Неспешно прикидывая таблицу функциональности NAS обнаружил в своих инструкциях досадный пробел. Данные надо не просто хранить. Хорошо бы время от времени проверять, что всё в порядке. Ведь холодные данные на дисках имеют свойство незаметно портиться, «протухать». К счастью, у нас на NAS zfs, умеющий адресовать эту проблему.Сегодня обсудим как.
Немного теории
Перевод из Вики по ссылке выше
Проведённое NetApp исследование в реальной жизни на более чем 1,5 млн жестких дисков в течение 41 месяцев выявило более 400 000 примеров протухших данных, из которых более 30 000 не были обнаружены контроллерами аппаратных RAID. Еще одно исследование, проведенное ЦЕРН в течение шести месяцев и с участием около 97 петабайт данных, показало, что около 128 мегабайт данных были необратимо повреждены.
Но это на RAID контроллерах и дисках корпоративного класса. Ваши и мои данные на десктопном железе протухают несколько быстрее.
Традиционное решение проблемы проверки целостности данных — хранение вместе с ними контрольной суммы. Считываем данные, сверяем суммы, если OK — считаем данные не повреждёнными.
А традиционное решение проблемы восстановления повреждённых данных — избыточность. Хранение 2 и более копий (зеркало, как пример RAID1) и расчёт, хранение и сличение кодов чётности ( как пример — RAID5).
Одно из важнейших положительных свойств ZFS состоит в том, что и проверка целостности и восстановление повреждений (если есть избыточность — mirror или raidz) производится автоматически на уровне файловой системы при любом чтении данных. Но читать все данные не всегда удобно. Есть команда scrub (от англ. чистить, мыть, скрести)
ВАЖНО. Во время скраба пул доступен, но его производительность уменьшается. Хотя приоритет — за другими задачами. Поэтому, к примеру, качать с-на пул торренты и одновременно делать ему скраб идея так себе. Работать будет, но долго и с избыточной нагрузкой на диски.
На практике
Из командной строки вызываетсяzpool scrub Pool
— для пула по имени Pool
Если дать ключ -s текущий скраб будет остановленzpool scrub -s Pool
В nas4free вызов команды zpool scrub выведен и в вебгуй
Через Disks|ZFS|Pools|Tools скраб можно запустить (и остановить при необходимости)
После запуска результат можно посмотреть черезzpool status
в командной строке
Или в Disks|ZFS|Pools|Information в вебгуе
На картинке выше где scan: сказано, что идёт scrub, но так как он только начался, оставшееся время определить нельзя, надо подождать. Со временем скорость растёт, но для больших пулов полная проверка запросто может продлиться порядка суток. Скорость зависит от
— производительности процессора
— заполненности пула (в отличие от аппаратных RAID пустое место НЕ читается)
— скорости дисков. Особенно если диск при смерти, скраб может затянуться очень надолго.
Я рекомендую после запуска скраба взглянуть на статус сразу и ещё раз минут через пять. В норме все три правых столбца должны быть нулями. Но нередко там появляются небольшие цифры — это как раз сообщение о том, что скраб проверяет и по возможности исправляет данные (и метаданные).
Если на одном из дисков лезет несколько десятков (и более) ошибок — у вас проблема. Скорее всего (в этом порядке) SATA кабель, сам диск, порт контроллера подыхает и нуждается в замене. Либо диску не хватает питания.
Советую остановить скраб и взглянуть в логи, на смарт этого диска и поискать корень проблемы.
Если десятки (и более) ошибок лезут на ВСЕХ дисках — НЕМЕДЛЕННО ВЫКЛЮЧАЙТЕ СКРАБ, а затем и весь NAS. Хорошие шансы, что у вас битая память. Проверяйте, гоняйте мемтест. Хотя по некоторым практическим примерам ZFS удаётся отработать львиную долю, более 99%, ошибок вызванных сбоями в памяти, всё же битая память без контроля чётности — годный способ загубить всю информацию на пуле при скрабе. Именно поэтому в идеальном мире (и в корпоративной практике) ZFS используют на ECC (то есть с аппаратным контролем чётности) памяти. Впрочем, как и остальные файловые системы. Но Intel решила, что домашний пользователь рылом не вышел для ECC. А AMD стала слишком слаба, чтобы спорить хотя было время…
Кстати, скраб можно запускать по крону. Но именно из-за возможности вляпаться в битую память я этого делать НЕ советую, если память у вас не ECC. Да, это крайне маловероятная ситуация. Битая память должна почти работать. Шалить самую малость, не вешать систему. Но всё же гадить. Поэтому у сотен камрадов, которые общаются в профильной ветке на хоботе, такого не было, чтоб битая память именно и только на zfs повлияла. Но в Сети я выловил пару сообщений. Так что хоть и крайне маловероятно — но бережёного…
И, наконец, как часто делать скраб? IMHO в домашней практике не чаще раза в месяц и не реже раза в год на каждом из пулов.
