядом специфических особенностей.
Больные, поступающие в отделение реанимации и интенсивной терапии (ОРИТ) с тяжелой дыхательной недостаточностью, как правило, старше 65 лет. Они страдают сопутствующей соматической патологией (диабет, ишемическая болезнь сердца, цереброваскулярная болезнь, неврологическая патология, гипертоническая болезнь, онкологические заболевания, гематологические заболевания, хронические вирусные заболевания, нарушения в системе свёртывания крови).
Больные, направляемые на реанимацию, относятся к категории тяжёлых или крайне тяжёлых пациентов.
При крайне тяжёлом течении часто развивались быстро прогрессирующие заболевания:
— острая дыхательная недостаточность с необходимостью респираторной поддержки (инвазивная вентиляции лёгких);
— септический шок;
— полиорганная недостаточность.
Респираторная терапия
У больных с дыхательной недостаточностью используется респираторная терапия. В настоящее время существует множество вариантов респираторной терапии:
— ингаляция кислорода (низкопоточная — до 15 л/мин, высокопоточная — до 60 л/мин);
— искусственная вентиляция легких (неинвазивная или инвазивная, высокочастотная вентиляция лёгких).
В терапии классического острого респираторного дистресс-синдрома для лечения острой дыхательной недостаточности принято использовать ступенчатый подход к выбору респираторной терапии.
Простая схема выглядит следующим образом: низкопоточная кислородотерапия — высокопоточная кислородотерапия или неинвазивная — инвазивная ИВЛ. Выбор того или иного метода респираторной терапии основан на степени тяжести дистресс-синдрома.
О чем говорит мировая практика
Мировая практика свидетельствует о крайне большом проценте летальных исходов при использовании инвазивной ИВЛ (до 85–90%) у больных с вирусной инфекцией, вызванной COVID-19. На наш взгляд данный факт связан с крайне тяжелым состоянием пациентов, особенностями течения заболевания COVID-19 и нарушениями принципов протективной вентиляции, а также применением седации и миорелаксации у этой категории больных.
Тяжесть пациентов, которым показана инвазивная ИВЛ, обусловлена большим объёмом поражения легочной ткани (как правило более 75%), а также возникающей суперинфекцией при проведении длительной ИВЛ.
Отсутствие чётких алгоритмов респираторной терапии и дефицит врачей
Применение ИВЛ у таких больных является серьёзной проблемой для большинства врачей, в том числе и анестезиологов-реаниматологов, не являющихся специалистами в области респираторной терапии.
Одной из основных трудностей проведения респираторной терапии пациентам с COVID-19 является отсутствие чётких алгоритмов и рекомендаций по выбору ее метода и настройке аппаратов ИВЛ.
В свою очередь, увеличение количества пациентов с COVID-19, нуждающихся в интенсивной терапии с потенциальной потребностью в ИВЛ, привело к дефициту врачей, знающих принципы протективной вентиляции легких.
Подбор параметров ИВЛ — это хождение по лезвию ножа
У пациентов с COVID-19 при позднем переводе на искусственную вентиляцию лёгких включается дополнительный повреждающий фактор — транспульмональное давление. Поэтому любая задержка перевода пациента на аппаратную вентиляцию лёгких приводит к увеличению объёма поражения лёгочной ткани.
В то же время сама ИВЛ является мощным повреждающим фактором, особенно при неправильно подобранных параметрах. Основными причинами этого повреждения становятся волюмотравма, баротравма, циклическая травма, оксигенотравма и ателектотравма.
Следовательно, подбор оптимальных параметров ИВЛ у больных с тяжёлыми вирусными пневмониями и ОРДС — это своего рода «хождение по лезвию ножа».
Необходимо обеспечить минимально достаточный уровень оксигенации, при этом максимально снизив негативное влияния повреждающих факторов ИВЛ на лёгкие. По нашему опыту, даже незначительное отклонение на непродолжительное время от рамок протективной вентиляции приводит к дополнительному повреждению лёгких.
Программа дополнительного обучения врачей по курсу «Интенсивная терапия осложнённых форм коронавирусной инфекции»
С учетом вышесказанного очень важным фактором, влияющим на исход тяжелого вирусного поражения лёгких, является уровень подготовки врача отделения реанимации по особенностям проведения респираторной терапии этим пациентам.
С целью быстрого, качественного и доступного обучения специалистов, работающих в реанимации, нами была разработана программа дополнительного обучения врачей по специальности «анестезиология-реаниматология», которая называется «Интенсивная терапия осложнённых форм коронавирусной инфекции».
Цель обучения в условиях пандемии COVID-19
Цель обучения — удовлетворение образовательных и профессиональных потребностей, обеспечение соответствия квалификации врачей меняющимся условиям профессиональной деятельности и социальной среды; совершенствование имеющихся профессиональных компетенций,.. необходимых для профессиональной деятельности и повышения профессионального уровня в рамках имеющейся квалификации по специальности «Анестезиология-реаниматология».
Актуальность дополнительной профессиональной программы повышения квалификации обусловлена необходимостью обновления теоретических знаний и практических навыков специалистов в связи с повышением требований к уровню их квалификации и необходимостью освоения современных методов решения профессиональных задач в условиях пандемии коронавирусной инфекции, вызванной COVID19.
Для учебного процесса нужны алгоритмы действий врача на языке ДРАКОН
Для обеспечения учебного процесса на основании руководящих документов нами были созданы алгоритмы действий по всем модулям с использованием алгоритмического медицинского языка ДРАКОН, которые позволили повысить качество и наглядность обучения.
Занятия проводились в отделениях реанимации соответствующих клиник за неделю до их открытия для приема пациентов с COVID-19. Данная ситуация позволила обучить врачей в условиях отделения, в котором им предстояло работать, что также помогло обеспечить определённый уровень психологической подготовки.
Тренинг на аппаратуре клиники
Для проведения тренинга использовалась аппаратура клиники, в которой предстояло работать врачам (мониторы, аппараты ИВЛ, дефибрилляторы, перфузоры, и т. д.). Навык проведения респираторной терапии отрабатывался на следующих аппаратах ИВЛ:
1. Drager Savina®
2. Drager Evita® XL
3. Zisline МV200 К0.20
4. Medtronic Puritan Bennett 840
5. HAMILTON-G5
Принципы обеспечения проходимости дыхательных путей при осложнениях COVID-19 (модуль 3)
Обучение на симуляционном модуле 3 (надгортанные воздуховоды, интубация трахеи, ранняя пункционная трахеостомия) проводилось по стандартной схеме симуляционного тренинга, включающего все 5 этапов.
Тренинг проводился на симуляторе пациента Kelli и заключался в отработке алгоритмов обеспечения инфекционной безопасности при проведении аэрозоль-генерирующих процедур. Имеются в виду процедуры:
— интубация трахеи,
— плановая ранняя пункционно-дилатационная трахеостомия,
— санация трахеобронхиального дерева,
— замена контура аппарата ИВЛ и бактериальных фильтров,
— экстренная коникотомия.
Особое внимание уделялось показаниям к интубации трахеи и необходимости плановой подготовки к проведению данной процедуры, с целью предотвращения инфицирования персонала, а также необходимости использования защитных экранов и коробов.
Отрабатывались различные способы обеспечения проходимости верхних дыхательных путей:
— постановка надгортанных воздуховодов,
— интубация трахеи,
— плановая трахеостомия,
— экстренная коникотомия.
Алгоритмы действий врача на языке ДРАКОН, обеспечивающие проходимость дыхательных путей (модуль 3)
Для наглядности с использованием алгоритмического медицинского языка ДРАКОН были созданы следующие алгоритмы действий:
— Перевод в ОРИТ.
— Плановая интубация трахеи.
— Экстренная интубация трахеи.
— Интубация при трудных дыхательных путях.
— Плановая ранняя трахеостомия.
— Экстренная коникотомия.
Принципы неинвазивной респираторной терапии (модуль 4)
Для проведения тренинга по симуляционному модулю 4 нами использовался симулятор пациента Kelli, симулятор высокопоточной оксигенации AIRVO 2 для операционной системы Android и неинвазивная маска. Проведение неинвазивной терапии отрабатывалось на всех доступных в клинике аппаратах ИВЛ. Структура симуляционного тренинга включала 5 стандартных этапов:
1. Входной контроль.
2. Брифинг (инструктаж).
3. Основной этап (симуляционный тренинг-имитация).
4. Дебрифинг.
5. Итоговая аттестация.
Алгоритмы действий врача на языке ДРАКОН, обеспечивающие неинвазивную респираторную терапию (модуль 4)
Для наглядности обучения были разработаны следующие алгоритмы:
— Выбор метода респираторный терапии.
— Высокопоточная оксигенация.
— Неинвазивная вентиляция лёгких.
В алгоритмах особое внимание было уделено определению показаний для выбора метода респираторной терапии и пошаговым действием врача для комфортного перевода пациента на неинвазивную вентиляцию.
Алгоритмы действий на языке ДРАКОН: Протективная ИВЛ. Эффективность рекрутмент-маневров. Вентиляция в положении на животе (модуль 5)
Подробно следует остановиться на методике изучения модуля 5 (Протективная ИВЛ. Эффективность рекрутмент-маневров. Вентиляция в положении на животе).
Весь процесс перевода на ИВЛ и eго проведение был разбит на четыре основных этапа, по каждому из них, с использованием алгоритмического медицинского языка ДРАКОН, был написан алгоритм действий:
— Подбор базовых параметров ИВЛ в концепции протективной вентиляции.
— Оценка рекрутабельности лёгких и подбор положительного давления в конце выдоха.
— Улучшение оксигенации (в том числе применение прон-позиции).— Отлучение пациента от ИВЛ.
Заключение
Разработаны 17 клинических алгоритмов на языке ДРАКОН для четырех функциональных модулей респираторной терапии при COVID-19:
Обеспечение проходимости дыхательных путей (модуль 3)
1. Перевод в ОРИТ.
2. Плановая интубация трахеи.
3. Экстренная интубация трахеи.
4. Интубация при трудных дыхательных путях.
5. Плановая ранняя трахеостомия.
6. Экстренная коникотомия.
Неинвазивная респираторная терапия (модуль 4)
7. Выбор метода респираторный терапии.
8. Высокопоточная оксигенация.
9. Неинвазивная вентиляция лёгких.
Протективная ИВЛ. Эффективность рекрутмент-маневров. Вентиляция в положении на животе (модуль 5).
10. Подбор базовых параметров ИВЛ в концепции протективной вентиляции.
11. Оценка рекрутабельности лёгких и подбор положительного давления в конце выдоха.
12. Улучшение оксигенации (в том числе применение прон-позиции).
13. Отлучение пациента от ИВЛ.
Интенсивная терапия септического шока и проведение реанимационных мероприятий (модуль 6)
14. Диагностика и интенсивная терапия септического шока.
15. Базовые реанимационные мероприятия у больных с COVID-19. 16. Расширенные реанимационные мероприятия у больных с COVID-19.
17. Перевод пациента в отделение реанимации и интенсивной терапии.
Реализация Программы позволила быстро и качественно подготовить специалистов для работы в отделении реанимации с пациентами COVID-19. Был выработан единый подход к проведению респираторной терапии. Совместно с комплексной терапией это позволило добиться в одной из клиник нулевой летальности.
В программе реализован комплексный подход к обучению врачей анестезиологов-реаниматологов с использованием симуляционных технологий. При обучении впервые применена модифицированная четырехступенчатая методика Пейтона для формирования сложного умения – подбора параметров искусственной вентиляции лёгких в рамках протективной вентиляции.
С помощью алгоритмического медицинского языка ДРАКОН были разработаны алгоритмы респираторной терапии и лечения осложненных форм у больных с новой коронавирусной инфекцией.

Сила ДРАКОНа — в новых идеях, в их эффективном сочетании и использовании в целях безошибочности.
Алгоритмическая макроконструкция силуэт, применение к алгоритмам идей когнитивной эргономики и визуальной математической логики, картографический принцип силуэта и примитива, визуальный аксиоматический метод, визуальное структурное программирование, визуальная алгебра логики, визуальное автоматное программирование — все это появилось впервые, и впервые применяется для решения труднейшей задачи — достижения безошибочности.
Причем пользователь ДРАКОНа не обязан знать, что он (пользователь) при разработке алгоритма применяет аксиоматический метод, в котором используются аксиомы, что построение ДРАКОН-алгоритма есть логический вывод из заданных аксиом на основе правил вывода.
Больше того, пользователю не нужно это знать!
Пользователь может даже не догадываться, что ДРАКОН-конструктор производит частичное автоматическое доказательство правильности всех создаваемых ДРАКОН-алгоритмов. Причем эти услуги и удобства пользователь получает бесплатно, не затрачивая дополнительно ни времени, ни денег, ни ресурсов.
Повторяю, он может даже не знать об этом, так как вся математика, направленная на достижение безошибочности, полностью скрыта от пользователя языка ДРАКОН!
Неклассическая теория алгоритмов и язык ДРАКОН
Язык ДРАКОН опирается на неклассическую теорию алгоритмов.
Современная теория алгоритмов не имеет удобного (эргономичного) языка, позволяющего облегчить и ускорить понимание алгоритмов ЧЕЛОВЕКОМ.
Она полностью игнорирует проблему безошибочности. Она не применима к клиническим алгоритмам и не содействует повышению безопасности пациентов. Она не оказывает практической помощи при разработке бизнес-процессов, потоков работ (workflows) и пр.
Современные языки программирования используют управляющие слова (if, then, else, case, switch, break, while, do, repeat, until, for, foreach, continue, loop, exit, when, last и др.) , которые играют роль визуальных помех, провоцируют появление ошибок и мешают понять смысл алгоритма в терминах предметной области.
В докладе предлагаются теоретические и практические средства, чтобы устранить или ослабить указанные недостатки. Презентация доклада здесь.
Великое объединение
Сегодня текстовое программирование доминирует в мире ИТ, опираясь на колоссальные ресурсы, вложенные в его развитие.
Чтобы помочь развитию визуального программирования, оно должно опереться на эти ресурсы. ДРАКОН — попытка использовать указанные ресурсы с помощью великого объединения двух конкурирующих идей: текстового ПО и визуального ПО.
Для решения этой задачи введено понятие гибридный язык программирования и построено открытое множество — семейство гибридных ДРАКОН-языков.

