Пересказ статьи Rajendra Gupta. How to manage SQL Server logs effectively
В статье дается обзор журналов SQL Server для управления и устранения неполадок на сервере.
Введение
Журналы являются лучшим средством администратора баз данных при решении любых проблем. Эти проблемы могут быть связаны с конфигурацией сервера, запуском, восстановлением, производительностью, флагами трассировки, тупиковыми ситуациями, вводом-выводом или задержками. Предположим, например, что ваш экземпляр SQL Server перезапускается по непонятным причинам, и после перезапуска службы SQL работают, однако ваше приложение не имеет доступа к базе данных. Таким образом, для исследования проблемы вам нужно заглянуть в последний журнал SQL Server, чтобы проконтролировать процесс восстановления базы данных и узнать оценку времени его завершения.
Администратор базы данных может также сконфигурировать SQL Server для выполнения дополнительных записей в журналы ошибок. Например, мы можем включить флаг трассировки для захвата информации о тупиковых ситуациях. DBA должен регулярно просматривать эти журналы в поисках потенциальных проблем. Вы можете обнаружить в журналах такую информацию, как сбой резервного копирования, ошибки входа, ошибки ввода-вывода. Эти журналы ошибок являются отличным средством для обнаружения существующих и потенциальных проблем в экземплярах SQL Server.
Журналы SQL Server известны как SQL Server Error logs. Журналы ошибок содержат информационные сообщения, предупреждения и сообщения о критичных ошибках. Вы можете просматривать некоторые из этих журналов также в просмотрщике событий Windows. Однако рекомендуется использовать журналы SQL Server для получения подробной информации.
Журналы SQL Server и их местонахождение
Если вы подключены к экземпляру SQL Server в SSMS, перейдите к Management -> SQL Server Logs. Как показано ниже, имеется текущий журнал и шесть архивных журналов (Archive#1 — Archive #6).
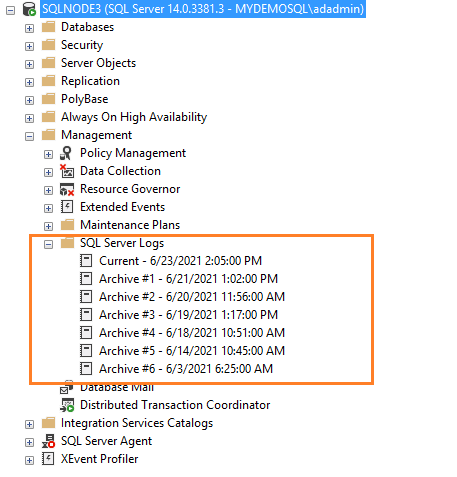
Метод 1: Использование расширенной процедуры xp_readerrorlog
Текущие журналы являются самыми последними файлами журнала ошибок, и вы можете использовать их для просмотра недавней деятельности с момента запуска SQL Server или ручного перезапуска файла журнала. Журнал ошибок SQL Server является текстовым файлом, хранящимся в каталоге журналов экземпляра SQL Server. Вы можете использовать расширенную процедуру xp_readerrorlog для нахождения текущего местоположения журнала ошибок.
USE master
GO
xp_readerrorlog 0, 1, N'Logging SQL Server messages', NULL, NULL,NULL
GO
Этот запрос имеет следующие параметры:
- Файл журнала ошибок: значение 0 для текущего, 1 для Archive#1, 2 для Archive #2.
- Тип файла журнала: значение 0 для журнала ошибок SQL Server, 1 для агента SQL Server.
- Строка поиска 1
- Строка поиска 2
- Время от
- Время до
- Сортировка результатов — по возрастанию (N’ASC) или по убыванию (N’Desc)
Для моего демонстрационного экземпляра файл журнала ошибок находится в папке C:Program FilesMicrosoft SQL ServerMSSQL14.MSSQLSERVERMSSQLLogERRORLOG.

Метод 2: Использование функции SERVERPROPERTY()
Мы можем использовать в запросе функцию SERVERPROPERTY, и также определить местонахождение SQL Server ERRORLOG.
SELECT SERVERPROPERTY('ErrorLogFileName') AS 'Error log location'