Определение
Скраб (scrub) — это процесс сканирования ZFS через данные на томе. Скрабы помогают выявлять проблемы с целостностью данных, обнаруживать недействительные данные, вызванные временными проблемами аппаратного обеспечения, и предоставлять ранние оповещения о предстоящих сбоях диска. FreeNAS упрощает планирование периодических автоматических скрабов.
Каждый том следует чистить не реже одного раза в месяц. Бит-ошибки в критических данных могут быть обнаружены ZFS, но только при чтении этих данных. Запланированные скрабы могут найти ошибки в редко читаемых данных. Количество времени, необходимое для скраба, пропорционально количеству данных по объему. Типичные скрабы занимают несколько часов или дольше.
Процесс очистки является интенсивным вводом-выводом и может отрицательно влиять на производительность. Расписание скрабов для вечеров или выходных дней, чтобы минимизировать влияние на пользователей. Удостоверьтесь, что скрабы и другая интенсивная дисковая деятельность, такая как S.M.A.R.T. тесты планируется запустить в разные дни, чтобы избежать конкуренции с диском и экстремальных воздействий.
Скрабы проверяют только используемое дисковое пространство. Чтобы проверить неиспользуемое дисковое пространство, запишите S.M.A.R.T. Тесты типа Long Self-Test выполняются один или два раза в месяц.
Скрабы планируются и управляются с помощью Storage ‣ Scrubs.
Когда создается тома, автоматически запускается скраб ZFS. Запись с таким же именем тома добавляется в Storage ‣ Scrubs. Сводку этой записи можно просмотреть с помощью Storage ‣ Scrubs ‣ View Scrubs. На рисунке ниже показаны настройки по умолчанию для тома с именем volume1. В этом примере запись была выделена, и нажата кнопка Edit (Редактировать), чтобы отобразить экран Edit (Редактировать).

Опции скраба ZFS
Volume
Тип drop-down menu. Выберите том для очистки.
Threshold days
Тип integer. Определите количество дней, чтобы предотвратить скраб после завершения последнего. Это игнорирует любое другое расписание календаря. Значение по умолчанию — кратное 7, чтобы гарантировать, что скраб всегда встречается в тот же день недели.
Description
Тип string. Дополнительное текстовое описание скраба.
Minute
Тип slider or minute selections. Если используется слайдер, скраб происходит каждые N минут. Если выбраны определенные минуты, скраб работает только с выбранными значениями минут.
Hour
Тип slider or hour selections. Если используется слайдер, скраб происходит каждые N часов. Если выбраны определенные часы, скраб работает только с выбранными значениями часа.
Day of Month
Тип slider or month selections. Если используется слайдер, скраб происходит каждые N дней. Если выбраны определенные дни месяца, скраб работает только в выбранные дни выбранных месяцев.
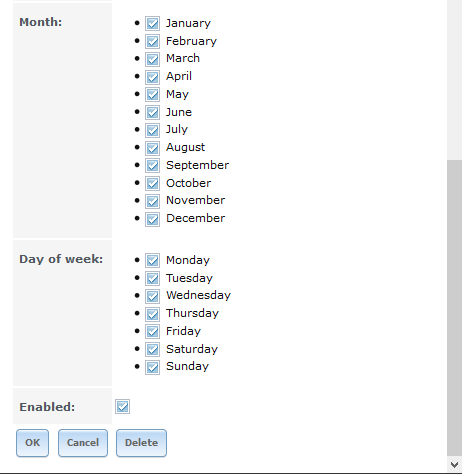
Month
Тип checkboxes. Определите месяцы для запуска скраба.
Day of week
Тип checkboxes. Скраб происходит в выбранные дни.
По умолчанию это воскресенье (Sunday), чтобы иметь наименьшее влияние на пользователей; обратите внимание, что это поле и поле Day of Month (День месяца) объединены вместе (ORed ): установка «День месяца» на 01,15 и «День недели» в четверг приведет к тому, что кусты будут работать в первый и пятнадцать дней месяца, но также и в любой четверг.
Enabled
Тип checkbox. Отключите, чтобы отключить запланированный скраб без его удаления.
Просмотрите варианты по умолчанию и, если необходимо, измените их, чтобы они соответствовали потребностям среды. Обратите внимание, что поле Threshold используется для предотвращения слишком быстрого запуска скрабов и переопределяет расписание, выбранное в других полях. Кроме того, если пул заблокирован или размонтирован, когда планируется скраб, он не будет очищен.
Запланированные скрабы можно удалить с помощью кнопки «Удалить», но это не рекомендуется. Scrubs могут обеспечить раннее указание проблем с диском перед сбоем диска. Если скраб слишком интенсивен для оборудования, подумайте о том, чтобы временно отключить кнопку «Включено» для очистки, пока аппаратное обеспечение не будет обновлено.