Вот один из этих людей: пилот Яред Гетачу — красивый, молодой, в полном расцвете сил (справа)

Рис. 20. Командир самолета Боинг 737 MAX Яред Гетачу (справа), управлявший рейсом 302 авиакомпании Ephiopian Airlines, вылетевшим из Аддис-Аббебы 10 марта 2019 года в 8:38 по местному времени. Что поизошло через шесть минут мы уже знаем
Может ли текстовое программирование обеспечить создание безошибочных алгоритмов?
В ближайшие десятилетия текстовое программирование будет интенсивно развиваться и добьется замечательных успехов. Будут разработаны новые языки программирования, новые инструменты и IDE, которые позволят улучшить многие параметры, устранить многие недостатки, предоставят программистам новые возможности и облегчат их труд.
Но смогут ли эти новшества обеспечить безошибочную разработку алгоритмов? По моему мнению, ответ отрицательный: нет, не смогут.
Текстовое программирование имеет принципиальный дефект. Оно не способно обеспечить безошибочность программных продуктов.
Для текстового программирования безошибочность — это непосильная задача и недостижимая цель.
Почему? Потому что программирование стало слишком сложным (а будет еще сложнее). Проклятие сложности — серьезное препятствие. Оно исключает возможность работать без ошибок.
Что нас ждет в будущем
Чтобы приблизиться к безошибочности, в текстовое программирование будут постепенно вноситься отдельные элементы визуального программирования.
Язык ДРАКОН и ДРАКОН-методология — это попытка двигаться по этому пути. ДРАКОН демонстрирует перспективность данного направления и показывает, как это можно осуществить на практике.
Литература
1. (1995) Паронджанов В. Д. Графический синтаксис языка ДРАКОН // Программирование. 1995, №3. С. 45-62.
2. (1998) Паронджанов В. Д. Как улучшить работу ума. (Новые средства для образного представления знаний, развития интеллекта и взаимопонимания). — М.: Радио и связь, 1998, 1999. — 352 с.
7. (2012) Паронджанов В. Д. Учись писать, читать и понимать алгоритмы. Алгоритмы для правильного мышления. Основы алгоритмизации. — М.: ДМК Пресс, 2012, 2014, 2016. — 520 с.
12. (2019) Митькин С. Б. Автоматное программирование на языке ДРАКОН // Программная инженерия. Том 10, № 1, 2019.
15. (2021) Паронджанов В. Д. Алгоритмические языки и программирование: ДРАКОН : учебное пособие для вузов. — Москва : Издательство Юрайт, 2020. — 430 с. — (Высшее образование). (В печати).
Литература на тему «Медицинский алгоритмический язык ДРАКОН»
16. (2012) Специализированная реанимация новорожденного. Учебник / Под ред. Р. Й. Надишаускене — Литва, 2012. — 396 с.
17. (2014) Aiste Vileikyte, Ruta Jolanta Nadisauskiene, Vladimiras Parandzanovas, Paulius Dobozinskas, Algirdas Karalius, Ausrele Kudreviciene. Algoritmines „Drakon“ kalbos pritaikymas medicinoje (на литовском языке). —
18. (2016) Паронджанов В.Д. Можно ли улучшить медицинский язык? // Человек. 2016. №1. — С. 105-122.
19. (2016) Паронджанов В. Только со смертью догмы начинается наука // Медицинская газета. N 97. 23 дек. 2016. — С. 11.

Составление алгоритмов как способ достижения метапредметных результатов

Метапредметные результаты – это…
- способы деятельности освоенные на базе одного, нескольких или всех учебных предметов
- «мосты», помогающие применять объем знаний

«Универсальные учебные действия» — это…
- умение учиться , то есть способность ребенка к саморазвитию и самосовершенствованию путем сознательного и активного присвоения нового социального опыта (в широком значении);
- совокупность способов действия учащегося, а также связанных с ними навыков учебной работы, обеспечивающих самостоятельное усвоение новых знаний, формирование умений, включая организацию этого процесса (в узком смысле).
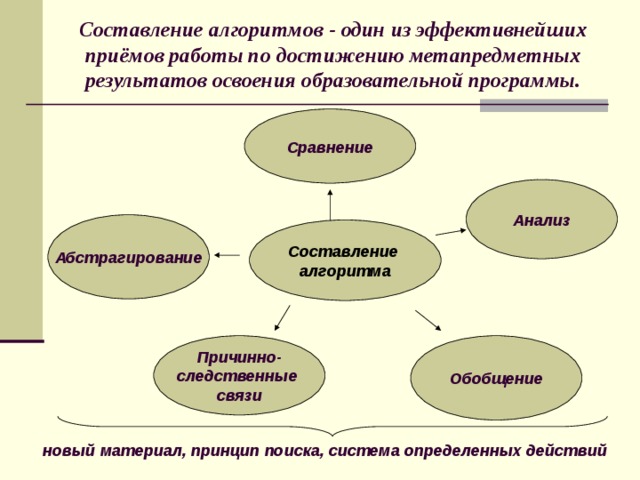
Составление алгоритмов — один из эффективнейших приёмов работы по достижению метапредметных результатов освоения образовательной программы.
Сравнение
Анализ
Абстрагирование
Составление
алгоритма
Обобщение
Причинно-
следственные
связи
новый материал, принцип поиска, система определенных действий
Алгоритм
последовательность
действий,
ведущая
к поставленной
цели
правило,
пользуясь
которым,
обучающиеся
приходят
к правильному
выбору

Основные свойства алгоритма (теория В.П.Беспалько)
- Определённость (простота и однозначность операций).
- Массовость (приложимость к целому классу задач).
- Результативность (обязательное подведение к ответу).
- Дискретность (членение на элементарные шаги)
Виды алгоритмов
Виды алгоритмов
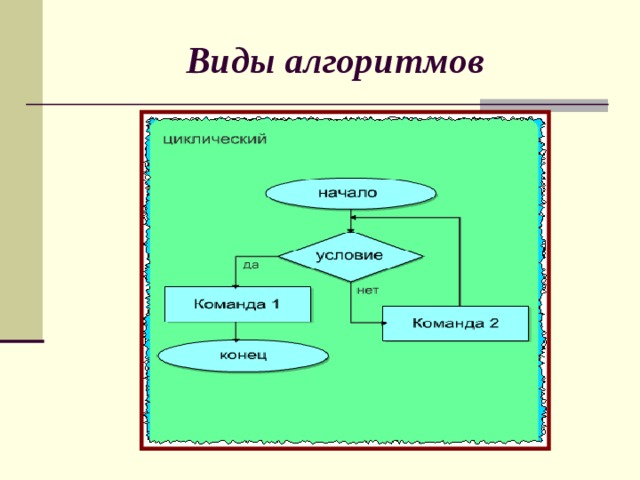
Виды алгоритмов
Пути обучения алгоритму
учитель даёт
в готовом
виде,
ученики
заучивают
учащиеся
сами
«открывают»
алгоритм

Метапредметные результаты, достигаемые при «открытии» алгоритма учащимися
- умение самостоятельно определять цели своего обучения, ставить и формулировать для себя новые задачи в учёбе и познавательной деятельности, развивать мотивы и интересы своей познавательной деятельности;
- умение самостоятельно планировать пути достижения целей;
- владение основами самоконтроля, самооценки, принятия решений и осуществления осознанного выбора в учебной и познавательной деятельности;
- умение устанавливать причинно-следственные связи, строить логическое рассуждение, умозаключение и делать выводы;
- умение создавать, применять и преобразовывать модели и схемы для решения учебных и познавательных задач;
- смысловое чтение.

Способы работы с алгоритмом

Цель проектной деятельности — реализация проектного замысла
- решение конкретной проблемы создание продукта необходимого для конкретного использования





Визитка проекта
- Тема проекта: «Спряжение глагола. Правописание личных окончаний глагола»
- Название проекта: «Спряжение, я тебя знаю!»
- Дидактическая цель: формирование умений разработки решения практической задачи (практико-ориентированный проект)
- Проблемные вопросы: 1) при каком условии можно ошибиться в написании личного окончания глагола? 2) каков должен быть алгоритм действий, чтобы избежать ошибки?
- Учебный предмет: русский язык
- Возраст учащихся: 10-11 лет (5 класс)
- Итоговый продукт: алгоритм «Правописание личных окончаний глагола»
- Длительность проекта: урок

Визитка проекта

Начало проекта
- Спишите, вставляя пропущенные буквы, выделите личные окончания глаголов, определите спряжение.
Он сообщ…т мне новость.
Мак цвет..т недолго.
Папа бре…тся.
Они стел…т половики.
Начало проекта
ит
Он сообщ мне новость. (2 спр.)
Мак цвет недолго. (1 спр.)
Папа бре ся. (1 спр.)
Они стел половики. (1 спр.)
ёт
ет
ют

Планирование
- Задачи:
- Выработать алгоритм действий для безошибочного написания личных окончаний глагола
- Научиться пользоваться алгоритмом
Критерии оценки алгоритма:
- Ясность, простота
- Небольшой объём
- Логичность
- Результативность

Реализация проекта
- Составьте алгоритм «Правописание личных окончаний глаголов», используя сведения п.82 (с.229, «Вспомните!»),п. 83 (упр.652(2)).
- Проверьте его работу, выполнив упр.653 (устно).
- Сверьте свой алгоритм с критериями.
Критерии оценки алгоритма:
- Ясность, простота
- Небольшой объём
- Логичность
- Результативность

Представление алгоритма (примерное содержание)
- Ставим ударение в слове.
- Если ударение падает на гласную окончания, пишем то, что слышим. Вспоминаем, глаголы какого спряжения имеют такое окончание, определяем спряжение.
- Если окончание безударное, ставим глагол в начальную форму, смотрим, на что оканчивается глагол, вспоминаем глаголы-исключения, относящиеся ко второму и первому спряжению, определяем спряжение, вспоминаем окончания глаголов данного спряжения, вставляем букву.

Оценивание.Итоги

Алгоритм — это четкая последовательность действий, выполнение которой дает какой-то заранее известный результат. Проще говоря, это набор инструкций для конкретной задачи. Известнее всего этот термин в информатике и компьютерных науках, где под ним понимают инструкции для решения задачи эффективным способом.
Сейчас под этим словом понимают любые последовательности действий, которые можно четко описать и разделить на простые шаги и которые приводят к достижению какой-то цели. Например, пойти на кухню, налить воду и положить в нее пакетик чая — это алгоритм для выполнения задачи «Заварить чай».
Алгоритмы в информатике — инструкции для компьютеров, набор шагов, который описывается программным кодом. Существуют конкретные алгоритмы для тех или иных действий, причем некоторые из них довольно сложные. Одна из целей использования алгоритмов — делать код эффективнее и оптимизировать его.
В общем смысле — абсолютно все живые и некоторые неживые существа, потому что любую последовательность действий, ведущую к цели, можно считать алгоритмом. Поиск еды животным — алгоритм, движения робота тоже описываются алгоритмом.
В узком смысле, в котором понятие используется в компьютерных науках, алгоритмами пользуются разработчики, некоторые инженеры и аналитики, а также специалисты по машинному обучению, тестировщики и многие другие. Это одно из ключевых понятий в IT.
Алгоритмы в информатике нужны для эффективного решения различных задач, в том числе тех, выполнение которых «в лоб» имеет высокую сложность или вовсе невозможно. На практике существуют алгоритмы практически для чего угодно: сортировки, прохождения по структурам данных, поиска элементов, фильтрации информации, математических операций и так далее.
Например, отсортировать массив можно в ходе полного перебора — это самое очевидное решение. А можно воспользоваться алгоритмом быстрой сортировки: он сложнее и не так очевиден, зато намного быстрее работает и не так сильно нагружает мощности компьютера. Строго говоря, полный перебор — это тоже алгоритм, но очень простой.
Существуют алгоритмически неразрешимые задачи, для решения которых нет и не может существовать алгоритма. Но большинство задач в IT разрешимы алгоритмически, и алгоритмы активно используются в работе с ними.
Алгоритмы применяются во всех направлениях IT и во многих других отраслях. Инструкции для автоматизированного станка или линии производства — алгоритмы, рецепт блюда — тоже.
Дискретность. Алгоритм — не единая неделимая структура, он состоит из отдельных маленьких шагов, или действий. Эти действия идут в определенном порядке, одно начинается после завершения другого.
Результативность. Выполнение алгоритма должно привести к какому-либо результату и не оставлять неопределенности. Результат может в том числе оказаться неудачным — например, алгоритм может сообщить, что решения нет, — но он должен быть.
Детерминированность. На каждом шаге не должно возникать разночтений и разногласий, инструкции должны быть четко определены.
Массовость. Алгоритм обычно можно экстраполировать на похожие задачи с другими исходными данными — достаточно поменять изначальные условия. Например, стандартный алгоритм по решению квадратного уравнения останется неизменным вне зависимости от того, какие числа будут использоваться в этом уравнении.
Понятность. Алгоритм должен включать только действия, известные и понятные исполнителю.
Конечность. Алгоритмы конечны, они должны завершаться и выдавать результат, в некоторых определениях — за заранее известное число шагов.
Несмотря на слово «последовательность», алгоритм не всегда описывает действия в жестко заданном порядке. Особенно это актуально сейчас, с распространением асинхронности в программировании. В алгоритмах есть место для условий, циклов и других нелинейных конструкций.
Линейные. Это самый простой тип алгоритма: действия идут друг за другом, каждое начинается после того, как закончится предыдущее. Они не переставляются местами, не повторяются, выполняются при любых условиях.
Ветвящиеся. В этом типе алгоритма появляется ветвление: какие-то действия выполняются, только если верны некоторые условия. Например, если число меньше нуля, то его нужно удалить из структуры данных. Можно добавлять и вторую ветку: что делать, если условие неверно — например, число больше нуля или равно ему. Условий может быть несколько, они могут комбинироваться друг с другом.
Циклические. Такие алгоритмы выполняются в цикле. Когда какой-то блок действий заканчивается, эти действия начинаются снова и повторяются некоторое количество раз. Цикл может включать в себя одно действие или последовательность, а количество повторений может быть фиксированным или зависеть от условия: например, повторять этот блок кода, пока в структуре данных не останется пустых ячеек. В некоторых случаях цикл может быть бесконечным.
Рекурсивные. Рекурсия — это явление, когда какой-то алгоритм вызывает сам себя, но с другими входными данными. Это не цикл: данные другие, но «экземпляров» работающих программ несколько, а не одна. Известный пример рекурсивного алгоритма — расчет чисел Фибоначчи.
Рекурсия позволяет изящно решать некоторые задачи, но с ней надо быть осторожнее: такие алгоритмы могут сильно нагружать ресурсы системы и работать медленнее других.
Вероятностные. Такие алгоритмы упоминаются реже, но это довольно интересный тип: работа алгоритма зависит не только от входных данных, но и от случайных величин. К ним, например, относятся известные алгоритмы Лас-Вегас и Монте-Карло.
Основные и вспомогательные. Это еще один вид классификации. Основной алгоритм решает непосредственную задачу, вспомогательный решает подзадачу и может использоваться внутри основного — для этого там просто указываются его название и входные данные. Пример вспомогательного алгоритма — любая программная функция.
Алгоритмы могут записывать текстом, кодом, псевдокодом или графически — в виде блок-схем. Это специальные схемы, состоящие из геометрических фигур, которые описывают те или иные действия. Например, начальная и конечная точка на схеме — соответственно, начало и конец алгоритма, параллелограмм — ввод или вывод данных, ромб — условие. Простые действия обозначаются прямоугольниками, а соединяются фигуры с помощью стрелок — они показывают последовательности и циклы.
В схемах подписаны конкретные действия, условия, количество повторений циклов и другие детали. Это позволяет нагляднее воспринимать алгоритмы.

Понятие «сложность» — одно из ключевых в изучении алгоритмов. Оно означает не то, насколько трудно понять тот или иной метод, а ресурсы, затраченные на вычисление. Если сложность высокая, алгоритм будет выполняться медленнее и, возможно, тратить больше аппаратных ресурсов; такого желательно избегать.
Сложность обычно описывают большой буквой O. После нее в скобках указывается значение, от которого зависит время выполнения. Это обозначение из математики, которое описывает поведение разных функций.
Какой бывает сложность. Полностью разбирать математическую O-нотацию, как ее называют, мы не будем — просто перечислим основные обозначения сложности в теории алгоритмов.
- O(1) означает, что алгоритм выполняется за фиксированное константное время. Это самые эффективные алгоритмы.
- O(n) — это сложность линейных алгоритмов. n здесь и дальше обозначает размер входных данных: чем больше n, тем дольше выполняется алгоритм.
- O(n²) тоже означает, что чем больше n, тем выше сложность. Но зависимость тут не линейная, а квадратичная, то есть скорость возрастает намного быстрее. Это неэффективные алгоритмы, например с вложенными циклами.
- O(log n) — более эффективный алгоритм. Скорость его выполнения рассчитывается логарифмически, то есть зависит от логарифма n.
- O(√n) — алгоритм, скорость которого зависит от квадратного корня из n. Он менее эффективен, чем логарифмический, но эффективнее линейного.
Существуют также O(n³), O(nn) и другие малоэффективные алгоритмы с высокими степенями. Их сложность растет очень быстро, и их лучше не использовать.
Графическое описание сложности. Лучше разобраться в сложности в O-нотации поможет график. Он показывает, как изменяется время выполнения алгоритма в зависимости от размера входных данных. Чем более пологую линию дает график, тем эффективнее алгоритм.