Метод 3: использование менеджера конфигурации SQL Server
Откройте SQL Server Configuration Manager и посмотрите параметры запуска. Местоположение файлов журнала указывается с помощью переключателя -e.
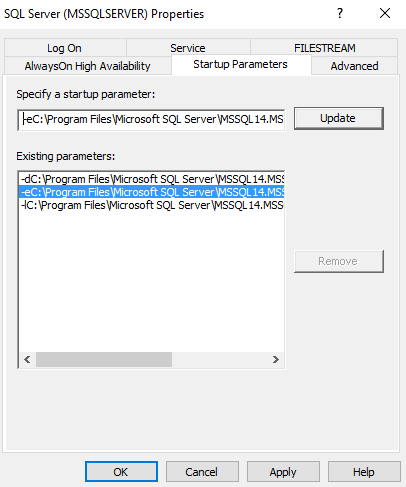
Вы можете развернуть каталог журналов и просмотреть текущий или архивные файлы журнала. Эти журналы ошибок можно открыть в текстовом редакторе, таком как Notepad или Visual Studio Code.
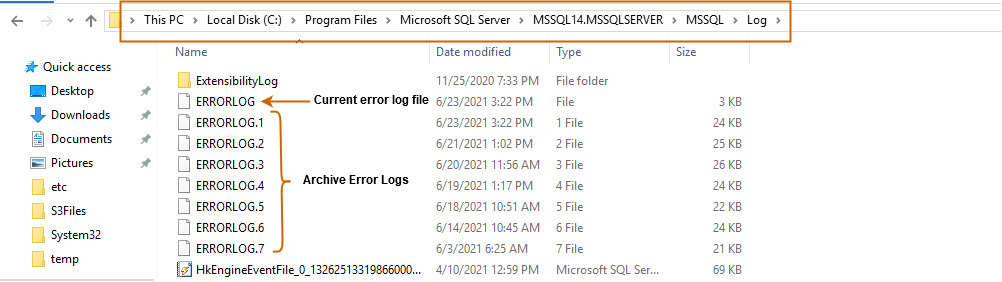
Конфигурирование числа файлов журнала SQL Server и их размеров
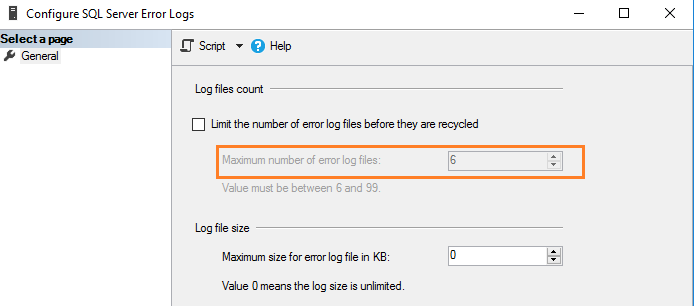
По умолчанию SQL Server поддерживает текущий и 6 архивных файлов журнала. Чтобы уточнить значение, выполните щелчок правой кнопкой на папке SQL Server Logs в SSMS и выберите Configure.
SQL Server записывает всю информацию в текущий файл журнала, независимо от размера файла журнала. В загруженной системе или в экземпляре с большим количеством ошибок вам может быть сложно просмотреть файл журнала в SSMS. SQL Server создает новый файл журнала и архивирует текущий файл в следующих случях.
- При перезапуске службы SQL.
- При перезагрузке журнала ошибок вручную.
Однако если вы часто перезапускаете серверы по неизвестным причинам, то можете потерять все исторические данные в архивных журналах, поскольку их поддерживается только шесть. Поскольку ошибки содержат ценную информацию, которая может помочь в решении проблем, вы можете не захотеть потерять эти важные данные. Тогда, возможно, вы захотите сохранять файлы журнала производственной системы в течение недели или даже месяца.
SQL Server позволяет сконфигурировать от 6 до 99 файлов журнала ошибок. Вы не можете указать значение меньше шести, поскольку в любом случае будет поддерживаться шесть архивных журналов ошибок.
Для изменения значения по умолчанию числа файлов журнала ошибок поставьте галочку в поле с названием “Limit the number of error log files before they are recycled”. Например, следующий скриншот показывает максимальное число файлов журнала ошибок, равное 30.
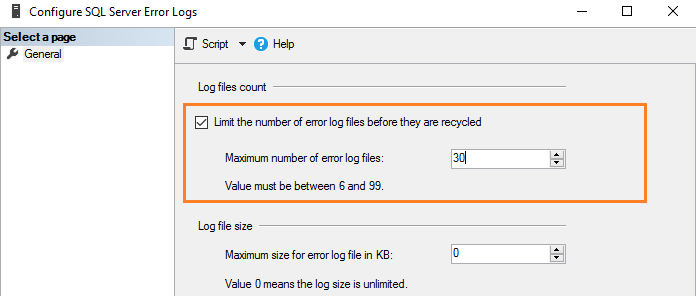
Это эквивалентно выполнению скрипта T-SQL, который использует расширенную хранимую процедуру и обновляет значение регистра.
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'SoftwareMicrosoftMSSQLServerMSSQLServer', N'NumErrorLogs', REG_DWORD, 30
GO
Замечание. Следует перезапустить службу SQL, чтобы изменения вступили в силу.
Как утверждалось ранее, по умолчанию размер журнала ошибок не ограничен. Например, если вы не запускаете SQL Server в течение длительного периода и вручную не перегружаете файлы журнала, этот файл вырастет до громадных размеров. Поэтому в конфигурации журнала ошибок показано значение 0, соответствующее неограниченному размеру журнала.
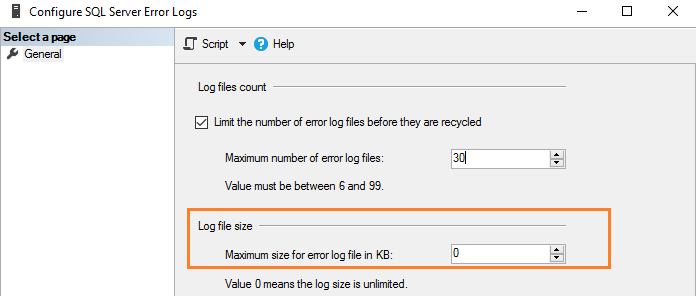
Вы можете задать размер в Кб для ограничения размера журнала ошибок в соответствии с вашими требованиями. Например, здесь мы ограничиваем размер файла журнала в 1Гб.
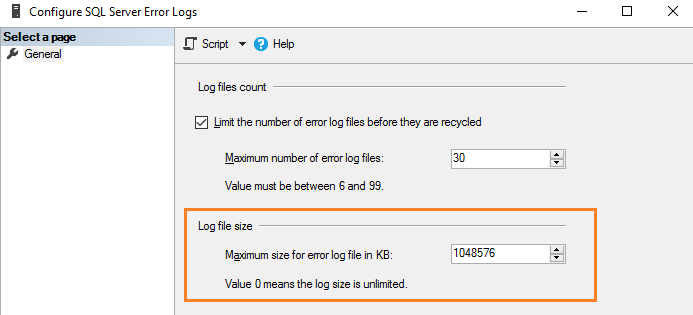
Эквивалентный скрипт T-SQL обновляет ErrorLogSizeInKb в регистре SQL Server.
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'SoftwareMicrosoftMSSQLServerMSSQLServer', N'ErrorLogSizeInKb', REG_DWORD, 1048576
GO
Перезагрузка журналов ошибок вручную
SQL Server позволяет вручную перегружать журналы ошибок для эффективного управления ими. Например, предположим, что вы увеличили число файлов журнала ошибок до 30. Тогда мы можем создать задание для агента SQL Server, который перегружает журналы ошибок в полночь. Тем самым мы имеем файл журнала ошибок на каждый день, если SQL Server не будет перезапущен в этом промежутке. Для перезагрузки вручную выполните системную хранимую процедуру sp_cycle_errorlog. Эту процедуру может выполнить пользователь с фиксированной серверной ролью sysadmin.
EXEC sp_cycle_errorlog
GO
Файл журнала SQL Server Agent
Агент SQL Server также имеет отдельный журнал ошибок, подобный журналам SQL Server. Вы можете обнаружить его в папке SQL Server Agent – > Error logs.
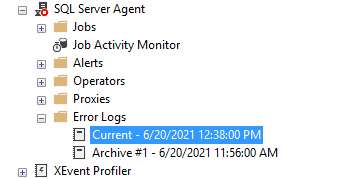
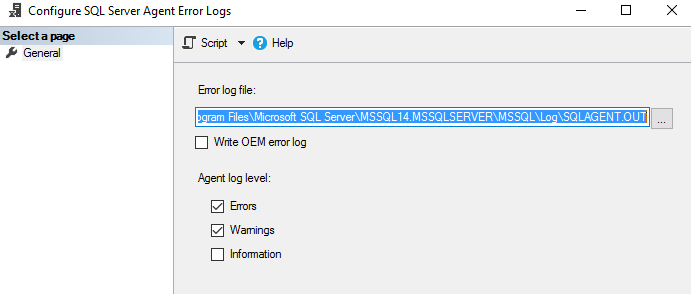
Щелкните правой кнопкой на папке Error log и выберите команду Configure. Это даст местоположение журнала ошибок агента и уровень журнала агента.
Файл журнала агента имеет расширение *.OUT и хранится в папке log при конфигурации по умолчанию. Например, в моей системе файл журнала находится здесь: C:Program FilesMicrosoft SQL ServerMSSQL14.MSSQLSERVERMSSQLLogSQLAGENT.OUT.
По умолчанию в файл журнала записываются ошибки и предупреждения; однако мы можем включить информационные сообщения:
- Предупреждения: Эти сообщения предоставляют информацию о потенциальных проблемах. Например, “Job X was deleted while it was running” (задание Х было удалено во время выполнения).
- Сообщение об ошибках: оно дает информацию, которая требует немедленного вмешательства администратора баз данных, например, невозможность почтового сеанса.