Как определить, какой диск вышел из строя в настройке FreeNAS / ZFS
Я строю сервер на базе FreeNAS в корпусе Supermicro X6DHE-XB 3U с 4 ГБ оперативной памяти и 16 отсеками для горячей замены SATA. Он поставляется с 2×8 портами 3Ware RAID, но я планирую просто использовать возможности ZFS вместо аппаратного RAID. Мой начальный набор дисков будет 8x2TB HITACHI Deskstar 7K3000 HDS723020BLA642.
Если бы я использовал аппаратный RAID, это дало бы мне красный свет на отсеке для дисковода, где произошел сбой диска. Как это работает с ZFS, когда диск выходит из строя? Я не думаю, что есть какая-либо гарантия, что sda = bay1, sdb = bay2 и т. Д. Так как определить, какой диск необходимо заменить? Может ли ZFS сообщить об этом контроллеру SATA, чтобы загорелся индикатор неисправного диска? Это просто сообщает серийный номер привода? Что делать, если диск выходит из строя так сильно, что не может сообщить его серийный номер? Я полагаю, что это хорошая идея записать серийный номер каждого диска и в какой отсек он вошел, прежде чем начать работу. Существуют ли какие-либо другие «подготовительные» задачи, которые облегчат замену дисков в будущем?
Ответы:
zpool status -v должен сказать вам, какой диск в сети или нет.
Текущая версия FreeNAS (версия 9.3 на данный момент) создаст gptid для каждого диска, добавленного в zpool. Сразу после создания «состояние zpool» будет выглядеть примерно так (в зависимости от конфигурации вашего пула) …
# zpool
пул состояния : myzfstest
состояние: ONLINE
scan: нет
запрошенной конфигурации:NAME STATE READ WRITE CKSUM myzfstest ONLINE 0 0 0 raidz-0 ONLINE 0 0 0 gptid/4fc2b789-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/51d38480-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/54c672cc-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/56a07638-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 raidz2-1 ONLINE 0 0 0 gptid/630e1317-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/6557b52d-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/667a1318-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/68cadf75-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 logs mirror-2 ONLINE 0 0 0 gptid/8839f22e-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/8a6d0b14-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 cache gptid/8c2f3824-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 gptid/8da9ba80-7b7f-11e4-9585-de9b81338d40 ONLINE 0 0 0 spares gptid/72f039f2-7b8a-11e4-9585-de9b81338d40 AVAIL gptid/750df91d-7b8a-11e4-9585-de9b81338d40 AVAILошибки: нет известных ошибок данных
К сожалению, веб-интерфейс не показывает эти цифры. Итак, если вы получаете сообщение об ошибке, говорящее, что «gptid / 6557b52d-7b7f-11e4-9585-de9b81338d40» плохо … как вы знаете, какой диск вытащить? Выяснение этой части требует некоторой работы во время установки.
- Когда вы строите свою систему. Запишите серийный номер каждого диска, а также запишите место, где этот диск был вставлен. Например, в случае двухстороннего JBOD вы можете отметить переднюю / заднюю, строку и столбец.
- При загрузке FreeNAS в веб-интерфейсе перейдите в раздел «Хранилище> Тома / Просмотр дисков». На этой вкладке у вас должен быть список всех ваших дисков и их серийные номера. Запишите имя диска, указанное для каждого серийного номера, который вы указали в предыдущем списке. Если вы не видите серийные номера, вам придется перейти к оболочке и ввести
smartctl -a /dev/ada0 | grep ^Serial(заменив «/ dev / ada0» на каждое из названий дисков в списке) -
Теперь в оболочке нам нужно сопоставить имена дисков со всеми числами gptid. Итак, напечатайте,
glabel statusи вы должны получить что-то вроде этого …# glabel status CORRECT>glabel status (y|n|e|a)? yes Name Status Components ufs/FreeNASs3 N/A ada0s3 ufs/FreeNASs4 N/A ada0s4 ufs/FreeNASs1a N/A ada0s1a gptid/616cddb6-7b7f-11e4-9585-de9b81338d40 N/A ada0p2 gptid/630e1317-7b7f-11e4-9585-de9b81338d40 N/A da1p1 gptid/6557b52d-7b7f-11e4-9585-de9b81338d40 N/A da2p1 gptid/667a1318-7b7f-11e4-9585-de9b81338d40 N/A da3p1 gptid/68cadf75-7b7f-11e4-9585-de9b81338d40 N/A da4p1 -
Теперь запишите все числа gptid, чтобы связать их с именами дисков и, следовательно, серийными номерами и их расположением. Примечание : когда вы видите что-то вроде «da3p1», это первый раздел диска, обозначенный как da3. Список в веб-интерфейсе будет отображать только метку «da3» для диска.
Теперь, когда появляется ошибка, говорящая о том, что диск с номером gptid xyz имеет ошибку, вы сможете ссылаться на свой лист и знать, какой диск вам нужно извлечь / заменить.