O-нотацию используют, чтобы оценить, эффективно ли использовать ту или иную последовательность действий. Если данные большие или их много, стараются искать более эффективные алгоритмы, чтобы ускорить работу программы.
Мы приведем несколько примеров использования разных алгоритмов в отраслях программирования. На самом деле их намного больше — мы взяли только часть, чтобы помочь вам понять практическую значимость алгоритмов.
Разработка ПО и сайтов. Алгоритмы используются для парсинга, то есть «разбора» структур с данными, таких как JSON. Парсинг — одна из базовых задач, например в вебе. Также алгоритмы нужны при отрисовке динамических структур, выводе оповещений, настройке поведения приложения и многом другом.
Работа с данными. Очень активно алгоритмы применяются при работе с базами данных, файлами, где хранится информация, структурами вроде массивов или списков. Данных может быть очень много, и выбор правильного алгоритма позволяет ускорить работу с ними. Алгоритмы решают задачи сортировки, изменения и удаления нужных элементов, добавления новых данных. С их помощью наполняют и проходят по таким структурам, как деревья и графы.
Отдельное значение алгоритмы имеют в Big Data и анализе данных: там они позволяют обработать огромное количество информации, в том числе сырой, и не потратить на это слишком много ресурсов.
Поисковые задачи. Алгоритмы поиска — отдельная сложная отрасль. Их выделяют в отдельную группу, в которой сейчас десятки разных алгоритмов. Поиск важен в науке о данных, в методах искусственного интеллекта, в аналитике и многом другом. Самый очевидный пример — поисковые системы вроде Google или Яндекса. Кстати, подробности об используемых алгоритмах поисковики обычно держат в секрете.
Машинное обучение. В машинном обучении и искусственном интеллекте подход к алгоритмам немного другой. Если обычная программа действует по заданному порядку действий, то «умная машина» — нейросеть или обученная модель — формирует алгоритм для себя сама в ходе обучения. Разработчик же описывает модель и обучает ее: задает ей начальные данные и показывает примеры того, как должен выглядеть конечный результат. В ходе обучения модель сама продумывает для себя алгоритм достижения этого результата.
Такие ИИ-алгоритмы могут быть еще мощнее обычных и используются для решения задач, которые разработчик не в силах разбить на простые действия сознательно. Например, для распознавания предметов нужно задействовать огромное количество процессов в нервной системе: человек просто физически не способен описать их все, чтобы повторить программно.
В ходе создания и обучения модели разработчик тоже может задействовать алгоритмы. Например, алгоритм распространения ошибки позволяет обучать нейросети.
Виктор Тимофеев, osa@pic24.ru (ноябрь, 2009)
Скачать в PDF-формате
Как писать программы без ошибок
Введение
Про ошибки
По профессии я занимаюсь поиском и исправлением ошибок в чужих программах. За время работы я набрал некоторую коллекцию всевозможных багов и попытался свести их в одну таблицу и классифицировать с тем, чтобы оформить некую брошюру по быстрому поиску и исправлению наиболее часто встречающихся ошибок. Однако произвести такую классификацию не удалось. Дело в том, что, выделив 5-6 основных ошибок, таких как: неправильное приведение типов, путаница со знаковыми и беззнаковыми выражениями, пренебрежение выполнением проверок аргументов функций и пр., — я увидел, что остальные ошибки слишком индивидуальны, чтобы их как-то обобщать. О приемах поиска и говорить нечего, т.к. их намного больше, чем самих ошибок.
Тем не менее, каждый раз, исправляя какую-либо ошибку, я для себя отмечал, что ее можно было и не совершить, если бы то-то, то-то. Со временем я уяснил, что большая часть ошибок совершается из-за неправильного подхода к процессу программирования. Поэтому идея написания брошюры «Локализация и исправление ошибок» перешла в идею написания брошюры «Как не совершать ошибки». И я считаю это правильным, потому что лучше учиться строить, а не восстанавливать плохо построенное. Большая часть советов, описываемых мной, довольно банальны и просты. Вроде как, все их знают, но почему-то многие не придерживаются.
О каких ошибках идет речь. Конечно же, не о тех, которые обнаруживает компилятор при трансляции программы. Пока мы не исправим эти ошибки, нам не удастся получить код, который мы сможем прошить в контроллер. Эти ошибки в большинстве своем означают, что текст не соответствует правилам языка программирования, и, по сути, являются помарками. Также в этом материале не хотелось бы касаться так называемых «запланированных» ошибок (обработка неправильных данных, пришедших извне, ошибочные действия пользователя и пр.). Мы будем говорить об ошибках реализации, т. е. о тех, которые будут проявляться в ходе выполнения программы. Эти ошибки являются следствием неправильно запрограммированного (или составленного) алгоритма, допуска условностей, невнимательности и неаккуратности.
Для кого это пособие
В этом пособии я изложил свой подход к программированию микроконтроллеров, привел свои правила, которыми руководствуюсь при написании программ, и обозначил те моменты, которым при написании программ уделяю особое внимание. Уверен, что моя точка зрения не единственная, а также, что где-то мне самому еще есть чему поучиться. Так что я буду рад, не только если пособие окажется кому-то полезным, но также если кто-то решит меня в чем-то поправить или дополнить.
Статья рассчитана на широкий круг программистов, поэтому я старался не затрагивать концепцию доказательного программирования, и вообще старался привести больше практических советов, чем теории (с которой сам на «Вы») и формалистики. Так же в этом пособии нет описания приемов повышения надежности программ (самодиагностика, троирование, перепроверка действий и пр.).
Не следует считать, что после прочтения данного пособия ваши программы автоматически станут безошибочными, и уж тем более, что в будущем ошибок не будет вовсе. Ошибки все равно будут, но процент их сильно сократится. Более того, на написание программ по правилам, изложенным в этом пособии, будет затрачено время в два, в три, в пять раз больше, чем без правил. Писать программы без ошибок — это труд, причем кропотливый. Просто в отличие от кропотливого труда по поиску и исправлению ошибок, этот вид труда поддается планированию и формализации, т.е. является предсказуемым. А применение описанных здесь правил в разы сократит время непредсказуемого процесса отладки, который, как показывает практика, зачастую отнимает намного больше времени, чем само кодирование.
Предполагается, что читатель знает, что такое контроллер, как он устроен, как включается, наконец, что такое электрический ток, потому что без этих знаний заниматься микроконтроллерами бесполезно. Так что, как говорилось в старом анекдоте: «Учите матчасть!»
![]()
«Учите матчасть!»
Это самая очевидная рекомендация. Про нее можно было и не говорить, но для полноты картины вскользь коснемся этой темы. Программист, пишущий для контроллеров должен знать схемотехнику, устройство самого контроллера, язык программирования, на котором пишет программу, и особенности используемого компилятора. Тот программист, который пренебрегает необходимостью иметь эти знания, теряет право жаловаться на то, что его программа не работает.
Схемотехника
Как минимум нужно знать:
-
основы электроники (и цифровой и аналоговой)
-
законы Ома и Кирхгофа
-
типовые схематические решения (RC-цепочки, транзисторные ключи)
Кроме того, нужно знать, что необходимо устанавливать диоды параллельно катушкам реле, что светодиоды включаются через токоограничивающий резистор, что у механических контактов есть такое явление как дребезг, и пр.
Контроллер
Нужно знать архитектуру контроллера, способы адресации, регистры и их назначения, периферийные модули и режимы их работы, диапазоны рабочих температур, частот, питаний и пр., нагрузочная способность портов и т.д.
Не нужно стесняться заглядывать в фирменные даташиты, там есть ответы на большинство вопросов. А то у кого-то не работает PORTA (в то время как не отключены аналоговые цепи), у кого-то не появляется «1» на выходе RA4, у кого-то прерывание по RB0 срабатывает только в половине случаев и т.д.
Язык
Конечно же, нужно знать сам применяемый язык программирования.
Для ассемблера это:
-
формат команд;
-
типы и количество операндов
Для языков высокого уровня это:
-
семантика операторов;
-
квалификаторы данных и функций;
-
типы данных;
-
преобразование типов;
-
приоритеты операций;
-
указатели (или указатели на указатели);
Компилятор
Разработчики компиляторов для микроконтроллеров, стремясь адаптировать компилятор под конкретную платформу, позволяют себе отходить от стандартов языка, одновременно не нарушая их. Каждый компилятор имеет свои особенности, незнание которых может привести к трудностям при портировании или при использовании чужих библиотек:
-
набор директив;
-
типы данных (размерность, знаковость);
-
квалификаторы (near, far, const, rom);
-
организация прерываний.
![]()
Этапы программирования
Когда ТЗ согласовано и задача формализована (переведена с проблемно ориентированных требований в технические: входные/выходные данные, режимы работы и пр.), начинается сам процесс программирования.
-
Планирование (включает в себя проектирование, составление плана действий, выявление требуемых ресурсов).
-
Кодирование (запись самой программы в машинном языке)
-
Отладка (локализация и устранение ошибок)
-
Тестирование (проверка работоспособности и соответствие спецификации)
-
Оформление проектной документации
-
Эксплуатация и сопровождение
Беда в том, что многие пренебрегают планированием, а также считают, что отладка появляется только в том случае, если была допущена какая-то ошибка при кодировании, а так как надеются с первого раза написать без ошибок, то и процесс отладки не учитывается. Однако же, в реальности отладка – это обязательный процесс, на который, вдобавок, приходится большая часть времени, сил и нервов. Закодировать даже самый сложный и запутанный алгоритм – это нетрудно, трудно заставить его работать, или, если они был написан правильно, убедиться в его работоспособности. Поэтому процессы отладки и тестирования самые длительные и самые трудоемкие. Однако, время отладки можно сократить, сделав процесс более предсказуемым и управляемым, а именно – спланировав программу.
![]()
Планирование программы
Почему-то часто планированием программы вообще пренебрегают. И в лучшем случае все планирование состоит из подсчета количества требуемых выводов входа/выхода. Напомню одну старую шутку: «Нетщательно спланированная работа отнимает в 3 раза больше предполагаемого времени, тщательно спланированная – только в два». Ее можно дополнить: «Неспланированная работа отнимает все время».
Кто-то может сказать: «Я пишу маленькие программы, что там планировать?». Тем не менее, практика показывает, что лучше для маленькой программы потратить 10-15 минут на планирование (просто расписать на листе бумаги), чем тратить 3-4 дня на поиск ошибки, рытье Интернета и отбивание от обвинений в ламерстве на форумах в сети.
Ниже приведены этапы планирования программы:
Рассмотрим каждый этап более подробно.
![]()
Расписать алгоритм
Алгоритм – это ДНК программы, вернее – ее генетический код. Если в нем ошибка, то программа будет вести себя неправильно. Часто еще при составлении алгоритма на бумаге всплывают некоторые ответвления, которые могут быть проигнорированы при написании программы «в лоб». Преимущество в том, что алгоритм составляется в абстрактных терминах, еще нет ни типов данных, ни переменных, поэтому есть возможность сосредоточиться на конкретных алгоритмических моментах, не думая пока о деталях реализации. В большинстве случаев требуется составить несколько алгоритмов: один общий для всей программы, описывающий режимы работы и порядок переключения между ними, и алгоритмы работы каждого режима в отдельности. Степень детальности алгоритма, конечно, зависит от сложности программы в целом и каждого узла в отдельности.
Алгоритм может быть представлен как в виде блок-схемы, так и в виде графа переходов, в виде графика эпюр сигналов и т.д. Не стоит забывать о требованиях к проектной документации; например, если в документации требуется привести алгоритм в виде блок-схемы, то не нужно его сначала рисовать в виде графа переходов, а затем переводить в блок-схему.
![]()
Продумать модули
Нам нужно заранее продумать, из каких модулей будет собираться наша программа, вернее, на какие модули она будет разбита. Преимущества модульности я поясню ниже, а здесь приведу рекомендации, как правильно разбить программу на модули.
Во-первых, разбиение должно быть произведено по функциональному признаку. Т.е. не нужно в один модуль заталкивать USART и вывод звука на пьезодинамик, даже если при конкретной реализации это и кажется целесообразным. Дело в том, что однажды написанный модуль можно будет переносить в другие проекты, избавляя себя от необходимости писать один и тот же код по много раз. Чем модуль будет функционально изолированнее, тем проще будет его перенос. Однако и здесь не следует бросаться в крайности и делать отдельно модули для передачи данных по USART, для приема данных по USART, для подсчета и сравнения контрольной суммы данных, принятых по USART, и т.п. Функционально модуль должен быть полным, но безысбыточным.
Также стоит отметить, что при разбиении своей будущей программы на модули нужно учитывать наличие уже готовых модулей (либо своих, либо чужих).
Большинство модулей можно разделить на два типа: системные (работают на уровне сигналов и железа) и алгоритмические (работают на уровне обработки данных и режимов). Хороший пример – работа ЖКИ. Предположим, нам требуется выводить информацию на ЖКИ HD44780. Крайне неудачным решением будет такое, при котором функции вывода конкретных данных на экран, вызываемые из головной программы, и функции работы с самим HD44780, вызываемые из функции вывода данных, будут помещены в один модуль. Тут получается, что модули обоих типов – алгоритмический и системный – смешаны в один, что сильно затруднит в дальнейшем, например, использование индикатора другого типа. Если же мы четко разделим системный функционал и алгоритмический, то в дальнейшем замена типа индикатора выльется для нас всего лишь в замену системного модуля.
![]()
Продумать данные
Также на этапе планирования мы определяем для себя, какими данными будет оперировать наша программа. Причем нужно обозначить не только назначение данных и требуемый их объем, но также заранее предусмотреть их размещение (ROM или RAM, конкретный банк RAM) и область видимости (например, нам нет смысла делать видимым во всей программе буфер выходных данных i2c).
![]()
Разделить периферию контроллера между процессами
Периферийные модули контроллера помогают упростить некоторые программные узлы, а иногда просто делают их возможными (например, без АЦП мы не сможем измерить аналоговый сигнал). Но зачастую бывает, что программных узлов, требующих использование встроенной периферии, больше, чем имеется на борту у контроллера. Поэтому периферийные модули приходится разделять между несколькими задачами (типичный пример – таймеры). При проектировании программы нужно заранее распределить периферийные модули между задачами, что поможет выбрать оптимальные параметры для каждого модуля.
(Видел программу, в которой неправильно распределенные ресурсы привели к тому, что пришлось мультиплексировать управление GSM-модулем и GPS-приемником на один USART. Программа начала сбоить и, насколько я знаю, ее так и не привели в рабочее состояние.)
![]()
Учесть физические свойства обвеса
Контроллер с нашей программой будет жить не сам по себе, его будут окружать какие-то внешние схематические узлы, специализированные микросхемы и пр. Проектируя программу, нужно заранее учесть особенности всех подключенных к контроллеру устройств, цепей и микросхем.