Чтобы добавить информационное сообщение, поставьте галочку в поле Information.
SQL Server использует до 9 файлов журнала агента SQL Server. Имя текущего файла SQLAGENT.OUT. Файл с расширением .1 указывает на первый архивный журнал ошибок агента. Аналогично расширение .9 указывает на 9-й (самый старый) архив журнала ошибок.
Файлы журнала агента SQL Server перегружаются всякий раз, когда перезапускается SQL Server Agent. Для того, чтобы сделать это вручную, выполните щелчок правой кнопкой на папке Error Logs folder и выберите Recycle.
Или используйте хранимую процедуру sp_cycle_agent_errorlog для перезагрузки файлов журнала агента SQL Server вручную.
USE msdb ;
GO
EXEC dbo.sp_cycle_agent_errorlog ;
GO
Хранимая процедура архивирует текущий журнал ошибок агента, используя следующий процесс:
- Создается новый текущий журнал ошибок агента.
- Текущий журнал ошибок SQLAgent.out преобразуется в SQLAgent.1.
- SQLAgent.1 преобразуется в SQLAgent.2
Заключение
Файл журнала ошибок SQL Server содержит информацию, предупреждения и критические сообщения экземпляра. Это полезно для решения проблем, аудита входа (успешно, отказ). Администратор базы данных может сконфигурировать требуемое число архивных журналов ошибок и каталогов для хранения этих файлов.
Вы должны регулярно просматривать записи в журнале в качестве подготовки ежедневных или еженедельных отчетов о состоянии сервера.
В процессе функционирования SQL Server ведет журнал, в котором регистрирует события, связанные с работой сервера. В документации этот журнал называется Error Log, что не вполне соответствует действительности. Правильнее было бы именовать его Event Log, так как в нем отмечается множество событий различного характера из разных источников, включая системные информационные и системные аварийные события, сообщения аудита регистрации и пользовательские сообщения (если сравнивать с операционной системой, то в Windows NT/2000 события регистрируются в трех журналах — Application, Security и System).
В документации по SQL Server отсутствует систематизированное изложение вопросов, связанных с Error Log, — сведения разбросаны по разным разделам, а часть информации, относящаяся к применению Transact SQL при работе с журналом, и вовсе отсутствует. Данная статья призвана в какой-то мере восполнить этот пробел в документации и помочь администраторам баз данных и разработчикам приложений научиться полностью использовать возможности журнала Error Log.
Что такое Error Log
При каждом запуске SQL Server начинает новый журнал Error Log, который представляет собой текстовый файл, расположенный по умолчанию в каталоге MSSQLLog. Файлы журналов, созданные при предыдущих запусках, не удаляются, а просто переименовываются. Текущий файл журнала имеет имя Error Log, файл предыдущего запуска Error Log.1 и т. д. По умолчанию SQL Server хранит файлы шести предыдущих журналов. Проще всего просмотреть журналы в Enterprise Manager (см. Рисунок 1). Изменить местоположение файлов журнала можно, используя параметр -e при старте сервера. В Enterprise Manager это делается через контекстное меню SQL Server properties: закладка General — Startup Parameters (см. Рисунок 2).