Я знаю, что это слишком поздно для оригинального плаката; но, возможно, другие найдут это полезным.
Что вам нужно, так это утилита sas2ircu от LSI (теперь Avago). LSI поддерживает версии для FreeBSD, Linux и Windwos. С FreeNAS вам потребуется версия FreeBSD.
Чтобы попробовать это, вы должны поместить его в каталог / tmp и сначала сделать его исполняемым.
Шаг первый — узнать идентификатор вашего SAS HBA (пример):
/tmp# ./sas2ircu list
LSI Corporation SAS2 IR Configuration Utility.
Version 19.00.00.00 (2014.03.17)
Copyright (c) 2008-2014 LSI Corporation. All rights reserved.
Adapter Vendor Device SubSys SubSys
Index Type ID ID Pci Address Ven ID Dev ID
----- ------------ ------ ------ ----------------- ------ ------
0 SAS2008 1000h 72h 00h:04h:00h:00h 1000h 3020h
SAS2IRCU: Utility Completed Successfully.
Шаг второй будет генерировать список всех ваших устройств, которые вы можете проверить позже:
/tmp# ./sas2ircu 0 display > disklist.txt
Шаг 3 изучает ваш список дисков. Это будет выглядеть так:
/tmp# vi disklist.txt
LSI Corporation SAS2 IR Configuration Utility.
Version 19.00.00.00 (2014.03.17)
Copyright (c) 2008-2014 LSI Corporation. All rights reserved.
Read configuration has been initiated for controller 0
------------------------------------------------------------------------
Controller information
------------------------------------------------------------------------
Controller type : SAS2008
BIOS version : 7.37.00.00
Firmware version : 19.00.00.00
Channel description : 1 Serial Attached SCSI
Initiator ID : 0
Maximum physical devices : 255
Concurrent commands supported : 3432
Slot : 4
Segment : 0
Bus : 4
Device : 0
Function : 0
RAID Support : No
------------------------------------------------------------------------
IR Volume information
------------------------------------------------------------------------
------------------------------------------------------------------------
Physical device information
------------------------------------------------------------------------
Initiator at ID #0
Device is a Enclosure services device
Enclosure # : 2
Slot # : 24
SAS Address : 5003048-0-00d3-a87d
State : Standby (SBY)
Manufacturer : LSI CORP
Model Number : SAS2X36
Firmware Revision : 0717
Serial No : x36557230
GUID : N/A
Drive Type : Undetermined
Device is a Enclosure services device
Enclosure # : 3
Slot # : 0
SAS Address : 5003048-0-00ca-7bfd
State : Standby (SBY)
Manufacturer : LSI CORP
Model Number : SAS2X28
Firmware Revision : 0717
Serial No : x36557230
GUID : N/A
Drive Type : Undetermined
Device is a Hard disk
Enclosure # : 4
Slot # : 0
SAS Address : 5003048-0-00d3-a8cc
State : Ready (RDY)
Size (in MB)/(in sectors) : 1907729/3907029167
Manufacturer : ATA
Model Number : WDC WD20EARS-00M
Firmware Revision : AB51
Serial No : WDWCAZA1037887
GUID : N/A
Drive Type : Undetermined
Device is a Hard disk
Enclosure # : 4
Slot # : 1
Шаг 4 идентифицирует неисправный диск — вы узнаете, по какой отсутствующей или поврежденной информации, сообщенной на диске. Получите Enclosure # и Slot # и используйте их, чтобы мигать индикатор лотка на шаге 5: чтобы найти Enclosure # 4, Slot # 0
/tmp# ./sas2ircu 0 locate 4:1 ON
Чтобы выключить светодиод после замены:
/tmp# ./sas2ircu 0 locate 4:1 OFF
Надеюсь, это поможет!
Посмотрите на тома.
Выберите громкость, которая ухудшена.
В нижней части экрана есть три варианта … нажмите Состояние громкости
Теперь вы увидите крупным планом том и его отдельные жесткие диски, перечисленные что-то вроде ada3p2, ada5p2, ada6p2, ada4p2 и т. Д.
Выберите ухудшенный диск.
В нижней части экрана вы увидите два варианта; Редактировать диск и заменить
Выберите Редактировать диск
Теперь вы должны увидеть серийный номер поврежденного диска.
Выключите сервер FreeNAS и найдите этот диск.
Это предполагает, что у вас есть дело, которое имеет отдельные огни HD (иначе серверное дело)
Найти список для диска, это плохо. Пример / dev / da9, /dev/sda…etc
Отключите этот диск, используя команды терминала GUI или FreeNAS.
Выполните DD, чтобы прочитать этот диск в / dev / null, пока вы смотрите на лицевую сторону сервера на свет, который сейчас безумно мигает.
sudo dd if=/dev/da# of=/dev/null
Запомните расположение диска, отмените команду DD (ctrl-c), а затем перейдите к способу замены. Для freeNAS загрузите новый диск, затем нажмите кнопку замены графического интерфейса и завершите этот процесс. Когда закончите, удалите плохой диск и делайте с ним все, что хотите. Проверьте это больше, Защитите его, физически уничтожьте, отправьте на гарантийный ремонт ….. и т. Д.