Например, если в устройстве будут кнопки, то нужно помнить, что механические контакты дребезжат и шуршат. Это сразу должно наталкивать на использование каких-то дополнительных счетчиков и/или таймеров для подавления этих эффектов.
Также стоит помнить про «холодный» старт внешней периферии. Например, у нас есть ЖКИ, которому после подачи питания требуется 10 мс для самоинициализации, во время которой он не будет слышать команд извне. Если этого не учесть, то может получиться так, что наш контроллер начинает инициализацию ЖКИ примерно в то же время, когда ЖКИ заканчивает свою внутреннюю инициализацию. В результате ЖКИ то будет успевать самоинициализирваться и начинать прием наших данных, то не будет. И когда мы поймем, в чем дело, и увеличим задержку перед инициализацией до 20 мс, мы с удивлением обнаружим, что теперь при включении питания, например, успевает туда-сюда сработать реле, т.к. с новой задержкой неинициализированное состояние управляющего им вывода держится достаточно для того, чтобы ток в катушке реле успел вырасти и привести к срабатыванию.
Если в нашем устройстве предполагается прием данных по радио, то мы должны учесть, что в радиоканале есть помехи, и что прием такого сигнала нельзя делать «в лоб» по фронтам, а нужно, как и в случае с обработкой сигналов от механических контактов, заводить дополнительные счетчики, таймеры и т.п.
Примеров про обвес можно придумать еще много: состязания на шине, емкостные нагрузки, внешние источники прерываний и т.д. Все это нужно учитывать еще до начала написания текста программы, заранее предусматривая порядок действий и резервируя дополнительные ресурсы (память и скорость).
![]()
Предусмотреть возможность расширения
При проектировании программы следует заранее убедиться, что в случае значительного разрастания в дальнейшем функционала (а значит и кода) будет возможность заменить выбранный контроллер более мощным с минимальными затратами. Если мы, например, решили использовать в нашей разработке контроллер из линейки PIC16, а на этапе планирования мы прикинули, что подойдет только 16F877, или 16F946, или 16F887 (короче говоря – с максимальным объемом памяти), значит, мы неправильно выбрали линейку. В этом случае нужно брать PIC18, потому что велика вероятность того, что программа в выбранный контроллер просто не влезет.
Часто встречаю на форумах крики души: «помогите оптимизировать программу, а то она не лезет в PIC18F67J60!» (прим.: контроллер из линейки PIC18, имеющий максимально возможный объем ROM = 128Кб). Это результат непродуманного выбора контроллера на этапе планирования, если этот этап вообще был проведен.
Так же надо учесть, что при отладке программы нам потребуются кое-какие ресурсы (об этом речь пойдет ниже).
![]()
Предусмотреть смену платформы или компилятора
Здесь речь, конечно, не о том, что нужно напичкать программу директивами условной компиляции, позволяющими максимально эффективно использовать возможности каждого компилятора, на который, возможно, придется переносить программу. Речь как раз о том, чтобы:
-
минимально использовать уникальные особенности конкретного компилятора, а те куски кода, которые все-таки так пишутся, блокировать условными директивами (бывает, что компилятор простую операцию развернет черт те во что, а – кровь из носа — хочется сделать кратко и красиво);
-
не использовать недокументированные особенности компилятора; некоторые операции могут быть реализованы различным способом, например, операция сдвига влево может после своего выполнения оставить флаг переноса, а может и изменит его, либо, выполнив оптимизацию, заменит инструкцию сдвига чем-нибудь, либо в качестве результата возьмет один из промежуточных результатов, получившихся при вычислении предыдущего выражения. В общем, нет гарантии, что флаг переноса будет установлен правильно.
-
переопределять типы данных. Стоит учитывать, что знаковость и размерность в стандарте языка определены для каждого типа довольно расплывчато (например, в HT-PICC18 тип char по умолчанию беззнаковый, в то время как в MPLAB C18 – знаковый; или в CCS тип int – 8-битный беззнаковый, а в остальных компиляторах – 16-битный знаковый). Поэтому в каждом проекте хорошо бы иметь h-файл с переопределениями типов
#if defined(__PICC__) || defined(__PICC18__) typedef signed char S08; typedef signed int S16; typedef signed long S32; typedef unsigned char U08; typedef unsigned int U16; typedef unsigned long U32; typedef bit BOOL; typedef signed char S_ALU_INT; typedef unsigned char U_ALU_INT; #endif
Обратим внимание на два типа: S_ALU_INT и U_ALU_INT – это знаковое и беззнаковое целые, имеющие размерность машинного слова для конкретного контроллера. Т.к. операции над операндами, имеющими размерность шины данных, производятся наиболее оптимально, иногда есть смысл пользоваться этими типами данных.
Примечание: далее в тексте для наглядности будут использоваться стандартные типы: char (8 бит), int (16 бит), long (32 бита).
![]()
Написание программы
При написании самого текста программы нужно руководствоваться двумя сводами правил:
Сами правила могут у каждого быть свои, но они должны по возможности исключать разночтения.
![]()
Кодирование
![]()
Соблюдать модульность
Мы уже говорили о разбиении программы на модули, еще раз приведу преимущества модульности:
-
Мобильность (легкий перенос модуля в другую программу)
-
Наглядность (легкий поиск определений конкретных функций)
-
Заменяемость (замена одного модуля другим при изменении условий работы, например, при смене внешнего оборудования)
Раз мы решили разбить программу на модули, то нужно следовать этому решению до конца и не совершать каких-либо действий, нарушающих модульность. Т.е. наши модули должны обладать следующими характеристиками:
-
Самобытность
Функции и переменные, относящиеся к одному модулю, определять именно внутри этого модуля. Понятно, что иначе перенос модуля в другую программу обернется тем, что в каждой новой программе придется переопределять недовнесенные переменные. -
Самодостаточность
Не использовать в модуле внешние переменные из верхних модулей. Опять же, причина в том, что при переносе модуля в другую программу придется в новой программе не только доопределять какие-то переменные, но и восстанавливать механизмы их работы с тем, чтобы модуль вел себя правильно. -
Гибкость в настройке
Например, если это модуль для работы по шине i2c, то при переносе в другой проект должна быть возможность выбирать (или задавать константами) адрес устройства, разрядность адреса данных, выводы, к которым подключено устройство i2c.
![]()
Избегать условностей
В программе следует избегать любых конструкций, которые при прочтении могут быть истолкованы двояко, или которые смогут при определенных условиях повести себя неправильно. Самые частые допуски, которые позволяют себе программисты, — это несоблюдение границ использованных типов, путаница со знаковыми и беззнаковыми переменными, пренебрежение приведением типов. Эти допуски рассмотрим в первую очередь.
Типы данных
Нужно определять переменные тем типом, который соответствует их назначению. Например, не следует переменную, которая будет использована как числовая, определять типом char. Число может быть либо signed char либо unsigned char. Сам же char определяет символьную переменную. Понятно, что для контроллера все эти переменные – одно и то же, но для компилятора, а также для человека, читающего текст программы, — это разные вещи.
Например, типичная ошибка:
Неправильно:
char Counter; Counter = 10; if (Counter >= 0) ...;
Это выражение будет правильно обрабатываться в MPLAB C18, в то время как в HT-PICC18 оно всегда будет возвращать true. Все из-за того, что в стандарте языка не оговаривается знаковость типа char, и каждый разработчик компиляторов вправе толковать его по-своему. В приведенном примере переменная должна быть определена так:
Правильно:
signed char Counter; Counter = 10; if (Counter >= 0) ...;
Приведение типов
Не стоит надеяться, что компилятор всегда сам сделает приведение типов в случае, когда в выражении участвуют разнотипные переменные и константы. Всегда следует выполнять приведение типов вручную, исключая разночтения выражения программистом и компилятором.
Неправильно:
int i; void *p; p = &i;
Правильно:
p = (void*)&i;
В конкретном примере мы, скорее всего, получим правильный результат и без приведения типов (хотя, возможны нюансы с однобайтовыми near-указателями для PIC18). Но бывает так, что программист, рассчитывая на автоматическое приведение типов, проморгает его отсутствие в более сложном выражении, например: выражение содержит подвыражения в скобках, в которых типы будут приведены только после выполнения подвыражения, т.е. тогда, когда, например, значимость будет уже потеряна (из-за переполнения).
То же самое относится к передаче параметров в функцию.
Побайтовое обращение к многобайтовой переменной
Пример неправильного обращения:
unsigned char lo, hi; unsigned int ui; ... lo = *((unsigned char*)&ui + 0); hi = *((unsigned char*)&ui + 1);
Дело в том, что стандартом языка не предусматривается порядок чередования байтов в многобайтовых объектах.
Правильное обращение:
lo = ui & 0xFF; hi = ui >> 8;
Определение функций
При определении функции следует указывать полностью входные и выходные типы. Если функция определена просто:
myfunc ()
, то компилятор по умолчанию будет считать, что она возвращает int, и не принимает параметров. Однако не следует оставлять такой неопределенности.
myfunc () // неправильно myfunc (void) // неправильно int myfunc () // неправильно int myfunc (void) // Правильно
Пустые операторы
Не следует в теле цикла while, а также в операторах if…else использовать пустой оператор:
while (!TRMT); // Ожидаем освобождение буфера TXREG = Data;
Нечаянно пропущенная ‘;’ обернется неправильным поведением программы. Лучше вместо пустого оператора ставить continue либо {}:
while (!TRMT) continue; // Ожидаем освобождение буфера TXREG = Data;
Про оператор switch
В операторе switch нужно:
-
Определять ветку
default -
В каждом
caseставитьbreak -
неиспользуемые
breakзакрывать комментариями
switch (...) { case 0x00: ... break; case 0x01: ... // break; // Поставив закомментированный break, мы даем себе понять, // что после обработки условия 0x01 мы хотим перейти к коду // обработки условия 0x02, а не пропустили break случайно case 0x02: ... break; default: // Обязательная ветка, даже если есть уверенность, что // выражение в switch всегда принимает одно из описанных // значений break; // Ветка default также должна заканчиваться break }
Неинициализированные переменные
Нельзя пользоваться неинициализированными переменными в расчете на то, что компилятор сам сгенерит код их инициализации (например, обнулит после сброса).
Скобки в сложных выражениях
В некоторых случаях в сложных выражениях есть смысл расставлять скобки даже тогда, когда есть уверенность в правильности приоритетов операций. Такие выражения легче анализировать, т.к. ошибка может быть не только в приоритетности операций, но и в самом выражении. Также это снижает вероятность внесения ошибки при модификации выражения.
«Такая ситуация никогда не случится!»
На эту тему можно вообще долго говорить. Вот интересный фрагмент определения типа из одной из присланных мне программ:
typedef struct { unsigned int seconds : 6; unsigned int minutes : 6; unsigned int hours : 4; // Неправильно задана размерность } T_CLOCK;
Обратите внимание на размерность полей данной структуры. Под минуты и под секунды выделено по 6 бит, чтобы охватить весь интервал 0..59. А под часы вместо 5 бит, выделено 4. Программист, написавший это, предположил, что т.к. программа будет работать только с 8 утра, то проще выделить 4 бита (покрывая интервал в оставшиеся 16 часов) с тем, чтобы вся структура влезла в два байта, а в самой программе к значению hours всегда прибавлять 8. Надо ли говорить, что сбой не заставил себя должго ждать?
Так что не стоит забывать о первом законе Мерфи: «Если неприятность может случиться, — она случается».
Мертвые циклы
Часто в программах встречаются участки кода, которые потенциально могут привести к зависанию. Самый распространенный пример – ожидание готовности или подтверждения при работе с внешней периферией:
Неправильно:
void lcd_wait_ready (void) { while (!PIN_LCD_READY) continue; }
Если произошла непредвиденная ситуация (обрыв линии, короткое замыкание, конденсат и пр.), то из этого цикла мы никогда не выйдем. (Разве что только WDT сработает). Поэтому нужно всегда предусматривать аварийный выход из таких циклов. Можно это делать с помощью таймера.
Правильно:
char lcd_wait_ready (void) { TMR0 = -100; // Готовим таймер для фиксации таймаута TMR0IF = 0; while (!PIN_LCD_READY) { if (TMR0IF) return 0; // Выходим с кодом ошибки } return 1; // Выходим OK }
Правда, целый таймер выделять для этого иногда накладно, и есть смысл работать с глобальной переменной, которая будет уменьшаться в прерывании по таймеру:
// Фрагмент обработчика прерывания if (TMR0IF && TMR0IE) { TMR0IF = 0; TMR0 -= TMR0_CONST; // Обновляем таймер if (!--g_WaitTimer) // Проверяем переполнение g_Timeout = 1; ... } ... char lcd_wait_ready (void) { g_WaitTimer = 10; // Готовим таймер для фиксации таймаута g_Timeout = 0; while (!PIN_LCD_READY) { if (g_Timeout) return 0;// Выходим с кодом ошибки } return 1; // Выходим OK }
Кстати, заметьте, что в обработчике прерывания проверяется не только флаг конкретного прерывания (TMR0IF), но и бит разрешения (TMR0IE). Дело в том, что в PIC-контроллерах младшего и среднего семейства несколько прерываний могут обрабатываются одним обработчиком. И если у нас прерывание по TMR0 отключено (TMR0IE = 0), а в обработчик мы попали от другого источника (например RCIF), то без проверки битов xxxIE мы обработаем все отключенные прерывания, у которых на момент входа в обработчик оказался установлен флаг xxxIF.
![]()
Не делать длинных и сложных выражений
Такие выражения не только трудно анализировать, но их также трудно тестировать и отлаживать.
Неправильно:
t = sqrt(p*r/(a+b*b+v))+sin(sqrt(b*b-4*a*c)/(1<<SHIFT_CONST));
Представьте, что программа делает вычисления неправильно и есть подозрения, что проблема в этом выражении. А это выражение даже в симуляторе не прогнать. Такие выражения желательно разбивать на несколько подвыражений:
Правильно:
A = p*r; B = a + b*b + v; C = b*b – 4*a*c; D = (1 << SHIFT_CONST); if (B == 0) ...; // Ошибка: «деление на 0» if (C < 0) ...; // Ошибка: «корень из отрицательного числа» E = A/B; If (E < 0) ...; // Ошибка: «корень из отрицательного числа» t = sqrt(E) + sin(sqrt(C)/D);
Теперь наше выражение не только легко читается, но и легко тестируется и отлаживается, а кроме того, – еще и имеет механизм защиты от неправильных входных данных (этот механизм можно было бы оставить и с длинным выражением, но тогда некоторые части выражения пришлось бы пересчитывать дважды).
![]()
Операторные скобки
При написании фрагментов программ, содержащих вложенные циклы или вложенные условные операторы, желательно расставлять операторные скобки даже для однострочных блоков.
Рассмотрим пример одной часто встречающейся ошибки:
Неправильно:
if (A == 1) if (B == 2) C = 3; else C = 4;
Замысел программиста был таков: если A равняется 1, то при B, равном 2, присвоить C значение 3, иначе присвоить C значение 4. Т.е. программист считал, что в C будет занесено значение 4, если A не равно 1. Однако на самом деле компилятор видит это по-другому: else применяется к ближайшему if, а не к тому, который выровнен с ним в тексте. В нашем случае else относится к условию if (b == 2).
Правильно это условие нужно было записать так:
if (A == 1) { if (B == 2) C = 3; } else C = 4;
![]()
Операторы break и continue во вложенных циклах
Часто встречающейся ошибкой является использование break или continue во вложенных циклах или операторе switch в расчете на то, что эти операторы сработают в рамках и внешнего цикла. Вот пример из реальной программы (он немного порезан для наглядности, и ошибка сразу бросается в глаза), который подсчитывал количество положительных и отрицательных единиц в массиве, причем нулевой элемент был признаком конца массива.