|
Рисунок 2. Установка параметров запуска SQL Server. |
Число сохраняемых журналов устанавливается в Enterprise Manager c помощью контекстного меню SQL Server Logs Configure (см. Рисунок 3). Можно сохранять не более 99 журналов предыдущих запусков.
|
|
Рисунок 3. Установка параметров Error Log. |
При запуске SQL Server в журнал заносится следующая информация:
- дата и время запуска;
- используемые версии SQL Server и Windows NT/2000 с учетом Service Pack;
- системный приоритет SQL Server и число процессоров в системе;
- информация о подключении системных и пользовательских баз данных;
- используемые сетевые библиотеки;
- сведения о готовности SQL Server к работе с клиентскими соединениями.
Если при запуске SQL Server возникли проблемы, можно с помощью любого текстового редактора прочитать файл Error Log и, возможно, обнаружить причину неудачи. При завершении работы сервер записывает в журнал причину этого события — либо была остановлена служба MSSQLSERVER (Server shut down by request), либо прекращена работа операционной системы (SQL Server terminating because of system shutdown). Если таких сообщений нет (естественно, не в текущем журнале), это означает, что работа компьютера не была завершена должным образом, например по причине аппаратного сбоя. Есть еще одно сообщение, которое может быть последним в Error Log, — в случае если был принудительно открыт новый файл журнала (Attempting to cycle errorlog). Об этом мы поговорим позже.
Необходимо отметить, что по умолчанию все сообщения Error Log дублируются в журнале Windows Application Log. Двойную регистрацию событий можно отменить, запустив SQL Server с параметром -n. При этом нужно обязательно указать параметр -e, иначе события не будут записываться и в журнал Error Log.
Какие события отражаются в Error Log
Есть события, которые в обязательном порядке отражаются в журнале.
К ним относятся:
- копирование/восстановление базы данных;
- нехватка дискового пространства в базе данных;
- выполнение команды KILL.
Можно организовать аудит удачных и неудачных попыток регистрации пользователей. В Enterprise Manager это делается с помощью контекстного меню SQL Server Properties: закладка Security — Audit Level (см. Рисунок 4).
|
|
Рисунок 4. Установка аудита регистрации пользователей. |
Как записывать собственные сообщения в Error Log
Собственные сообщения можно записать в журнал с помощью оператора RAISERROR или хранимой процедуры xp_logevent.
В RAISERROR для записи в журнал используется параметр WITH LOG :
RAISERROR ('Ошибка при добавлении
данных!',10,1) WITH LOG
Хранимая процедура xp_logevent специально предназначена для записи сообщений в Error Log:
exec master..xp_logevent 60000, ?посылка почты?,ERROR
Первый параметр — код сообщения, он должен быть больше 50 000. Последний параметр может принимать значения INFORMATIONAL, WARNING или ERROR. Необходимо обратить внимание на то, что xp_logevent, в отличие от RAISERROR, не посылает сообщение клиентской программе и не изменяет значения глобальной переменой @@ERROR. Для xp_logevent также нужна настройка прав на выполнение.
Хранимые процедуры для работы Error Log
Хранимая процедура sp_enumerrorlogs служит для получения полного списка журналов с указанием даты окончания записи в них и их объема. Хранимая процедура sp_readerrorlog читает журнал с указанным номером. Если номер не указан или номер 0, читается текущий журнал. Результаты выполнения названных процедур приведены на Рисунке 5.
Обе процедуры возвращают в качестве результата таблицы, структуры которых приведены ниже при описании примера работы с Error Log. Хранимая процедура sp_cycle_errorlog служит для принудительного открытия нового файла журнала. Необходимость открыть новый файл журнала может быть вызвана, например, большим объемом текущего журнала в результате длительной непрерывной работы сервера (журнал большого объема трудно просматривать и анализировать).
Пример практического использования знаний об Error Log
Администратор базы данных должен знать, как часто происходит запуск и остановка SQL Server. Особенно эта информация полезна, если сервер физически расположен не в организации, а у провайдера услуг. При этом желательно знать общее время работы сервера и причины остановки. Сценарий, приведенный в Листинге 1, решает эту задачу, используя информацию из Error Log.
Итог исполнения сценария на тестовом сервере приведен на Рисунке 6. Здесь показано, что первый, второй, пятый и шестой журналы были закрыты по причине остановки Windows, третий журнал — в результате остановки службы SQL Server, а четвертый — принудительно хранимой процедурой sp_cycle_errorlog.
В текущем журнале последним событием является попытка неудачной регистрации пользователя.
Ильдар Даутов — MCT, MCDBA, начальник отдела АКБ «Заречье», dia@zarech.ru.
 Автор: Alexey Knyazev
Автор: Alexey Knyazev
Сегодня я расскажу про недокументированные расширенные хранимые процедуры (Extended Stored Procedures) для работы с журналом ошибок SQL Server и SQL Server Agent.
На самом деле при просмотре журнала SQL Server Logs через SSMS (SQL Server Management Studio) идёт обращение именно к этим двум основным процедурам (xp_readerrorlog и xp_enumerrorlogs), хоть и не на прямую, а через системные интерфейсные процедуры.
Особое внимание я уделю описанию входных параметрам этих недокументированных процедур.
И так, что же происходит, когда мы просматриваем журнал ошибок через SSMS?

Во первых мы определяем путь к нашей папке с журналами
|
select ServerProperty(‘ErrorLogFileName’) |

Затем выводим информацию о текущем журнале и о шести предыдущих
|
exec master.dbo.sp_enumerrorlogs |

в качестве входного параметра можно указать
- 1 — Список журналов SQL Server (значение по умолчанию)
- 2 — Список журналов SQL Server Agent
Если обратиться к тексту этой процедуры, то можно увидеть, что это не более, чем «обёртка» для вызова другой процедуры
|
create proc sys.sp_enumerrorlogs( @p1 int = 1) as begin IF (not is_srvrolemember(N‘securityadmin’) = 1) begin raiserror(15003,—1,—1, N‘securityadmin’) return (1) end exec sys.xp_enumerrorlogs @p1 end |
По коду процедуры видно, прежде чем обратиться к расширенной хранимой процедуре xp_enumerrorlogs, идёт проверка, что пользователь входит в серверную роль securityadmin.
Теперь если мы нажмём View SQL Server Log

то мы сможем просмотреть все события выбранного журнала:

В этот момент идёт обращение к ещё одной процедуре-обёртке master..sp_readerrorlog.
Ниже текст этой процедуры:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
create proc sys.sp_readerrorlog( @p1 int = 0, @p2 int = NULL, @p3 nvarchar(4000) = NULL, @p4 nvarchar(4000) = NULL) as begin if (not is_srvrolemember(N‘securityadmin’) = 1) begin raiserror(15003,—1,—1, N‘securityadmin’) return (1) end if (@p2 is NULL) exec sys.xp_readerrorlog @p1 else exec sys.xp_readerrorlog @p1,@p2,@p3,@p4 end |
Как вы видите у неё четыре входных параметра:
- @p1 — номер журнала (0-6); 0 — текущий
- @p2 — чей журнал; 1 — SQL Server, 2 — SQL Server Agent
- @p3 — фильтр для поиска
- @p4 — второе условие для поиска
Пример:
|
exec master.dbo.sp_readerrorlog 0, 1, N‘error’ |

|
exec master.dbo.sp_readerrorlog 0, 1, N‘error’, N‘34050’ |

Но это ещё не всё. Если обратиться к самой расширенной процедуре xp_readerrorlog, то у неё есть ещё несколько параметров:
- @p5 — условие с какой даты выводить результат
- @p6 — условие до какой даты выводить результат из журнала
- @p7 — тип сортировки (asc/desc)
- @p8 — экземпляр SQL Server (@InstanceName), параметр появился в SQL Server 2012
Пример:
|
exec master.dbo.xp_readerrorlog 0, 1, null, null, ‘20130418’, ‘20130419’ |

|
exec master.dbo.xp_readerrorlog 0, 1, null, null, ‘20130418’, ‘20130419’, N‘desc’ |