Самый простой способ, который я нашел.
нажмите хранилище нажмите просмотреть диски.
вытащите один кабель sata. Распечатайте наклейку с отсутствующим диском со смотрового диска, он же наклейка с наклейкой ada1, в сторону диска
переподключите диск. отсоедините второй кабель sata от печатной этикетки ada2 и т.
затем, когда диск выходит из строя, вы знаете его ADA2
Если на вашем сервере NAS есть проблемы с дисками и вам необходимо проверить файловую систему,
следует зайти на него под учётной записью root и выполнить:
df
Например вывод этой команды:
Filesystem 1K-blocks Used Available Use% Mounted on
rootfs 2451064 437412 1911252 19% /
/dev/root 2451064 437412 1911252 19% /
/tmp 255700 272 255428 1% /tmp
/dev/vg1/volume_1 2879621632 176443652 2703075580 7% /volume1
/dev/vg1/volume_1 2879621632 176443652 2703075580 7% /opt
для просмотра всех примонтированных разделов, далее посмотрим какие программы пишут на разделы:
lsof /opt/
lsof /volume1/
Вывод этой команды покажет какие процессы пишут на раздел:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
postgres 5052 admin cwd DIR 253,0 4096 18 /volume1/@database/pgsql
postgres 5057 admin cwd DIR 253,0 4096 18 /volume1/@database/pgsqlОстанавливаем все процессы, так как надо отмонтировать раздел:
/usr/syno/etc/rc.d/S20pgsql.sh stopОтмонтировать раздел необходимо командой:
umount /volume1/
umount /optПосле этого мы можем проверить файловую систему:
fsck.ext4 -v /dev/vg1/volume_1
или e2fsck -p -y -f -v /dev/vg1/volume_1После этого можем перезагрузить сервер:
rebootЕсть проблемы с установкой Linux сервера ? Обращайтесь - [email protected]
Welcome back, everyone! While we are at it, let’s keep the FreeNAS tutorials coming. Today you will learn another Essential: How to set up SMART Tests and Scrubs.
It is important that you run both of them on a regular basis to ensure disk health and keep your filesystem clean. I will quickly explain the difference between the two and show you how to set them up on a schedule that makes sense. We are going to use the excellent instructions of Cyberjock, a moderator of the FreeNAS Forums as a guideline. If you are new to FreeNAS and want to learn how to install it, check out this article.
What are Scrubs
Scrubs on a ZFS Volume helps you to identify data integrity problems, detect silent data corruptions, and provide you with early alerts to disk failures. It also cleans up your disks. Scrubs only checks used disk space; that’s why we also use SMART tests to check the whole disk’s health. It’s the regular maintenance for ZFS Volumes / Pools. Scrubs can take a very long time if you have a large volume. That’s why we schedule them at night time.
What are S.M.A.R.T tests
SMART tests are internal drive tests. There are 2 kinds of S.M.A.R.T tests, Long and Short. Short tests can only take 5 minutes, where Long tests can run several hours. SMART tests are non-destructive, but they run on a per-disk interval, so it only runs on one disk at a time. S.M.A.R.T tests are essential for keeping track of your disk health. You also don’t want to schedule short and long tests at the same time.
The Schedule
We are using the following schedule for our tests.
- SCRUBS: Every 1st and 15th of the month at 4 am. The threshold on 10 days.
- Short S.M.A.R.T tests: Every 5th, 12th, 19th, and 26th of the month at 3 am.
- Long S.M.A.R.T tests: Every 8th and 22nd at 4 am.
So let’s go ahead and start setting up our Scrubs first.
Step 1 – Setting up Scrubs
Navigate to Storage -> Scrubs -> Your Volume -> Select your Volume -> Edit
Enter everything as in the screenshot below.