Неправильно:
Positive = Negative = 0; for (i = 0; i < MAX_ARRAY_SIZE; i++) { switch (array[i]) { case 0: break; // Выйти из цикла (ошибка, т.к. выйдем // только из switch) case 1: Positive++; break; case -1: Negative++; break; } }
Программист решил использовать для проверки конструкцию switch, в которой, среди прочего, при нахождении элемента со значением 0 счет должен был прерваться. Однако, очевидно, что break в ветке case 0 выведет программу из switch‘а, а не из цикла for.
Есть несколько способов решить эту проблему. Один из вариантов в данном случае – использовать дополнительный if:
Правильно:
Positive = Negative = 0; for (i = 0; i < MAX_ARRAY_SIZE; i++) { if (array[i] == 0) break; // Выйти из цикла switch (array[i]) { case 1: Positive++; break; case -1: Negative++; break; } }
Однако он не очень эффективный, т.к. приводит к повторному вычислению адреса элемента массива при косвенной адресации. Есть и другие варианты решения проблемы. Главное – помнить, что break/continue прерывает/продолжает только текущий цикл (или switch).
![]()
Точность вещественных чисел
Когда появляется необходимость работы с вещественными числами с плавающей запятой, нужно внимательнее изучить теорию об их структуре (мантисса, порядок, знаки). У некоторых программистов, которые с ней не знакомы, при виде диапазона +/- 1.7e38 появляется иллюзия всемогущества и универсальности этого типа данных. При этом из вида упускаются такие важные детали, как потеря значимости, нормирование, переполнение, относительная погрешность.
В одной программе я видел такой фрагмент:
long l; float f; f = 0.0; for (l = 0; l < 100000L; l++) { ...; f = f + 1.0; ...; }
(Примечание: в программе был использован вещественный тип размерностью 24-бита.)
На месте троеточий делались кое-какие вычисления, одним из параметров в которых была переменная f. В этом цикле первые две трети результатов оказывались правильными, а дальше появлялись отклонения, причем, чем дальше, тем сильнее.
А происходило следующее: когда переменная f досчитывала до значения 65536 (т.е. выходила за пределы 16-разрядной мантиссы), ее экспонента (порядок) увеличивалась на единицу. При этом вес младшего разряда мантиссы оказывался равным 2. При выполнении сложения двух вещественных чисел f и 1.0 сперва производится приведение их к общей экспоненте, в результате которого 1.0 превращается в 0, т.к. при сложении в обоих числах порядок выравнивается в большую сторону, т.е. вес младшего разряда мантиссы в обоих операндах будет равен 2, при этом происходит потеря значимости, и результат сложения 65536.0 + 1.0 будет равен 65536.0.
Также стоит отметить, что в общем случае для вещественных чисел нельзя проверять деление умножением.
![]()
Целочисленное деление
Округление
Часто встречается такой допуск при делении целых чисел, будто бы компилятор самостоятельно должен производить округление. Так вот: он этого не делает, это должен делать сам программист. Типичная ошибка, например, при расчете скорости USART’а:
Неправильно:
#define FOSC 200000000L #define BAUDRATE 115200L ... SPBRG = FOSC / (BAUDRATE*16) – 1;
При расчете на бумаге все выглядит красиво:
20000000/(115200*16) – 1 = 9.85
и округляется в большую сторону до 10. Ошибка скорости при этом составляет:
E = |10 - 9.85| / 9.85 * 100% = 1.5%
, что в допустимых пределах.
Однако, когда мы поручаем компилятору вычислить формулу в том виде, в котором мы ее привели, он округление произведет не по правилам математики (<0.5 – в меньшую сторону, >=0.5 – в большую), а просто откинет дробную часть. В результате ошибка будет уже:
E = |9 - 9.85| / 9.85 * 100% = 8.6%
, т.е. в 4 раза превышает допустимую.
Та же проблема всплывает при любых расчетах с целочисленными переменными и константами, где присутствует операция деления.
Для того чтобы округление производилось правильно, нужно к числителю прибавлять половину знаменателя:
Правильно:
SPBRG = (FOSC + BAUDRATE*8) / (BAUDRATE*16) – 1;
В общем случае формула “A = B / C” при использовании целых чисел в программе должна быть записана так:
| A = (B + C / 2) / C; |
|---|
Операцию деления на 2 (в выражении C/2) целесообразно заменять сдвигом вправо на один разряд. Обратите внимание, что деление на 2 – это то же самое целочисленное деление, но выражение записывается C/2 , а не (C+1)/2, т.е. к числителю не прибавляется половина знаменателя. Почему? Не вдаваясь в подробности насчет различия погрешностей при делении на разные значения (в нашем примере деление на 2 и деление на C), приведу тривиальный пример: «разделить 1 на 1». Результат деления должен быть равен 1:
(1 + 1 / 2) / 1 = (1 + 0) / 1 = 1
Если мы при делении на 2 в дроби 1/2 прибавим к числителю половину знаменателя, то получится:
(1 + (1 + 2/2) / 2) / 1 = (1 + 2 / 2) / 1 = (1+1) / 1 = 2
Последовательность делений и умножений
Дополню еще одной рекомендацией: если в выражении присутствуют операции как умножения так и деления, то формулу лучше переписать так, чтобы сперва выполнялись операции умножения, а затем деления:
Неправильно:
A = B / C * D;
Правильно:
A = B * D / C;
Причины очевидны: так как приоритет операций умножения и деления одинаков, то выражение будет вычисляться слева направо, причем округление будет выполняться после каждой операции. Таким образом, в первой формуле на D будет умножено не только отношение B/C, но еще и ошибка округления.
Рассмотрим пример: «2 / 3 * 3». Результат выражения должен быть равен 2. Сначала перепишем это выражение по правилам округления, как было описано выше (иначе 2/3 дадут результат 0, и результат всего выражения тоже будет нулевой):
(2 / 3) * 3 -> ((2 + 3/2) / 3) * 3 = ((2 + 1) / 3) * 3 = (3/3) * 3 = 1 * 3 = 3
Как видим, мы получили неправильный ответ. Почему? Потому что на 3 была умножена еще и ошибка округления отношения 2/3. Ошибка была равна 1/3, и, помножив ее на 3, мы получили лишнюю 1 (проблема произойдет также и при округлении вниз). Правильно было сначала произвести умножение, а потом деление, т.е. «2*3/3»:
(2 * 3) / 3 -> (2 * 3 + 3/2) / 3 = (6 + 1) / 3 = 7 / 3 = 2
Есть один тонкий момент – это переполнение, которое при перемножении нескольких чисел может возникнуть еще до того, как придет очередь до операторов деления. Но это можно предусмотреть на этапе разработки, взяв для вычислений числа большей разрядности.
![]()
Правила для констант
Не использовать числовые константы
Речь идет о неиспользовании числовых констант в оперативной части кода. Например, в программе предполагается использовать массив размерностью 25 элементов. Не следует по всему тексту программы явно указывать константу 25.
Пример неправильного подхода:
char String[25]; ... for (i = 0; i <= 24; i++) String[i] = ‘ ‘;
Правильно в одном месте программы определить константу, а потом в тексте оперировать только ее именем:
#define STRING_SIZE 25 ... char String[STRING_SIZE]; ... for (i = 0; i <= STRING_SIZE - 1; i++) String[i] = ‘ ‘;
Дело в том, что если по каким-то причинам придется изменить размерность массива, то придется и по всему тексту программы выискивать все относящиеся к размерности фрагменты и исправлять их. Пропустив всего один такой фрагмент, можно получить редко проявляющийся но довольно разрушительный баг. (Обратите внимание на то, что применен оператор «<= 24», а не «< 25»; я специально сделал для примера такой вариант, чтобы было понятно, что при изменении размерности массива простой поиск с заменой может не дать полноценного результата.)
Поэтому всем константам, не являющимся неоспоримыми (например, в минуте 60 секунд, в килобайте 1024 байта, при переводе в десятичную систему всегда число делим на 10 и т.д.), следует давать имена и в программе работать только с именованными константами.
Указывать тип константы
Неправильно:
#define FOSC 4000000 #define MAX_INTERATIONS 10000 #define MIDDLE_TEMPERATURE 25
Если с определением FOSC сомнений не возникает (компилятор однозначно поймет, что это 32-битная константа), то с MAX_ITERATIONS будут проблемы. Если где-нибудь в коде встретится выражение:
(MAX_ITERATIONS * 10)
, то результатом его будет не 100000, а… -31072. Почему? Потому что по умолчанию константа будет рассматриваться как знаковое 16-разрядное целое. Результат 100000 выходит за границы 16 разрядов, поэтому он будет обрезан до 0x86A0, что соответствует -31072.
То же самое касается констант, которые должны быть вещественными. Если в программе встретится выражение:
(MIDDLE_TEMPERATURE / 26)
, то результатом будет 0, а не предполагаемые 25/26 = 0,96.
Правильно:
#define FOSC 4000000L #define MAX_INTERATIONS 10000L #define MIDDLE_TEMPERATURE 25.0
Задавать константам осмысленные значения
Вот пример из реальной программы:
#define BAUDRATE 24 // 9600
В функции инициализации периферии была такая строчка:
SPBRG = BAUDRATE;
Программа должна была работать с тактовой частотой 4 МГц. А для такой тактовой частоты константа BAUDRATE должна иметь значение 25, а не 24. Таким образом, ошибка скорости составила 4%, что, в общем-то, почти на грани допустимого. В результате иногда принимались не те данные, которые ожидались. В разговоре с программистом выяснилось, что ранее программа работала по USART на скорости 19200 (константа BAUDRATE=12), но потом из-за смены внешнего оборудования пришлось изменить скорость на 9600, что программист и сделал, умножив константу на 2.
Но беда еще и в том, что даже с комментарием «9600» такое определение константы может заставлять задумываться. Ведь если при отладке выясняется, что что-то не так с приемом/передачей по USART, то эту константу придется проверять по формуле. Не говоря уже о том, что при выборе другой скорости или при смене тактовой частоты константу придется пересчитывать. И не надо забывать, что в программу может заглядывать не только автор, а для чужого человека заглядывание в подобный код равносильно написанию собственного.
Понятное дело, что в нашем примере программист просто ошибся с формулой (т.к. должен был сперва прибавить 1, потом умножить на 2, а затем отнять 1), но ошибки можно было бы избежать, если бы константа задавалась осмысленной:
#define FOSC 40000000L #define BAUDRATE 9600L
А уже при присваивании регистру SPBRG переводить эту константу в нужный вид с учетом тактовой частоты, также заданной в виде константы.
SPBRG = ((FOSC + BAUDRATE*8) / (BAUDRATE*16) – 1;
Итак, константы лучше задавать в том виде, в котором мы привыкли их видеть, т.е.:
-
время задавать в секундах, а не в тиках 65536 мкс;
-
давление – в паскалях (или в барах), а не в единицах АЦП;
-
Напряжение – в вольтах;
-
температуру – в градусах;
-
частоту – в герцах.
Это, во-первых, сделает программу более читабельной, а во-вторых, поможет избежать ошибок, которые будут являться следствием пересчетов из одной системы в другую. Правильнее один раз настроить формулу преобразования, чем каждый раз по ней же пересчитывать константы.
Два слова о проверке правильности задания констант
Задавая константу в понятном для нас виде, хотелось бы одновременно быть уверенным в том, что ее значения не выходят за рамки возможностей контроллера. Например, BAUDRATE из нашего примера должна обеспечивать точность скорости +/- 2%. Или давление, которое мы задаем в барах, должно быть таким, чтобы при переводе его в единицы АЦП получилось значение в пределах 1023. Поэтому в программе нужно блокировать неправильно заданные константы условными директивами и сообщениями об ошибке. Например:
// Задание параметров #define FOSC 4000000L #define BAUDRATE 9600L // Вычисление ошибки (в процентах) #define SPBRG_CONST ((FOSC + BAUDRATE*8) / (BAUDRATE*16) - 1) #define REAL_BAUDRATE ((FOSC + (SPBRG_CONST+1)*8)/((SPBRG_CONST + 1)*16)) #define BAUDRATE_ERROR ((100L * (BAUDRATE - REAL_BAUDRATE) + BAUDRATE/2) / (BAUDRATE)) // Проверка ошибки на диапазон -2%..+2% #if BAUDRATE_ERROR < -2 || BAUDRATE_ERROR > 2 #error "Неправильно задана константа BAUDRATE" #endif
Выглядит сложно, но сложность компенсируется тем, что эта формула должна быть проверена и отлажена один раз.
Примечание. В компиляторах HTPICC и HTPICC18 проверка константы BAUDRATE_ERROR директивой #if работать не будет (из-за ошибки компилятора). Проверку нужно делать либо в runtime’е, либо использовать другую формулу.
Соблюдать систему счисления
При задании константы нужно соблюдать ту систему счисления, которая подходит константе по сути. Бывает, делают так:
Неправильно:
TRISA = 21; // RA0,RA2,RA4 – вход, RA1, RA3 - выход TRISB = 65; // 65 = 0x41 = 0b01000001
В данном случае нужно задавать константу именно в бинарном виде (хотя, надо помнить, что бинарная запись числа не предусмотрена стандартом Си; тем не менее, почти все компиляторы для PIC’ов такую запись понимают). Каково будет программисту поменять один бит в такой записи?
Правильно:
#define TRISA_CONST 0b00010101 // RA0,RA2,RA4 – входы #define TRISB_CONST 0b01000001 // RB0, RB6 - входы ... TRISA = TRISA_CONST; TRISB = TRISB_CONST;
В этом случае четко видно, где единицы – там входы, нули выходы.
Также часто встречается довольно нелепая запись:
Неправильно:
TMR1H = 0xF0; TMR1L = 0xD8; // Отсчет 10000 тактов
Хорошо еще, если ее снабдят комментариями, хотя, как мы убедились на примере с BAURDATE, комментарий не гарантирует правильности константы. Опять же большие трудности возникают при пересчете констант. В данном случае нужно пользоваться именно макросом (тут есть тонкость для контроллеров PIC18: TMR1H – это буферный регистр, и нам важна последовательность присваивания: сначала старший, затем – младший; стандартом языка последовательность не предусмотрена).
Правильно:
#define TMR1_WRITE(timer) { TMR1H = timer >> 8; TMR1L = timer & 0xFF; } ... TMR1_WRITE(-10000);
![]()
Заключать константы и операнды макросов в круглые скобки
Типичная ошибка при определении числовых констант в виде выражения – не использование скобок.
Вот пример неправильного определения:
#define PIN_MASK_1 1 << 2 #define PIN_MASK_2 1 << 5 ... PORTB = PIN_MASK_1 + PIN_MASK_2;
Данное выражение развернется компилятором в такое:
PORTB = 1 << 2 + 1 << 5;
Вспомним, что приоритет операции «+» выше, чем приоритет сдвига, и получим выражение:
PORTB = 1 << (2 + 1) << 5 = 1 << 8
Т.е. совсем не то, что мы ожидали. Ошибки можно было бы избежать, взяв выражения при определении констант в скобки, т.е.
правильное определение:
#define PIN_MASK_1 (1 << 2) #define PIN_MASK_2 (1 << 5) ... PORTB = PIN_MASK_1 + PIN_MASK_2;
Транслируется в:
PORTB = (1 << 2) + (1 << 5);
Из этой же области часто совершаемая ошибка – не заключение в скобки операндов макросов. Например, имеем макрос:
Неправильно:
#define MUL_BY_3(a) a * 3
Выглядит просто и красиво, однако, попробуем вызвать макрос так:
i = MUL_BY_3(4 + 1);
И вместо предполагаемого результата 15 получим результат 7. Дело в том, что макрос развернется в следующее выражение:
i = 4 + 1 * 3
Ошибки можно было бы избежать, взяв аргумент макроса в скобки:
Правильно:
#define MUL_BY_3(a) (a) * 3
Тогда выражение примет вид:
i = (4 + 1) * 3;
![]()
Заключать тела макросов в фигурные скобки
Тематика схожа с предыдущей. Рассмотрим пример:
Неправильно:
#define I2C_CLOCK() NOP(); SCL = 1; NOP(); SCL = 0;
Т.е. выдерживаем паузу в один такт, затем формируем импульс длительностью два такта. Но такое определение может сыграть с нами злую шутку, если макрос будет использоваться внутри условного оператора:
if (...) I2C_CLOCK();
Компилятор развернет макрос следующим образом:
if (...) NOP(); SCL = 1; NOP(); SCL = 0;
Как видно, условием отрезается только один NOP(), а сам импульс все-таки формируется. Ошибки можно было бы избежать, взяв тело макроса в фигурные скобки:
Правильно:
#define I2C_CLOCK() do { NOP(); SCL = 1; NOP(); SCL = 0; } while (0)
Такие ошибки крайне трудно отслеживать, т.к. на вид все выглядит правильно, и ошибку будем искать перед условием, после условия, в выражении условия, но не в I2C_CLOCK().