Если необходимо работать с журналом пользователю с минимальными привилегиями, то достаточно дать явные права на эти расширенные процедуры, но обращаться к ним придётся через запросы, т.к. SSMS использует интерфейсные процедуры, которые проверяют входимость пользователя в группу securityadmin.
|
use master go grant execute on xp_readerrorlog to [Ваш юзер] go |
Запись опубликована в рубрике В помощь администратору с метками error log. Добавьте в закладки постоянную ссылку.
Written on 09 Февраля 2009. Posted in MS SQL Server
Одними из самых непонятных составных частей SQL Server являются механизмы ведения журнала и восстановления. Складывается впечатление, что сам факт существования журнала транзакций и то, что неправильное управление этим журналом может приводить к неполадкам, ставит в тупик многих «невольных администраторов баз данных» (DBA). Почему журнал транзакций может неограниченно увеличиваться в размере? Почему в некоторых ситуациях требуется слишком много времени для того, чтобы база данных стала доступной после сбоя системы? Почему невозможно полностью отключить ведение журнала? Почему не удается надлежащим образом восстановить базу данных? Что из себя представляет журнал транзакций, и зачем он существует?
Все эти вопросы я постоянно вижу на форумах SQL Server, поэтому в данной статье я собираюсь предоставить обзор системы ведения журнала и восстановления и объяснить, для чего существует эта неотъемлемая часть модуля хранилищ SQL Server. Будет рассмотрена архитектура журнала транзакции и то, каким образом три модели восстановления, доступные для базы данных, могут изменить поведение журнала транзакций и сам процесс ведения журнала. Заодно я предоставляю некоторые ссылки на ресурсы, описывающие оптимальные методики упрвления журналом транзакций.
Что из себя представляет ведение журнала?
Ведение журнала и процедура восстановления присущи не только SQL Server — во все коммерческие системы управления реляционными базами данных (RDBMS) должны входить эти средства для обеспечения поддержки различных свойств ACID транзакций. Сокращение ACID обозначает Atomicity (атомарность), Consistency (согласованность), Isolation (изоляция) и Durability (устойчивость), являющиеся фундаментальными свойствами систем обработки транзакций (таких как RDBMS).
Операции, выполняемые в RDBMS, регистрируются (или записываются) на физическом и логическом уровне в терминах событий, происходящих в структурах хранилища базы данных. Для каждого изменения в структурах хранилища имеется отдельная запись журнала, описывающая изменяемую структуру и собственно изменение. Это выполняется способом, позволяющим повторить изменение или, при необходимости, отменить изменение и вернуть все в исходное состояние. Записи журнала хранятся в специальном файле, который называется журналом транзакций — далее это будет описано подробнее, а пока его можно представлять в виде файла с последовательным доступом.
Набор из одного или нескольких изменений можно сгруппировать (и, фактически, так всегда и делается) в транзакцию, обеспечивающую базовую единицу процесса внесения изменений (атомарность) в базу данных, когда речь идет о пользователях, разработчиках приложений и DBA. Транзакция завершается успешно (фиксация) или завершается аварийно или отменяется (откат). В первом случае гарантируется, что операции, формирующие транзакцию, отражены в базе данных. Во втором случае гарантируется, что операции не будут отражены в базе данных.
Транзакции в SQL Server бывают явными и неявными. При явной транзакции пользователь или приложение выдает оператор BEGIN TRANSACTION T-SQL, оповещающий о запуске данным сеансом группы связанных изменений. Явная транзакция успешно завершается, когда выдается оператор COMMIT TRANSACTION, оповещающий об успешном выполнении группы изменений. Если вместо него выдается оператор ROLLBACK TRANSACTION, все изменения, выполненные в данном сеансе с момента выдачи оператора BEGIN TRANSACTION, обращаются (откатываются), и транзакция отменяется. Откат транзакции может быть принудительно вызван внешним событием, например, нехваткой для базы данных свободного места на диске или выходом из строя сервера. Эти случаи будут рассмотрены далее.
При неявной транзакции пользователь или приложение не выдает явно оператора BEGIN TRANSACTION до выдачи оператора T-SQL. Однако, поскольку все изменения в базе данных должны быть оформлены в транзакцию, модуль хранилищ скрытым образом автоматически запускает транзакцию. По завершении выполнения оператора T-SQL модуль хранилищ автоматически фиксирует транзакцию, запущенную для создания оболочки для пользовательского оператора.
Вам может показаться, что в этом нет необходимости, поскольку один оператор T-SQL не может генерировать большое число изменений в структурах хранилища базы данных, но рассмотрите, например, оператор ALTER INDEX REBUILD. Хотя этот оператор не может содержаться в явной транзакции, он может генерировать огромное число изменений в базе данных. Поэтому необходим механизм, обеспечивающий в случае неправильного развития событий (например, если отменяется выполнение оператора) надлежащее выполнение обращения изменений.
В качестве примера рассмотрим, что происходит, если в неявной транзакции обновляется одна строка таблицы. Представим себе простую неупорядоченную таблицу, содержащую столбец c1 с целочисленными данными и столбец c2 с символьными данными. В таблице имеется 10 000 строк, и пользователь отправляет запрос на обновление следующим образом:
UPDATE SimpleTable SET c1 = 10 WHERE c2 LIKE '%Paul%';
Выполняются следующие операции:
- Страницы данных из SimpleTable считываются с диска в память (буферный пул), поэтому можно выполнять поиск соответствующих строк. Оказывается, что на трех страницах данных имеется пять строк, соответствующих предикату предложения WHERE.
- Модуль хранилищ автоматически запускает неявную транзакцию.
- Эти три страницы и пять строк данных блокируются для выполнения обновлений.
- Изменения вносятся в пять записей данных на трех страницах данных, находящихся в памяти.
- Изменения записываются также в записи журнала транзакций на диске.
- Модуль хранилищ автоматически фиксирует эту неявную транзакцию.
Обратите внимание, что я не отметил шага, на котором три обновленных страницы данных записываются обратно на диск. Это связано с тем, что в такой операции нет необходимости; до тех пор, пока записи журнала, описывающие изменения, присутствуют в журнале транзакций на диске, данные изменения защищены. Если после внесения изменений эти страницы потребуется прочитать или вновь изменить, самая последнияя актуальная копия страницы уже находится в памяти, а не на диске (пока). Страницы данных будут записаны на диск при следующей операции контрольной точки или если память, занимаемая ими в буферном пуле, потребуется для изображения другой страницы.
Контрольные точки существуют по двум причинам — для группирования операций ввода/вывода с целью повышения производительности и для сокращения вермени, требуемого для восстановления после сбоя. В терминах производительности, если бы страница данных вытеснялясь на диск при каждом ее обновлении, число операций ввода/вывода в активно используемой системе могло бы превысить возможности подсистемы ввода/вывода. Разумнее с некоторой периодичностью записывать на диск «грязные» страницы (те, которые были изменены с момента их считывания с диска), чем записывать на диск страницы незамедлительно после внесения в них изменений. Чуть ниже я рассмотрю контрольные точки с точки зрения восстановления.
Одно из распространенных заблуждений относительно контрольных точек состоит в том, что они выполняют запись измененных страниц из зафиксированных транзакций. Это не так — контрольная точка всегда записывает на диск все «грязные» страницы, независимо от того, зафиксирована или нет транзакция, изменившая страницу.
Ведение журнала с упреждающей записью является механизмом, в котором записи журнала, описывающие изменения, записываются на диск до записи на диск самих изменений. Это обеспечивает часть свойств ACID, отвечающую за устойчивость. До тех пор, пока записи журнала, описывающие изменения, находятся на диске, записи журнала (а, следовательно, сами изменения) в случае сбоя могут быть восстановлены, и результаты транзакции не будут утрачены.
В чем заключается восстановление?
Ведение журнала предусмотрено для поддержки множества операций в SQL Server. Это обеспечивает, в случае возникновения сбоя, правильность отражения зафиксированной транзакции в базе данных после сбоя. Этим гарантируется, что откат незафиксированной транзакции будет выполнен надлежащим образом, и она не будет отражена в базе данных после сбоя. Этим же обеспечивается возможность отмены незавершенной транзакции и отката всех ее операций. Ведение журнала позволяет проводить резервное копирование журнала транзакций таким образом, чтобы было возможно восстановление базы данных и воспроизведение резервных копий журнала транзакций с целью возврата базы данных в состояние, соответствующее конкретному моменту времени и с соблюдением транзакционной согласованности. Кроме этого, обеспечивается поддержка функций, основанных на чтении журнала транзакций, таких как репликация, зеркальное отображение базы данных и сбор данных изменений.