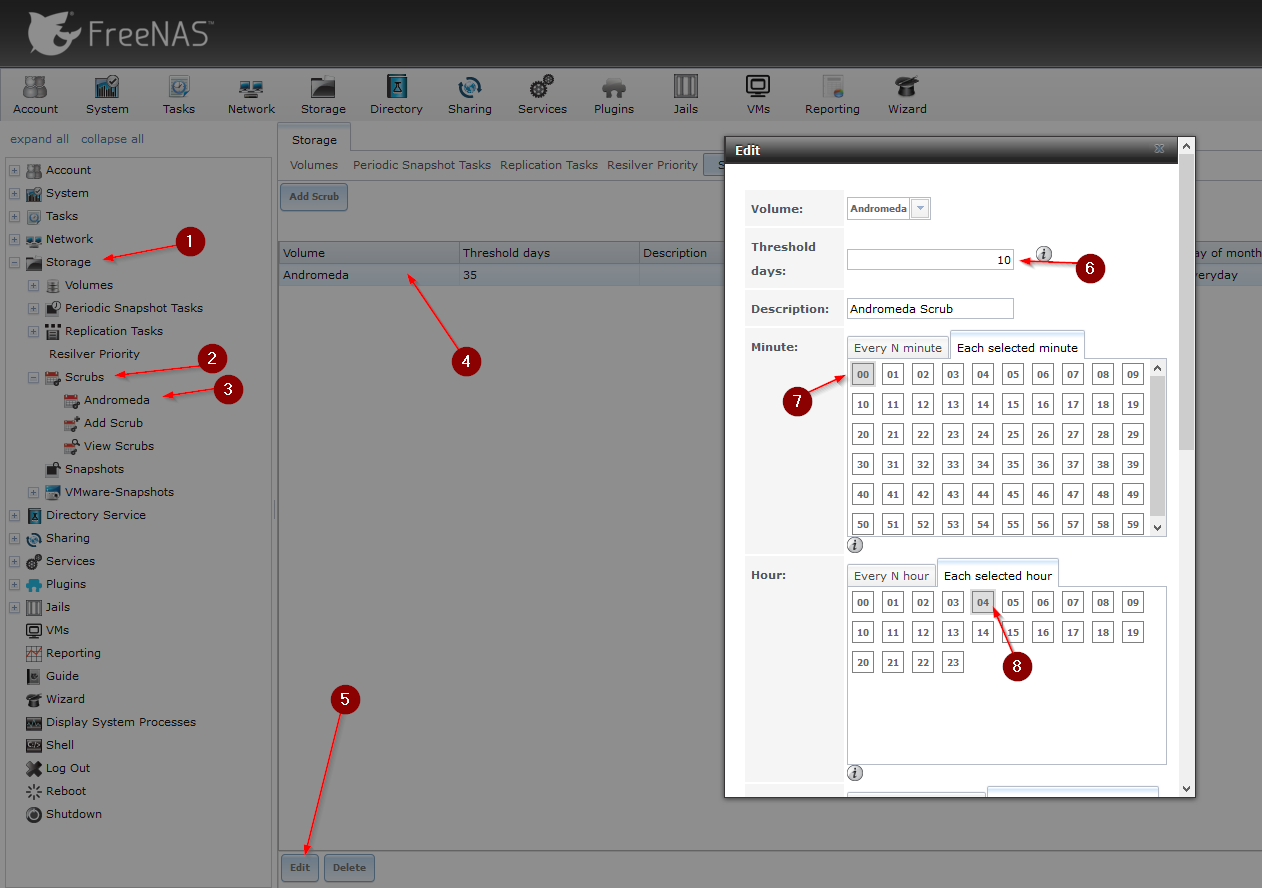
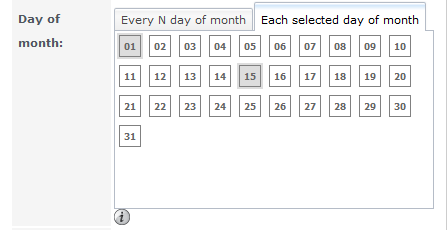
When you’re done, click on View Scrubs, and you should see something like this:

That’s it. We are already done with setting up Scrubs.
Step 2 – Setting up the short S.M.A.R.T test
Navigate to Tasks -> S.M.A.R.T Test -> Add S.M.A.R.T Test.
Select all Disks you want to include in the test. (If you have FreeNAS installed on an SSD like me, exclude the SSD from the test, as it makes no sense to run it there). Adjust everything as in the screenshot below.