Обратим внимание, что использована конструкция do {…} while (0). Если бы мы ее не использовали, то
постановка else в нашем условии:
if (...) I2C_CLOCK(); else return;
привела бы к сообщению компилятора об ошибке «inappropriate else». Все дело в том, что мы перед else и после ‘}’ ставим ‘;’, которая воспринимается компилятором как конец оператора if. Поэтому и использованы скобки в виде do {…} while.
![]()
Правила для функций
Объявлять прототипы для всех функций
Для любой функции, объявленной в модуле, нужно объявлять прототип в начале файла с тем, чтобы не задумываться при вызовах, где функция определена: выше вызова или ниже. Кроме того, при исследовании исходного текста программы это сразу дает общую картину: какие функции есть в модуле, какие параметры они принимают и какие значения возвращают. Вдобавок это позволяет сгруппировать наиболее значимые функции в начале файла, а все вспомогательные определить где-нибудь внизу, чтобы не мешались.
В заголовочный же файл нужно выносить прототипы только тех функций, которые будут вызываться из других модулей.
Проверять входные аргументы функций на правильность
Перед выполнением каких-либо операций с данными нужно убеждаться в их правильности:
-
Инициализированные указатели;
-
Попадают в область допустимых значений (например, номер элемента в массиве должен быть меньше размерности массива, чтобы не произошла запись в стороннюю ячейку); строка, содержащая имя, не может состоять из цифр.
-
Соответствуют реальности (например, счетчик битов в байте не может быть больше 8; температура в комнате не может быть -128 градусов Ц);
Часто область допустимых значений и соответствие реальности – это одно и то же. Однако, есть случаи, когда требуются дополнительные проверки. Например, если параметром является структура, то можно сначала определить, что значение каждого поля в отдельности попадает в область допустимых значений, а потом по совокупности проверять соответствие данных друг другу.
Возвращать функцией код ошибки
Желательно предусмотреть возможность любой функцией возвращать код ошибки. Например, при неправильных входных данных, при ошибке в вычислениях (деление на ноль, переполнение), при ошибке работы с внешними устройствами. Причем, учитывая, что сама ошибка может произойти на самом нижнем уровне вложенных функций, нужно предусмотреть возможность передачи значения ошибки наверх.
Для возврата кода ошибки иногда удобно пользоваться неиспользуемой результатом области значений. Но есть функции, возвращающие результат, который может принять любое значение из множества значений используемого типа. Например, функция перемножения двух чисел, или функция чтения байта из EEPROM. Также может вызвать трудности ситуация, когда вложенные функции возвращают результаты разных типов, что может помешать сквозной передаче кода ошибки. В таких случаях есть смысл пользоваться глобальной переменной. Однако, такой вариант затруднителен при использовании сторонних библиотек.
Все коды ошибок должны быть предопределены константами. Нежелательно пользоваться для их определения конструкцией enum с неинициализированными значениями, т.к. после первого релиза все будут снабжены спецификацией, где ошибки будут расписаны по номерам, а в следующей версии будет добавлен еще один код ошибки (втиснут куда-то в середину списка), из-за чего половина констант изменят свое состояние. Поэтому их нужно определять либо через #define, либо через инициализированный список перечислений:
enum ENUM_ERROR_CODES { // Математические ошибки ERROR_DIV_BY_ZERO = 0x100 ERROR_OVERFLOW, ERROR_UNDERFLOW, ... // Ошибки работы с EEPROM ERROR_EEPROM_READ = 0x110 ERROR_EEPROM_WRITE, ERROR_EEPROM_INIT, ... }
Следует отметить, что коды ошибок, генерируемые функциями, — это не те ошибки, которые можно показывать пользователю. Например «ДЕЛЕНИЕ НА НОЛЬ» на экране стиральной машины приведет хозяйку в панику, если внутри ее любимая блузка. Я уж не берусь предугадать действия суеверного человека, если ему вывести шестнадцатеричное представление числа 57005.
Не делать очень больших функций
Эта рекомендация схожа с рекомендацией «Не делать длинных выражений». Если функция получается длинной, то есть смысл разбить ее на несколько функций. Это даст нам следующие преимущества:
-
упростит внутреннюю логику функции;
-
сделает ее более читабельной;
-
упростит тестирование и отладку.
![]()
Использовать сторожевой таймер
Сторожевой таймер в контроллерах имеет три применения:
-
пробуждение контроллера из режима SLEEP с заданным инетервалом;
-
произведение аппаратного сброса при зависании программы.
-
Для PIC-контроллеров младшего семейства – выполнение программного сброса
Рассмотрим для начала второе применение, т.е. использование его в качестве дополнительного механизма защиты от зависания. Понятно, что лучше создавать правильные независающие алгоритмы и описывать их правильными независающими программами, но, к сожалению, часто даже в отлаженной и переотлаженной программе могут скрываться ошибки, которые при определенном стечении обстоятельств приведут к зависанию. Вдобавок можно сказать, что сложные программы с большим количеством состояний и параллельных процессов бывает сложно отладить и протестировать полностью. Полное тестирование таких программ может затянуться на время, превышающее экономически целесообразные сроки выпуска устройства. В таких случаях приходится идти на некий компромисс между полнотой теста и сроками выпуска, т.е. программа может выйти, грубо говоря, недоотлаженной. Это не значит, что она будет сбоить на каждом шагу и выдавать какие-то результаты, не соответствующие спецификации. Это значит, что при определенных условиях (чаще при совокупности внештатных ситуаций) возможно неадекватное поведение программы. И здесь нас может выручить сторожевой таймер, который не даст программе зависнуть наглухо. Конечно, он не является панацеей от неправильно составленного или неправильно запрограммированного алгоритма. Он всего лишь перезапустит программу, но не исправит допущенной ошибки. Тем не менее, с ним, по крайней мере, есть возможность восстановить работоспособность устройства.
Когда нужно обрабатывать WDT
Во многих программах вижу «интересный» прием программистов: в битах конфигурации включали WDT, а в самой программе сбрасывали его везде, где попало, лишь бы не произошло переполнение: и в главном цикле программы, и в прерывании, и в функции задержки. Сделают так – и радуются: «Ай, какую я надежную программу написал! С вочдогом!» Этот подход эквивалентен подходу без использования WDT с той разницей, что у программиста появляется еще одна иллюзия по поводу отказоустойчивости его программы.
Задача сброса WDT совсем нетривиальна, в каждой конкретной программе нужен свой алгоритм. В самом простом случае можно завести отдельную переменную, в которой каждая подпрограмма будет устанавливать свой бит, а отдельная подпрограмма обработки WDT будет проверять эту переменную, и только в том случае, когда все требуемые биты установлены, будет производиться очистка WDT. Но такой способ подойдет только для несложной программы с небольшим количеством состояний и с ограниченным временем пребывания в одной функции.
Для сложных программ требуются разработки индивидуальных алгоритмов, которые бы отслеживали не только факт выполнения каких-то функций, но также следили за тем, чтобы функции выполнялись в правильной последовательности, и чтобы время выполнения каждой функции было в пределах допустимого.
Здесь хотел бы пару слов сказать про третье применение WDT, т.е. программный сброс в контроллерах младших семейств, т.к. они не имеют отдельной инструкции, вроде RESET в PIC18. В системах с повышенными требованиями по надежности программа должна иметь механизмы контроля правильности работы. Т.е. следить за стеком, за порядком действий, временами выполнения отдельных узлов, настройками периферийных модулей и т.д. При обнаружении отклонений, которые не могут быть исправлены на лету (например, замечено, что в функцию попали не через вызов CALL, а каким-то другим путем), единственный выход – это сброс. Но если в контроллерах среднего и старшего семейств есть инструкции, выполняющие сброс, то в контроллерах младшего семейства единственный способ выполнить сброс программно – это дать WDT досчитать до конца.
Что делать, если произошел сброс по WDT
Порядок действий при сбросе контроллера (не только по WDT) — это отдельная тема (довольно большая). Здесь опишу только в двух словах.
Сделать нужно две вещи:
-
Восстановить работу (по возможности сделать это незаметным для пользователей)
-
Выяснить причину сброса.
С первым все понятно: все переменные, отвечающие за текущий режим работы, за состояние процессов, какие-то текущие рабочие данные и пр. должны быть определены в неинициализируемой части RAM, т.е. в той, в которую код стартапа ничего не пишет при сбросе. Для HT-PICC такие переменные должны быть определены с квалификатором persistent:
persistent unsigned char Mode; persistent unsigned int LastData[10];
Для MPLAB C18 они должны быть определены в секции udata, т.е. не инициализироваться при определении.
В самом начале функции main нужно проверять причины сброса (биты POR, BOR, TO, PO, RI и пр.), и в зависимости от их состояния принимать решение о том, восстанавливать ли прежний режим работы, начинать ли все с нуля, переходить ли в аварийный режим и т.д.
Теперь о выяснении причин сброса. Здесь многое зависит от стадии разработки устройства и его доступности. В зависимости от того, отлаживаем ли мы устройство, тестируем ли в реальных условиях или же устройство в эксплуатации, в зависимости от доступности самого устройства разработчику, от способности самого устройства известить о несанкционированном сбросе, от средств его связи с внешним миром и пр. факторов – средства выяснения причин могут быть различными. Мы не будем говорить о технике получения данных, которые нам смогут помочь установить причину сброса, из контроллера. Это может быть что угодно: сброс данных в отдельную страницу внешней EEPROM, передача их через какой-нибудь интерфейс для протоколирования, отображение на мониторе (или ЖКИ) и т.д. Я только укажу, какие данные могут быть полезными в общем случае:
-
Содержимое стека
-
Значения регистров указателей (FSR)
По этим данным зачастую можно сделать вывод о том, в каком месте произошел сбой. При использовании компиляторов от microchip для получения этих данных придется писать свой код startup, т.к. фирменная функция заранее предустанавливает регистры FSR (WREG14, WREG15 для MCC30). В каждом частном случае могут понадобиться дополнительные данные: текущий режим, какие-то индикаторы обработки критических участков кода и пр. Чем больше будет данных, тем проще будет анализировать причину сброса. Но нужно также искать некий компромисс, чтобы не загромождать дамп всякой ерундой, а еще, чтобы не дать пользователю запаниковать, если устройство уже в эксплуатации.
![]()
Два слова об операторе GOTO
Многие авторитетные источники строго не рекомендуют использовать оператор goto при написании программ на языках высокого уровня. Основными недостатками его применения называется сильное ухудшение читабельности текста программы и нарушение ее структурности. Да и вообще неизвестно, через что мы перепрыгиваем, выполняя goto (может быть через объявление переменной). Кроме того, часто упоминается то, что формально доказано, что любая программа, использующая goto, может быть переписана без его использования с полным сохранением функциональности. Доводы весьма убедительны, а небезызвестный Дейкстра свою статью «Доводы против оператора goto» вообще начинает с тезиса «… квалификация программистов – функция, обратно зависящая от частоты появления операторов goto в их программах».
Сам я не люблю использовать этот оператор и испытываю большие трудности с анализом чужого кода, где он применяется. Однако, применительно к микроконтроллерам с ограниченными ресурсами я бы оправдал использование goto в некоторых случаях.
Выход из вложенных циклов
Этот пример приводится чаще всех остальных. Действительно, использование оператора goto выглядит довольно простым (и наглядным) решением для выхода из циклов вида (удобны, например, при поиске вариантов решений в многомерных массивах):
for (i = 0; i < 10; i++) { for (j = 0; j < 15; j++) { if (...) goto BREAK_LOOP; } } BREAK_LOOP:
В принципе, при чтении такого кода не вызывает трудностей найти метку, т.к. по смыслу операции понятно, что она внизу, после закрывающей скобки верхнего цикла. Ярые противники goto приводят два варианта альтернативного кода, позволяющего избавиться от этого оператора.
Вариант 1 – переписать цикл в виде функции.
void loop_func (void) { int i, j; for (i = 0; i < 10; i++) { for (j = 0; j < 15; j++) { if (...) return ; } } }
Вариант 2 – использовать переменную-флаг.
bool StopLoop = false; for (i = 0; i < 10 && !StopLoop; i++) { for (j = 0; j < 15 && !StopLoop; j++) { if (...) { StopLoop = true; break; }; } }
(В принципе есть еще альтернативы, но они контекстно-зависимые и в общем случае применимы не во всех случаях)
Оба варианта полностью работоспособны, однако имеют свои небольшие недостатки, когда речь идет о работе с микроконтроллерами, имеющими дефицит ресурсов. Первый вариант не очень удачен, поскольку требует дополнительный свободный уровень стека (помним, что в PIC16 их всего 8, а в PIC18 — 32), что иногда может оказаться критичным. Второй вариант требует использования дополнительной переменной, что также существенно для контроллеров с малым ОЗУ. Т.е., применяя goto, мы имеем возможность сэкономить ресурсы контроллера. (Об экономии скорости я здесь не говорю, поскольку на фоне цикла из 10×15=150 итераций лишний вызов/возврат или две лишних проверки флага StopLoop будут несущественны).
«Стандартные» метки
Лично я позволяю себе использовать метки, которые могут считаться универсальными почти для любого случая. Таких меток немного. Типичный пример – выход из функции при обнаружении ошибки в ходе ее выполнении. Ошибку функция может обнаружить на любом этапе своего выполнения (как при проверке аргументов на правильность, так, например, и при работе с внешней периферией, и при проверке контрольных сумм и т.д.), а при выходе ей требуется освободить занимаемые ресурсы и установить флаг возникновения ошибки, так что обычный return нас может не устроить просто потому, что перед каждым return придется выполнять одну и ту же последовательность действий.
Главное для меня – местоположение таких меток всегда однозначно (например, понятно, что метка, куда переходит функция при обнаружении ошибки, находится в конце функции), их использование безопасно и с точки зрения экономии ресурсов целесообразно (не любой алгоритм удобно программировать приемами структурного программирования, есть случаи, когда такие приемы делают код менее читабельным и более ресурсоемким).
Оптимизация
Некоторые операции, такие как расчеты или работа с быстрыми сигналами, требуют оптимизации кода по скорости. В таких случаях я предпочитаю использовать операторы goto вместо if…else, break, continue и пр. из соображений экономии времени выполнения, даже в ущерб наглядности. Такие участки кода должны быть тщательно проверены и перепроверены и детально откомментированы.
![]()
Атомарный доступ
Часто причиной ошибки в программах может быть непредусмотренный механизм атомарного доступа к регистрам или переменным. Самый простой пример: на 8-битном контроллере имеем 16-битную переменную, которая обрабатывается как в основной программе, так и в обработчике прерывания. Конфликты при работе с ней могут возникнуть, если во время обращения к ней из основного тела программы возникает прерывание, обработчик которого также захочет с ней поработать. Это нестрашно, когда и там и там к переменной обращаются для чтения. А вот если в одном из кусков кода (или в обоих) производится запись, то могут возникнуть проблемы.