Большинство таких применений журнала влечет использование механизма, называемого восстановлением. Восстановление представляет собой процесс воспроизведения в базе данных изменений, описанных в записях журнала, или возврат базы данных к состоянию до этих изменений. Воспроизведение записей журнала называется фазой REDO (или наката) восстановления. Обращение изменений записей журнала называется фазой UNDO (или отката) восстановления. Другими словами, процедура восстановления обеспечиваете для транзакции и всех соответствующих записей журнала либо полное воспроизведение, либо полную отмену.
Восстановление принимает простую форму в случае отмены отдельной транзакции, когда она откатывается, и база данных не испытывает никаких последствий. Более сложную форму имеет восстановление в случае сбоя, когда выходит из строя SQL Server (по какой бы то ни было причине), и журнал транзакций необходимо восстановить с целью возврата базы данных в состояние, согласованное с точки зрения транзакций. Это означает, что для всех транзакций, зафиксированных на момент сбоя, необходимо выполнить накат, чтобы результаты этих транзакций были отражены в базе данных. А для всех незавершенных на момент сбоя транзакций необходимо выполнить откат, чтобы результаты этих транзакций не были записаны в базу данных.
Это обусловлено тем, что в SQL Server не существует средств продолжения транзакции после сбоя. Таким образом, если бы для результатов частично завершенной транзакции не был выполнен откат, база данных оказалась бы в несогласованном состоянии (возможно, даже с повреждениями структуры, в зависимости от операции, выполнявшейся транзакцией в момент сбоя).
Каким образом процедура восстановления узнает, что следует делать? Все процедуры восстановления зависят от того факта, что каждая запись журнала помечена регистрационным номером транзакции в журнале (LSN). Регистрационный номер транзакции в журнале является возрастающим номером из трех частей, однозначно определяющим положение записи журнала в журнале транзакций. Все записи журнала в транзакции хранятся в последовательном порядке в журнале транзакций и содержат код транзакции и LSN предыдущей записи транзакции. Другими словами, каждая операция, зарегистрированная в качестве части транзакции, имеет обратную «ссылку» на операцию, непосредственно ей предшествующую.
В простом случае отката одной транзакции механизм восстановления может быстро и без труда проследовать по цепочке записанных в журнал операций, от самой последней до первой операции, и обратить результаты всех операций в обратном их выполнению порядке. Страницы базы данных, подвергшиеся воздействию транзакции, находятся либо все еще в буферном пуле, либо уже на диске. В любом случае гарантируется, что доступное изображение страницы несет на себе последствия выполнения транзакции, и их необходимо отменить.
Во время восстановления после сбоя механизм более сложен. Тот факт, что страницы базы данных не записываются на диск при фиксации транзакции, означает, что нет гарантии того, что набор страниц базы данных на диске точно отражает набор изменений, описанных в журнале транзакций — как для зафиксированных, так и для незафиксированных транзакций. Однако, имеется последний кусочек паззла, о котором я еще не упоминал — в заголовке страницы всех страниц базы данных имеется поле (96-байтная часть 8192-байтной страницы, содержащая метаданные с информацией о странице), содержащее LSN последней записи журнала, оказавшей влияние на страницу. Это дает возможность системе восстановления принять решение относительно конкретной записи журнала, которую необходимо восстановить.
- Для записи журнала из зафиксированной транзакции, в которой страница базы данных имеет LSN не меньший, чем LSN записи журнала, не требуется никаких действий. Результаты воздействия записи журнала уже записаны в страницу на диске.
- Для записи журнала из зафиксированной транзакции, в которой страница базы данных имеет LSN, меньший, чем LSN записи журнала, необходимо выполнить накат записи журнала, чтобы обеспечить сохранение результатов транзакции.
- Для записи журнала из незафиксированной транзакции, в которой страница базы данных имеет LSN, не меньший, чем LSN записи журнала, необходимо выполнить откат записи журнала, чтобы результаты транзакции не были сохранены.
- Для записи журнала из незафиксированной транзакции, в которой страница базы данных имеет LSN, меньший, чем LSN записи журнала, не требуется никаких действий. Результаты воздействия записи журнала не были сохранены на странице на диске, и в таком случае ничего делать не требуется.
Механизм восстановления после сбоя прочитывает журнал транзакций и обеспечивает сохранение всех результатов зафиксированных транзакций в базе данных, а результаты всех не зафиксированных транзакций не сохраняются в базе данных — выполняются фазы REDO и UNDO, соответственно. По завершении восстановления после сбоя база данных становится согласованной с точки зрения транзакций и доступной для использования.
Ранее упоминалось, что одним из применений операции контрольной точки является сокращение количества времени, занимаемого процедурой восстановления после сбоя. Периодическое сбрасывание на диск всех «грязных» страниц сокращает число страниц, измененных зафиксированными транзакциями, но изображений которых еще нет на диске. Это, в свою очередь, сокращает число страниц, к которым требуется применять восстановление REDO во время восстановления после сбоя.
Журнал транзакций
Восстановление после сбоя возможно только в том случае, если не пострадал журнал транзакций. На деле журнал транзакций является самой важной частью базы данных — это единственное место, в котором в случае сбоя гарантируется наличие описаний всех изменений базы данных.
Если журнал транзакций отсутствует или поврежден после сбоя, тогда восстановление после сбоя выполнить невозможно, в результате чего база данных становится сомнительной. В этом случае базу данных необходимо восстанавливать из резервных копий или использовать для восстановления менее желательные режимы, такие как аварийное восстановление. (Эти процедуры выходят за рамки данной статьи, но будут глубоко обсуждаться в последующих статьях в течение этого года.)
Журнал транзакций представляет собой специальный файл, необходимой любой базе данных для надлежащего функционирования. В нем содержатся записи журнала, создаваемые в процессе ведения журнала, и журнал используется для повторного чтения этих записей во время восстановления (или любого другого, упоминавшегося ранее, использования процедуры ведения журнала). Так же, как пространство, занятое собственно записями журнала, транзакция в журнале транзакций резервирует также пространство для любых потенциальных записей журнала, которые потребовались бы в случае необходимости отменить транзакцию и выполнить откат. Этим объясняется поведение, которое можно наблюдать, когда, например, для транзакции, обновляющей 50 МБ данных в базе данных, на деле в журнале транзакций может потребоваться пространство в 100 МБ.
Когда создается новая база данных, журнал транзакций, по существу, пуст. По мере возникновения транзакций записи журнала последовательно записываются в журнал транзакций, из чего следует, что создание нескольких файлов журнала транзакций не дает никакого выигрыша в производительности, что является широко распространенным заблуждением. Журнал транзакций будет использовать все файлы журнала по очереди.
В журнале транзакций могут перемежаться записи журнала для параллельных транзакций. Следует помнить о том, что записи журнала для одной транзакции связаны посредством своих LSN, поэтому нет необходимости все записи журнала, относящиеся к одной транзакции, группировать в одном журнале. Практически, номера LSN можно представлять себе как метку времени.
Физическая архитектура журнала транзакций показана на рис. 1. Внутренне он разбит на небольшие части, называемые виртуальными файлами журналов (или файлами VLF). Это просто вспомогательные средства для облегчения внутреннего управления журналом транзакций. Когда файл VLF заполняется, процедура ведения журнала автоматически переходит к следующему VLF в журнале транзакций. Можно было бы подумать, что, в конце концов, журнал транзакций столкнется с нехваткой места, но именно в этом вопросе журнал транзакций решительно отличается от файлов данных.