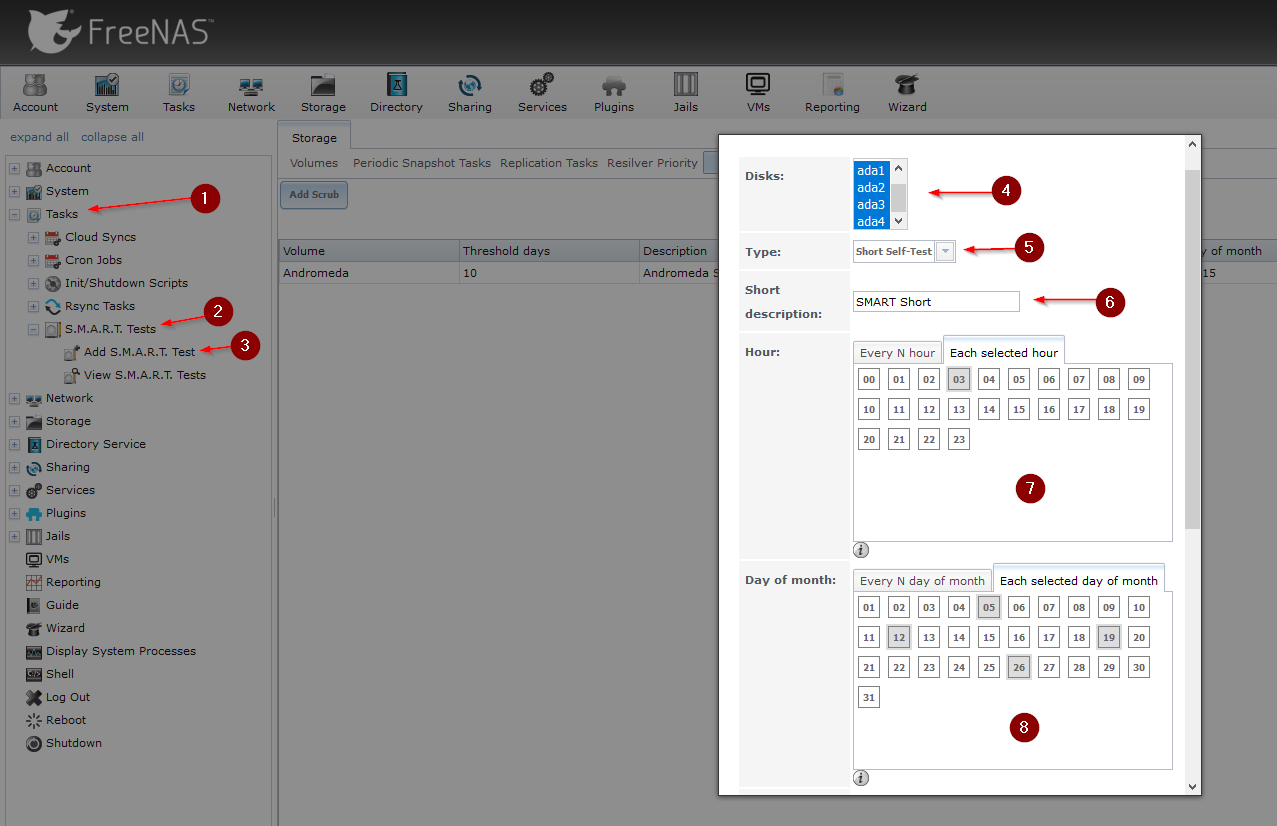
And the short SMART test is completely set up.
Step 3 – Setting up the long S.M.A.R.T test
Click on Add S.M.A.R.T Test once again and adjust everything as in the screenshots below.
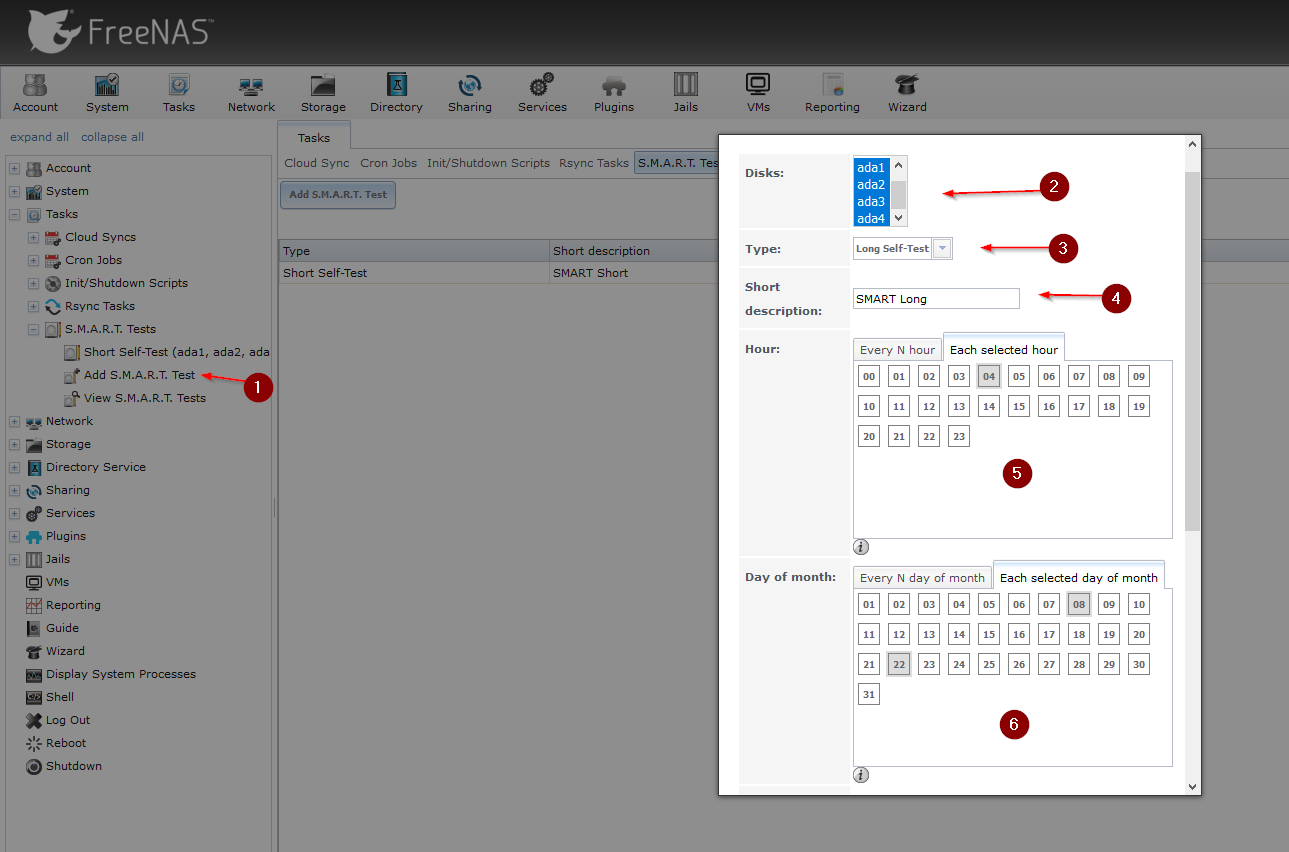
And that’s it. Click on View S.M.A.R.T Tests, and you should see something along those lines.