unsigned int ADCValue; // Результат чтения АЦП (производится в // прервании ... // Фрагмент обработчика прерывания If (ADIF && ADIE) { ADIF = 0; ADCValue = (ADRESH << 8) | ADRESL; // Читаем последнее измерение ADGO = 1; // Запускаем следующее } ... // Фрагмент основного тела программы Data[i] = ADCValue; // Примечание: Data[] – массив uint'ов
Я думаю, не нужно пояснять, что произойдет, если в момент чтения ADCValue в основной программе (а чтение произойдет в два этапа: сначала младший байт, затем старший), произойдет прерывание по завершению измерения ADC? В двух словах: на момент начала чтения переменная содержала значение 257 (0x101). Первым считается младший байт и скопируется в младший байт элемента массива Data[i]; далее произойдет прерывание, и в ADCValue запишется вновь измеренное значение напряжения, которое с момента последнего изменение стало, например, меньше на 3 единицы младшего разряда, т.е. 254 (0x0FE). Возвращаемся из прерывания и продолжаем копировать ADCValue в Data[i]; нам осталось скопировать старший байт, а он стал равным 0. Вот и получается, что в Data[i] окажется значение 0x001.
Часто встречал у людей недопонимание методов борьбы с этим явлением. Многие программисты считают, что их спасет квалификатор volatile, т.е. достаточно определить переменную, к которой есть доступ и в основном теле программ и в прерывании так:
volatile unsigned int ADCValue;
— и проблема будет решена автоматически на уровне компилятора. Однако, это не так. Квалификатор volatile всего лишь сообщает компилятору, что не нужно производить оптимизацию кода с участием этой переменной (подробнее о volatile читайте [9]). А это в свою очередь даст возможность программисту блокировать прерывания на время обращения к ней, но делать это надо вручную:
di(); Data[i] = ADCValue; ei();
Более детально про атомарный доступ рекомендую почитать [6].
![]()
Оформление
![]()
Удобный инструментарий
Очень важная составляющая успешного программирования – инструментарий. Применительно к написанию текста программы – это в первую очередь текстовый редактор. Если он удобный, функциональный и имеет интуитивно понятный интерфейс, то форматирование будет производиться легко и непринужденно. Помимо самого ввода текста, редактор может обеспечить нам:
-
автоматические отступы;
-
замену символа табуляции пробелами;
-
подсветку синтаксиса;
-
контекстную подстановку;
-
перекрестные ссылки внутри исходного текста или целого проекта;
-
вызов компилятора для сборки проекта из редактора
(Рекомендую SlickEdit).
![]()
Именование идентификаторов
Задавая имена переменным, функциям, константам, типам, перечислениям, макросам, файлам и пр., есть смысл следовать некоторым правилам:
-
Имя должно быть осмысленным (не i, а Counter)
-
Имя должно быть содержательным (не Counter, а BitsCounter)
И ниже приведем кое-какие отдельные правила именования различных объектов программы.
Именование функций
Имя функции внутри модуля, которую предполагается вызывать из других модулей, должно начинаться с префикса, обозначающего имя модуля. Зачем это нужно? Например, в одной программе вы используете память 24LC64, для которой определяете функцию write_byte(). Потом вы написали другую программу, которая работает с внутренней EEPROM контроллера, и для нее тоже определили функцию write_byte(). А потом понадобилось сделать проект, в котором будет использоваться и внешняя EEPROM, и внутренняя. Тут-то вы и столкнетесь с последствиями неправильного именования, потому что из-за одинаковых имен модули нельзя будет объединить в одной программе. Поэтому в самом начале нужно было предусмотреть префиксы имен функций (а запись байта – это операция универсальная, она есть в работе и с дисплеем, и с модемом и еще с чем угодно).
i2c_write_byte – для работы с памятью 24LC64;
eeprom_write_byte – для работы с внутренней EEPROM;
lcd_write_byte – для работы с LCD и т.д.
Кроме того, имя функции должно быть кратким и, по возможности, должно соответствовать системе именования: <модуль>_<действие>_<объект>[_<суффикс>] (могут быть в другом порядке, могут разделяться символом “_”), где:
<модуль>_<действие>_<объект>[_<суффикс>]
-
модуль – имя (или сокращенное имя) модуля, в котором определена функция;
-
действие – глагол, определяющий назначение функции (write, read, check, count и т.д.)
-
объект – существительное, определяющее параметрическую составляющую функции (byte, checksum, string, data и пр.)
-
суффикс – необязательное поле, отражающее какую-либо дополнительную характеристику функции (rom, timeout).
Конечно, все имена функций под одну гребенку подвести довольно трудно, и обязательно в любой системе именования будут исключения. Но не нужно называть функции так:
Неправильные имена функций:
CopyOneByteFromROMToRAM();
Check();
CompareAndGetMax();
В заключение надо сказать, что для некоторых функций можно оставить зарезервированные имена: atof(), init(), printf() и т.д.
Именование констант
-
Заглавными буквами
-
Слова разделяются символом ‘_’
-
Префикс в виде имени модуля или функционального назначения
// Определения параметров шины i2c #define I2C_DEV_ADDR 0xA0 #define I2C_ADDR_WIDTH 16 // Определения цветов RGB #define CL_RED 0xFF0000 #define CL_YELLOW 0xFFFF00 #define CL_GREEN 0x00FF00
Именование типов
-
Заглавными буквами
-
Слова разделяются символом ‘_’
-
Префикс в виде «T_», «TYPE_» и т.п.
typedef struct { unsigned long seconds : 6; unsigned long minutes : 6; unsigned long hours : 5; } T_CLOCK;
Именование переменных
-
Слова начинаются с заглавной буквы
-
Пишутся без разделителя
unsigned char BytesCounter; signed long XSize, YSize;
О «венгерской нотации»
Некоторые используют систему именования, в которой каждой переменной приписывается префикс, показывающий ее тип. Это часто может оказаться полезным при анализе чужого (а часто и собственного) кода. Например:
for (Counter = 0; Counter < 40000; Counter++) ...;
В данном примере мы не можем точно сказать, правильно ли у нас использована переменная в данном цикле или нет. Переменная Counter может быть, во-первых, 8-битной; во-вторых, она может быть знаковой (т.е. всегда будет меньше 40000). И для того, чтобы определить правильность использования переменной, нам нужно найти определение переменной в файле. Но если мы изначально предусмотрели в имени переменной ее тип, то это избавит нас от проделывания лишней работы:
for (wCounter = 0; wCounter < 40000; wCounter++) ...;
Теперь, глядя на эту запись, мы точно можем сказать, что здесь нет ошибки.
Также системой именований можно предусмотреть область видимости переменной.
Префиксы:
-
Префикс области видимости
-
Без префикса – локальная или параметр функции
-
s_— статическая -
m_— локальная для модуля -
g_— глобальная -
i_— Обрабатывается в прерывании
-
-
Префикс типа
-
uc– unsigned char -
sc– signed char -
ui– unsigned int (n) -
si– signed int (w)
-
И т.д.
Имя нашей переменной может выглядеть так:
static unsigned char s_ucRecCounter;
Встречая ее в любом месте функции, мы сразу понимаем, что:
-
Эта переменная предназначена для подсчета принятых байтов;
-
Эта переменная имеет тип unsigned char, т.е. может принимать значения 0..255;
-
Эта переменная статическая, т.е. сохраняет свое значение после выхода из функции.
Примечание. Можно для себя иметь некоторый набор зарезервированных имен для переменных общего назначения, которые встречаются наиболее часто. Например: i, j – signed int; a, b – char; f — float; и т.д. Но эти имена желательно согласовывать, во-первых, с применяемыми именами в литературе, а во-вторых, внутри собственной команды разработчиков, чтобы не было так, что у одного i – signed int, а у другого i – unsigned int.
Преимущества венгерской нотации:
-
Предотвращает ошибки использования типов
-
В большом коде помогает не запутаться в переменных
-
Упрощает чтение чужого кода
Недостатки венгерской нотации:
-
Ухудшают читабельность кода
-
Выражение из 3-4 переменных уже трудно читается
-
Префикс может получиться очень длинным
-
-
Изменение типа переменной влечет изменение ее имени во всех файлах
-
Префикс не дает гарантию правильности задания типа, из-за чего может получиться ложная уверенность в корректности применения переменной:
static signed char s_ucBytesCounter;
![]()
Форматирование текста
Очевидно, что форматирование нужно для того, чтобы программа была более наглядной. Рекомендую в качестве примера ознакомиться с документом an_2000_rus.pdf, где описаны правила форматирования текста программ, сформулированные для сотрудников компании micrium. Не обязательно точно следовать приведенным в нем правилам, но следует посмотреть, на чем сосредоточили внимание авторы документа, и принять это на вооружение:
-
Следовать одному стилю
-
При работе в команде следовать всей командой одним и тем же правилам
-
Не оправдывать отсутствие форматирования нехваткой времени
Я не буду пересказывать этот документ, а только вкратце приведу основные моменты:
Текст файла должен быть разбит на секции
Когда мы берем в руки книгу, мы знаем, что у нее помимо самой содержательной части есть титульные данные, оглавление, выпускные данные, а часто еще алфавитный указатель, список литературы. Кроме того, мы знаем, что каждый элементы каждой из перечисленных групп находится в одном месте, а не разбросаны по всем страницам. Все эти данные упрощают восприятие книги: на титуле в двух словах сказано, о чем (иногда – для кого) эта книга, по оглавлению можно быстро найти интересующую главу, по содержанию – понять содержание и т.д.
Для того чтобы текст программы легче читался, он также должен быть разбит на части (или секции), каждая из которых имеет свое назначение:
-
Заголовок файла (с информацией о назначении файла, авторе текста, используемом компиляторе, дате создания и пр.);
-
Хронологию изменений
-
Секция включаемых файлов
-
Секция определения констант
-
Секция определения макросов
-
Секция определения типов
-
Секция определения переменных (глобальные, затем локальные)
-
Секция прототипов функций (глобальные, затем локальные)
-
Секция описания функций.
Для секций есть свои правила:
-
Каждая секция должна содержать только те описания, которые ей соответствуют
-
Секции должны быть едины, а не разбросаны по всему файлу.
-
Каждой секции должен предшествовать хорошо заметный блок комментария с названием секции.
Горизонтальные отступы
Горизонтальные отступы служат для визуального подчеркивания структуры программы. Я каждый блок операторов делаю с отступом на 4 пробела вправо от верхнего блока.
Вертикальное выравнивание
При определении переменных: типы – под типами, квалификаторы – под квалификаторами, имена переменных – под именами, атрибуты – под атрибутами. В самой программе: при присваивании блока переменных желательно выравнивать знаки «=».
static unsigned char BytesCounter; static int Timer; double Price; char *p, c; ... { BytesCounter = 0; Timer = 0; Price = 1.12; }
Хочу отдельно внимание обратить на то, что ‘*’, показывающая, что переменная является указателем, ставится рядом с переменной, а не с типом. Сравните две записи:
char* p, c; и char *p, c;
Первая запись может быть ошибочно прочитана так: переменные p и c имеют тип char*. На самом же деле указателем будет только p. Во второй записи это наглядно отражено.
Не делать в строке больше символов, чем помещается на одном экране
Например, если функция содержит много параметров, то имеет смысл каждый параметр писать с новой строки. Длинные выражения можно также разбивать на строки.
int sendto ( SOCKET s, const char *buf, int len, int flags, const struct sockaddr *to, int tolen );
Обращу ваше внимание, что при определении функции в нескольких строках правилом вертикального выравнивания стоит пользоваться не в полной мере. Попробуйте переписать эту функцию, ставя квалификаторы под квалификаторами и т.д. Он станет выглядеть довольно безобразно и совершенно нечитабельно, так что в данном случае лучше все определения начинать с одного столбца.
Одна строка – одно действие
Разделять функциональные узлы или конструкции (for, if, …) пустыми строками
Пробелы между операндами и операциями
Ниже пример форматирования по трем последним правилам:
Неправильно:
for(i=0;i<10;i++)a[i]=0; if(j<k){a[0]=1;a[1]=2;}else{a[0]=3;a[1]=4;}
Правильно:
for (i = 0; i < 10; i++) a[i] = 0; if (j < k) { a[0] = 1; a[1] = 2; } else { a[0] = 3; a[1] = 4; }
![]()
Комментирование
Почему не пишут комментарии
-
«Время поджимает, писать некогда»
-
«Это временный код, его не нужно комментировать»
-
«Я и так все запомню»
-
«Моя программа понятна и без комментариев»
-
«В код, кроме меня, никто не заглядывает»
-
«Комментарии делают текст пестрым и затрудняют чтение самой программы»
-
«Я потом откомментирую»
Для кого пишутся комментарии
Комментарий программистом пишется в первую очередь для самого программиста. За отсутствие комментариев приходится платить временем. Чаще — своим, реже – чужим.
Содержание комментариев
Частенько в присланных мне программах вижу, что местами комментарий написан только для того, чтобы он там был. Такое ощущение, что человек знает, что комментарий написать надо, но не знает зачем.
Что должно быть в комментариях:
-
Спецификация функций:
-
что делает;
-
входные и выходные параметры (типы и краткое пояснение);
-
-
Назначение объявляемой переменной, определяемой константы, типа, макроса;
-
Краткое, емкое, безызбыточное описание действия или пояснение к нему;
-
Пометки об изменениях:
-
версия (или дата) и номер пометки.
-
Причины и описание изменения желательно держать в отдельном месте, т.к., во-первых, текст описания причин изменений и производимых действий может получиться громоздким и будет засорять основной текст программы, а во-вторых, одна причина может повлечь за собой изменения нескольких участков программы.
-
-
Указание отладочных узлов и временных конструкций
Пример спецификации функции:
/************************************************************* * * Function: rs_buf_delete * *------------------------------------------------------------ * * description: Удаляем N байт из буфера * * parameters: uchar N – количество удаляемых байтов * * on return: void * *************************************************************/ void rs_buf_delete (uchar N) { ...
Пример пометок об изменениях:
/**************************************************** * Список изменений * ... * Версия 1.6 (22.10.2009): * 1. ... * 2. ... * ... * 8. Иванов И.И., 17.09.2009: В функции * rs_buf_delete добавлена проверка * входного аргумента на 0 * ... ***************************************************/ ... void rs_buf_delete (signed char N) { // *1.6-8* if (N < 0) return; if (N <= 0) return; // *1.6-8* ...
Пример указания отладочного узла:
void rs_buf_delete (signed char N) { if (N <= 0) return; /*D*/ DebugCounter++; /*D*/ PIN_DEBUG = 1; /*D*/ delay_ms(5); /*D*/ PIN_DEBUG = 0; ...
Чего в комментариях быть не должно:
-
Эмоций
RB0 = 1; // Без этой хрени не работает.
-
Описания устаревших действий
if (BufSize > 0) // Буфер не пуст, флаг разрешения // вывода установлен
-
Дублирования действия
BufSize = 0; // Обнуляем переменную, показывающую // размер буфера
-
Бесполезной информации
if (N < 15) // Лучший вариант сравнения
-
Непонятных сокращений и жаргона:
A = X / Y + Z; // В (*1*), т.н.у., обход
-
Ложной или вводящей в заблуждение информации:
if (timer < 100 && V < 10) // Если за 100мс напряжение // стало выше 10 вольт
Расположение комментариев
Не следует мешать код и текст комментариев в одну кучу. Например, так:
Неправильный подход:
/* Инициализация портов*/ PIN_DATA = 0; PIN_CLC = 0; /* Очистка буфера */ for (i = 0; i < BUF_SIZE; i++) Buf[i] = 0; /*Ожидание данных */ while (ReadData()) { ...
Комментарии нужно писать так, чтобы они не сливались с кодом. Один из вариантов – выносить их на поля, выравнивая по вертикали.
Правильный подход:
PIN_DATA = 0; /* Инициализация портов */ PIN_CLC = 0; for (i = 0; i < BUF_SIZE; i++) Buf[i] = 0; /* Очистка буфера */ while (ReadData()) /* Ожидание данных */ { ...
Многострочные комментарии
При написании многострочного комментария (например, описывающего функцию), нужно, чтобы каждая строка начиналась с символа, обозначающего, что это комментарий.