Рис. 1 Физическая архитектура журнала транзакций
В действительности журнал транзакций является кольцевым файлом, поскольку записи журнала в начале журнала транзакций отбрасываются (или очищаются). Затем, когда процедура ведения жунала достигает конца журнала транзакций, она снова заворачивает в начало и начинает писать поверх того, что было там ранее.
Итак, как осуществляется отбрасывание записей журнала, позволяющее занимаемое ими пространство использовать повторно? Запись журнала транзакций становится не нужной, если имеют место следующие факты.
- Транзакция, частью которой является эта запись, зафиксирована.
- Все страницы базы данных, которые она изменила, записаны на диск процедурой контрольной точки.
- Данная запись журнала не требуется для резервного копирования (полного, выборочного или журнала).
- Эта запись журнала не требуется никакому компоненту, читающему журнал (например, средству зеркального отображения базы данных или репликации).
Запись журнала, потребность в которой сохраняется, называется активной, и файл VLF, имеющий по крайней мере одну активную запись журнала, также называется активным. Время от времени журнал транзакций проверяется с целью выяснения, являются ли активными все записи журнала в заполненном VLF, или нет; если они все не активны, VLF помечается как отброшенный (что означает, что VLF можно перезаписывать, когда исчерпается свободное место в журнале транзакций). Когда VLF отбрасывается, он никак не перезаписывается и не опустошается, а просто помечается как отброшенный и впоследствии может быть использован повторно.
Этот процесс называется усечением журнала, что не следует путать с реальным сокращением размера журнала транзакций. При усечении журнала никогда не изменяется физический размер журнала транзакций, а изменяется только состояние частей журнала транзакций на активное или неактивное. На рис. 2 показан журнал транзакций из рис. 1 после проведения усечения.

Рис. 2 Журнал транзакций после усечения журнала
Активные VLF образуют логический журнал, являющийся частью журнала транзакций, содержащей активные записи журналов. Сама база данных знает, с какого места процедура восстановления после сбоя должна начинать чтение записей журнала в активной части журнала — с начала самой старой активной транзакции в журнале, MinLSN (она хранится в загрузочной странице базы данных).
Процедуре восстановления после сбоя не известно, в каком месте следует прекратить чтение записей журнала, поэтому она продолжает до тех пор, пока не достигнет пустого раздела журнала транзакций (если журнал транзакций еще не исчерпал свое свободное пространство) или записи журнала, чьи биты четности не соответствуют последовательности из предыдущей записи журнала.
По мере того, как файлы VLF становятся отброшенными, а новые файлы — активными, логический журнал перемещается в физическом файле журнала транзакций и, в конце концов, вынужден снова завернуть в начало, как показано на рис. 3.

Рис. 3 Циклический характер журнала транзакций
Проверка того, возможно ли усечение журнала при каком либо из следующих условий:
- При возникновении контрольной точки в модели восстановления SIMPLE или в других моделях восстановления, если никогда не выполнялось полное резервное копирование. (При этом предполагается, что база данных, после вывода из модели SIMPLE, остается в модели восстановления псевдо-SIMPLE до тех пор, пока не будет выполнено полное резервное копирование базы данных.)
- При завершении резервного копирования журнала.
Следует помнить, что усечение журнала может оказаться невозможным, поскольку существует много причин, по которым запись журнала должна оставаться активной. Если усечение журнала невозможно, файлы VLF не могут быть отброшены, и, в конечном счете, журнал должен увеличить свой размер (или должен быть добавлен еще один журнал транзакций). Чрезмерное разрастание журнала транзакций может привести к проблемам с производительностью вследствие эффекта, известного под названием фрагментация VLF. Устранение фрагментации VLF иногда может привести к впечатляющему повышению производительности действий, связанных с журналом.
Усечению журнала могут воспрепятствовать две широко известные проблемы:
- Длительно выполняющаяся активная транзакция. Весь журнал транзакций, с первой записи журнала из самой старой активной транзакции, никогда не может быть усечен до тех пор, пока эта транзакция не будет зафиксирована или аварийно завершена.
- Переключение на модель восстановления FULL, выполнение полной резервной копии и полный отказ от создания резервных копий журнала. Весь журнал транзакций остается активным в ожидании резервного копирования процедурой резервного копирования журнала.
Если журнал транзакций исчерпал весь объем и не может продолжить дальнейшее увеличение, поступает сообщение об ошибке 9002, и вам потребуется предпринять шаги для предоставления дополнительного пространства, например увеличить объем файла журнала, добавить еще один файл журнала или устранить все, что мешает усечению журнала.
Ни при каких обстоятельствах не следует удалять журнал транзакций, пытаться восстановить его с помощью недокументированных команд или просто обрезать его с помощью параметров NO_LOG или TRUNCATE_ONLY команды BACKUP LOG (которая удалена из SQL Server 2008). Эти параметры приведут либо к несогласованности с точки зрения транзакций (и, что более вероятно, к повреждению файла), либо лишат возможности надлежащего восстановления базы данных.
Модели восстановления
Как вы видите, поведение журнала транзакций частично зависит от модели восстановления, используемой базой данных. Существуют три модели восстановления, и все они оказывают влияние на поведение журнала транзакций и способ регистрации операций, либо на и на то, и на другое.
Модель восстановления FULL подразумевает, что регистрируется каждая часть каждой операции, и это называется полной регистрацией. После выполнения полного резервного копирования базы данных в модели восстановления FULL в журнале транзакций не будет проводиться автоматическое усечение до тех пор, пока не будет выполнено резервное копирование журнала. Если вы не намерены использовать резервные копии журнала и возможность восстановления состояния базы данных на конкретный момент времени, не следует использовать модель восстановления FULL. Однако, если вы предполагаете использовать зеркальное отображение базы данных, тогда у вас нет выбора, поскольку оно поддерживает только модель восстановления FULL.
Модель восстановления BULK_LOGGED обладает такой же семантикой усечения журнала транзакций, как и модель восстановления FULL, но допускает частичную регистрацию некоторых операций, что называется минимальной регистрацией. Примерами являются повторное создание индекса и некоторые операции массовой загрузки — в модели восстановления FULL регистрируется вся операция.
Но в модели восстановления BULK_LOGGED регистрируются только изменения распределения, что радикально сокращает число создаваемых записей журнала и, в свою очередь, сокращает потенциал разрастания журнала транзакций.
Модель восстановления SIMPLE, фактически ведет себя с точки зрения ведения журнала так же, как и модель восстановления BULK_LOGGED, но имеет совершенно другую семантику усечения журнала транзакций. В модели восстановления SIMPLE невозможны резервные копии журнала, что означает, что журнал может быть усечен (если ничто не удерживает записи журнала в активном состоянии) при возникновении контрольной точки. Для каждой из этих моделей имеются доводы за и против, выраженные в терминах возможных (или требуемых) вариантов резервных копий и возможности восстановления состояния на разные моменты времени (эти вопросы будут обсуждаться позднее в этом году в другой статье).
Заключение
В действительности эта статья была скорее академическим обсуждением того, как работает важнейшая часть SQL Server. Надеюсь, мне удалось избавить вас от заблуждений, которые, возможно, у вас были. Если для вас это первое знакомство с ведением журнала и процедурой восстановления, мне бы хотелось, чтобы из этой статьи вы уяснили следующие важные моменты:
- Не создавайте несколько файлов журналов, поскольку это не приводит к выигрышу в производительности.
- Помните о том, какая модель восстановления используется вашей базой данных, и о влиянии, оказываемом ею на журнал транзакций, особенно о том, возможно ли при возникновении контрольной точки автоматическое усечение, или нет.
- Учитывайте возможность разрастания журнала транзакций, факторы, приводящие к этому, и способы возвращения контроля за этим процессом.
- Узнайте, где искать справочную информацию при устранении неполадок, связанных с переполнением журнала транзакций.
Приношу благодарность Кимберли Л. Трипп (Kimberly L. Tripp) за технический обзор данной статьи.
Пол С. Рэндал (Paul S. Randal)