Неправильный подход:
/* Эта функция считывает начальные установки из EEPROM, проверяя контрольную сумму. Если контрольная сумма не сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
Правильные подходы:
(не очень удобный вариант: из-за наличия правого ограничителя такой комментарий утомительно редактировать)
/* Эта функция считывает начальные установки из EEPROM, */ /* проверяя контрольную сумму. Если контрольная сумма не */ /* сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
(альтернативные варианты)
/* * Эта функция считывает начальные установки из EEPROM, * проверяя контрольную сумму. Если контрольная сумма не * сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
// Эта функция считывает начальные установки из EEPROM, // проверяя контрольную сумму. Если контрольная сумма не // сошлась, то будут приняты установки по умолчанию. for (i = 0; i < BUF_SIZE; i++) ...;
Часто удобно пользоваться горизонтальными разделителями для визуального отделения логически разных блоков в тексте программы:
//--------------------------------------------------
или
/**************************************************/
Содержательная часть комментария
Вспомним, что мы говорили про именование идентификаторов и использование именованных констант. Рассмотрим пример:
switch (result) // Проверяем состояние модема { case 0: // Модем выключен … break; case 1: // Модем готов к работе … break; case 2: // Модем производит дозвон … break; … }
Если бы использовали осмысленные имена (и переменной и констант), то сам фрагмент программы оказался бы понятным и без комментариев.
switch (ModemState) { case MODEM_OFF: … break; case MODEM_READY: … break; case MODEM_CALLING: … break; … }
Тем самым у нас появляется возможность комментарием пояснить какой-нибудь нюанс какой-то ситуации или какого-то действия.
Формулировка
Совет: формулируя комментарий, всегда представляйте, как будто комментарий читает другой человек. Это поможет сделать формулировку более четкой.
![]()
Отладка и тестирование
Отладка, как и тестирование, – неотъемлемая часть разработки. Я отвел для этих понятий один общий раздел, т.к. обычно, эти этапы производятся параллельно. Надо сказать, что эти два этапа дополняют друг друга.
Рассмотрим следующие моменты:
![]()
Инструменты
В арсенале программиста может быть довольно мощный инструментарий: симулятор, внутрисхемный отладчик, лог. анализатор, осциллограф и т.д. В целом, неизвестно, сколько ошибок нужно будет обнаружить и исправить, поэтому процесс отладки и тестирования может сильно затянуться. И здесь наличие хорошего инструментария и умение с ним работать поможет сэкономить массу времени и сделает сам процесс более легким. Поэтому не нужно скупиться на средства отладки.
![]()
Резерв по ресурсам
Желательно еще на этапе планирования предусмотреть возможность взять для отладки контроллер с запасом по ресурсам. Для чего они могут понадобиться? В процессе тестирования или отладки программы нам может понадобится контроль хода выполнения или каких-то внутренних переменных. Для этого нам понадобится запас:
-
периферийных возможностей
-
памяти для размещения отладочного кода
-
резерв по скорости
Запас по периферии
Внутренняя периферия контроллера
Здесь масса вариантов. Как минимум – иметь свободные выводы контроллера для возможности устанавливать на них логические уровни, соответствующие состоянию программы. Если в устройстве не планируется использовать модуль USART, то было бы удобно оставить свободными выводы контроллера, на которые этот модуль работает. Тогда отладочную информацию можно будет сливать, используя аппаратные возможности контроллера. Если использование USART все же планируется, а отладочную информацию все равно хочется слать через RS-232 в компьютер, то можно пожертвовать системным временем и сделать функцию вывода программно на любом свободном выводе контроллера (функция ввода нужна не так часто, а функция вывода реализуется довольно просто). Зачастую есть возможность скидывать отладочные данные в общем потоке данных (по UART, по радиоканалу).
Также для отладки и тестирования может понадобиться аппаратный таймер для определения скорости выполнения некоторых участков или времени реакции на событие. Так что, если есть возможность на этапе планирования зарезервировать один аппаратный таймер для нужд отладки, то лучше сделать это.
Внешняя периферия
Например, если используется LDC, то можно предусмотреть какой-то сегмент для вывода отладочной информации. В EEPROM можно выделить отдельную страницу, куда сохранять состояние контроллера после сброса, если при запуске выясняется, что сброс был аварийным (например, туда можно записать содержимое стека, пускай сам указатель и не сохранился).
Также можно на плате предусмотреть дополнительные кнопки, дополнительные светодиоды.
Память для размещения отладочного кода
Здесь все понятно: отладочный код занимает место в ROM и часто требует каких-то ячеек RAM-памяти. И будет очень обидно, если из-за отладочных функций и макросов не будет умещаться основная программа.
Резерв скорости
Естественно, подпрограммы вывода отладочной информации не выполняются мгновенно. Может получиться так, что из-за ее вывода программа будет просто не успевать отрабатывать свой алгоритм. Это нужно учитывать как при выборе тактовой частоты контроллера, так и при написании отладочных подпрограмм.
![]()
Заглушки и тестеры
Функции-заглушки
В процессе тестирования могут пригодиться так называемые заглушки – пустотелые функции, соответствующие спецификации, но подменяющие вычисления (или результаты какой-то другой операции) заведомо правильным результатом. Когда это может оказаться полезным:
-
Когда при отладке нужны результаты работы еще ненаписанных подпрограмм.
-
При тестировании в симуляторе, когда нет возможности работать с какими-то внешними устройствами (например, GPS);
-
При тестировании кода, содержащего долго выполняющиеся функции, не участвующие в тесте подпрограммы (типичный пример – задержки)
Функции-тестеры
Когда мы пишем новую функцию, мы хотим убедиться в ее работоспособности. Есть смысл писать небольшие функции, которые будут проводить тестирование новой, многократно запуская ее, передавая ей тестовые параметры. Дальнейший результат можно, в зависимости от назначения функции, наблюдать визуально или сравнивать с шаблоном. Такие функции могут формировать для нашей программы последовательность входных параметров, которая может возникнуть в реальной обстановке. Это также может оказаться особенно полезным, когда программа отлаживается или тестируется в симуляторе. Важно, чтобы при тестировании функция запускалась именно на рабочем контроллере или его аналоге (а не на Builder C++, Visual C++ и пр., на которых можно отлаживать только макет функции), т.к. каждый компилятор имеет свои особенности (типы данных, автоматическое преобразование типов, работа со стеком и пр.); каждый процессор – свои: архитектура (Гарвадрская и Неймоновская), объем доступной памяти и т.д.
Самое сложное место в этой схеме – шаблон. Ведь мы писали новую функцию именно для того, чтобы она нам этот результат вычисляла. Где брать шаблон для сравнения? Есть три пути:
-
В некоторых случаях есть возможность результат для сравнения формировать сторонней функцией. Например, известно, что функция printf из-за своей универсальности довольно громоздкая, и далеко не в каждом случае программист может позволить себе ее использовать, отняв у контроллера чуть ли не половину памяти и несколько тысяч тактов. Поэтому частое явление, когда программист пишет свою mini-printf, удовлетворяющую требованиям спецификации конкретной программы. Для проверки работоспособности своей функции он на этапе тестирования может пользоваться результатами работы встроенной функции printf. Причем эта функция может тестироваться в автоматическом режиме. Такой же способ подойдет для проверки математических функций.
-
Входные параметры и результат вбивать вручную. Довольно трудоемкий процесс, поэтому в первую очередь желательно тестировать граничные значения.
-
Третий вариант – брать данные извне (например, в автоматическом режиме с PC)
![]()
Предупреждения при компиляции
Серьезная ошибка, которую допускают программисты – это игнорирование предупреждений компилятора. Более того, к ним относятся как к назойливым мухам: «Ну, наконец-то собрал программу. Только своими дурацкими предупреждениями забил всю статистику, что ничего не прочтешь!» А между тем, компилятор ругается не просто так. Тут он нам не враг, а помощник. Он сообщает, что в программе есть двояко толкуемые конструкции, которые он транслировал на свое усмотрение. Дело в том, что ошибку можно совершить, даже написав все правильно с точки зрения языка. Например, в программе могут встретиться выражения вида:
if (a == b) ...; if (a = b) ...; // Warning: Assignment inside relational expression
В зависимости от того, что мы хотим сделать, мы можем применить первое или второе выражение в скобках оператора if. В первом выражении мы проверяем переменные a и b на равенство, в то время как во втором мы проверяем переменную a на 0 после присваивания ей значения из переменной b. В общем случае второй записью пользоваться не рекомендуется, т.к. гораздо нагляднее:
a = b; if (a) ...;
Потому-то компилятор и выдает нам предупреждение, что в выражении отношения имеется оператор присваивания, давая тем самым понять, что, возможно, мы имели в виду оператор отношения “==”. (Иногда, все же, есть смысл использовать вторую запись, когда, например, код критичен ко времени выполнения.)
Также частым следствием предупреждения компилятора является неаккуратное отношение к приведению типов. Например, в том же операторе сравнения:
signed int a; unsigned int b; … if (a > b) …; // Warning: signed and unsigned comparison
мы получим предупреждение, если одна переменная знаковая, а вторая – нет. Это предупреждение говорит не о том, что «осторожно! Может случиться коллизия», а о том, что программистом неправильно выбраны типы. Если же программист уверен в правильности, то он должен сделать приведение типов вручную:
signed int a; unsigned int b; ... if ((signed long) a > (signed long) b) ...;
Тем самым давая компилятору понять, что программист в курсе неправильно выбранных типов. Обратим внимание на то, что приведение типов производится к знаковому типу большей разрядности.
(Вообще же, повторюсь, с выражениями, где участвуют переменные различных типов, нужно быть осторожнее. Например, MPLAB C18 не выдаст предупреждения на наш пример, что в свою очередь приведет к неправильному поведению программы, если a будет иметь отрицательное значение.)
Что делать, если компилятор выдал предупреждение?
В первую очередь нужно определиться, почему он выдал предупреждение. Если его текст не понятен, то нужно обратиться к документации на компилятор и прочитать больше информации (часто в описании предупреждений приводятся наиболее частые причины их возникновения). Во вторую – привести код к однозначно интерпретируемому виду.
![]()
Вывод отладочной информации
При формировании отладочной информации нужно помнить, что информация об ошибках, выводимая для пользователя, и информация о поведении программы, выводимая для программиста, — это абсолютно разные вещи. Причем как по содержанию, так и по способу информирования.
Не нужно пользователя снабжать шестнадцатеричными кодами на дисплее, а по телефону потом разъяснять, что это «переменная режима работы приняла странное значение, сейчас подумаю, почему такое произошло». Также не нужно в конечном варианте программы оставлять всяческие вспыхивания светодиодов и взвизгивания пьезодинамика, которые при отладке говорили программисту о каком-то поведении программы или о ходе вычислений (а потом по телефону объяснять, что если лампочка мигнула 3 раза по 50 мс, то это не сошлась контрольная сумма). Т.е. вся отладочная информация, которая будет выводиться для программиста, должна быть скрыта от пользователя (запись в EEPROM, передача кода ошибки на центральный пульт, если такой есть).
![]()
Блокировка вывода отладочной информации
Нужно помнить, что возможность вывода отладочной информации, скорее всего, придется оставить в контроллере на всю жизнь. Иногда и отлаженные и переотлаженные программы могут содержать ошибки. Тем не менее, нужно иметь возможность отключать:
-
вывод отладочной информации (как всей скопом, так и отдельных узлов);
-
заглушки
-
тестеры (их полезно оставлять в тексте программы на случай проявлений ошибок в период эксплуатации)
Блокировать можно двумя способами:
-
на этапе компиляции, блокируя все отладочные узлы условными директивами компиляции:
#define DEBUG_ENABLE ... /*D*/ #ifdef DEBUG_ENABLE /*D*/ PIN_DEBUG = 1; /*D*/ #endif
(тогда, закомментировав определение DEBUG_ENABLE, мы удаляем из кода всю отладочную составляющую). Такой способ экономит ресурсы контроллера.
-
на программно-аппаратном уровне (например, контролируя состояние порта):
if (PIN_DEBUG_ENABLE) PIN_DEBUG = 1;
(тогда мы можем включать/отключать работу отладочных подпрограмм в ходе выполнения.) Такой способ требует ресурсы, но позволяет отлаживать устройство в реальных условиях.
То же самое касается блокировки функций-заглушек и функций-проверок. Например:
#define DUMMY_GPS_IN ... char * GetGPSData (void) { #ifdef DUMMY_GPS_IN char test_string[] = “$GPRMC,A,123456,…”; return test_string; #else /* Здесь код для работы с реальными данными от GPS */ #endif }
В последнем примере иногда можно обойтись и без #else, т.к. внутри этого блока окажется довольно большой код, что неудобно.
Разумеется, такие блоки в коде следует визуально выделять.
![]()
Резервное копирование
По ходу сопровождения (а иногда и разработки) программы нужно сохранять резервные копии, отмечая даты, номера версий, сделанные изменения и версию компилятора. Причем версию следует сохранять целиком, вместе с проектными файлами и HEX’ом. Бывает так, что незначительное изменение приводит к потере работоспособности кода, и, не имея резервных копий, зачастую трудно установить, какая именно из последних модификаций привела к таким последствиям.
Однако, сохранять целиком всю версию при каждой небольшой модификации довольно накладно (и по времени, и по трудоемкости). Поэтому для решения подобных задач удобно пользоваться специальными инструментами: системами контроля версий (VCS — version control systems).
Системы контроля версий обеспечивают два основных процесса:
-
взаимодействие группы разработчиков, работающих над одним проектом
-
сохранение текущих «срезов» проекта в базе данных.
Существуют различные реализации VCS: коммерческие и бесплатные, использующие центральный сервер и с распределенным хранением. Одна из самых распространенных — бесплатная система управления версий Subversion с открытым исходным кодом. Именно ее можно порекомендовать для начального ознакомления с VCS.
Subversion (или SVN) является клиент-серверной системой. База данных проекта или репозиторий хранится на сервере, а разработчик работает с локальной копией проекта, которую «отдает» ему приложение-клиент. Поработав с локальной копией, разработчик сохраняет на сервере изменения проекта — таким образом обеспечивается безопасная работа в группе и полный контроль над ходом работы. В любой момент можно извлечь один из «срезов» (в терминологии SVN — ревизий) проекта и посмотреть всю историю изменений, а также произвести сравнение различных версий.
Наиболее популярная программа клиент Subversion для Windows — TortoiseSVN.
![]()
Список литературы
-
Э. Йодан «Структурное проектирование и конструирование программ», М. Мир, 1979
-
Б. Керниган, Р. Пайк «Практика программирования»
-
А. Голуб «Веревка достаточной длины, чтобы… выстрелить себе в ногу»
-
С. Макконнелл «Совершенный код», Русская редакция, 2005
-
Ван Тассел Д. «Стиль, разработка, эффективность, отладка и испытание программ», М. «Мир», 1981
![]()
Виктор Тимофеев, ноябрь 2009
osa@pic24.ru
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3