Conclusion
Running S.M.A.R.T tests and Scrubs is essential for keeping your disks healthy and clean. I would recommend following the schedule above; it has proven to work very well for me over the last couple of years.
ℹ️ Related Articles
👉 My Popular DIY FreeNAS Build
👉 Use FreeNAS as an UniFi Controller
👉 FreeNAS Smart Tests & Scrubs
👉 How to install Plex Media Server on FreeNAS
👉 How to install FreeNAS
👉 How to create Windows Shares on FreeNAS
👉 Manually Update Plex Media Server on FreeNAS
👉 Upgrade FreeNAS to TrueNAS
Stefan is the founder & creative head behind Ceos3c.
Stefan is a self-taught Software Engineer & Cyber Security professional and he helps other people to learn complicated topics.
4.5 Тесты S.M.A.R.T.
S.M.A.R.T. (Технология самоконтроля, Анализа и Отчётности) — система мониторинга приводов жёстких дисков компьютера, предназначенная для обнаружения и информирования о различных индикаторах состояния диска. Когда возникают ошибки S.M.A.R.T., диск должен быть заменён. Большинство современных приводов дисков ATA, IDE и SCSI-3, поддерживают S.M.A.R.T. — вам следует обратиться к документации на жёсткий диск, если вы не уверены в этом.
Рисунок 4.5а показывает экран конфигурации который доступен при щелчке на пункт System-> S.M.A.R.T. Tests->Add S.M.A.R.T. Test. Тесты которые вы создадите, будут доступны в списке, который можно просматривать на вкладке View S.M.A.R.T. Tests. После создания собственных тестов, проверьте конфигурацию в Services-> S.M.A.R.T., затем нажмите на слайдер ON для запуска сервиса S.M.A.R.T. на странице Services->Control Services. Сервис S.M.A.R.T. не будет запущен, если вы не создали любых томов.
ПРИМЕЧАНИЕ: для предотвращения проблем, не включайте сервис S.M.A.R.T. если ваши диски управляются контроллером RAID, поскольку контролем S.M.A.R.T. занимается сам контроллер и могут возникать ошибки при использовании обоих методов.
Рисунок 4.5а: Добавление теста S.M.A.R.T.
Таблица 4.5а суммирует опции конфигурации доступные при создании теста S.M.A.R.T.
Таблица 4.5а: Опции теста S.M.A.R.T.
- Disk (Диск) список контролируются подсвеченные диски
- Type (Тип) выпадающее меню выбор типа запускаемого теста; смотрите smartctl(8) для описания каждого типа теста (заметьте, что некоторые типы тестов снижают производительность дисков или переводят диски в offline)
- Short description (Краткое описание) строка опционально
- Hour (Часы) слайдер или выбор часов если используется слайдер, тест выполняется каждые N часов; если используется выбор, тест выполняется в подсвеченные часы
- Day of month (Дни месяца) слайдер или выбор часов если используется слайдер, тест выполняется каждые N дней; если используется выбор, тест выполняется в подсвеченные дни
- Month (Месяц) флаги выберите месяцы в которые будет выполняться ваш тест
- Day of week (Дни недели) флаги выберите дни недели в которые будет выполняться ваш тест
4.6 Настройки
Закладка Settings, показанная на рисунке 4.6а, содержит 4 вкладки: General (Общие), Advanced (Расширенные), Email (Электронная почта) и SSL.
Рисунок 4.6а: Закладка General страницы Settings
4.6.1 Закладка General
Таблица 4.6a суммирует настройки которые могут быть сконфигурированы с использованием закладки General:
Таблица 4.6а: Настройки конфигурации закладки General
- Protocol (Протокол) выпадающее меню протокол который будет использоваться для соединения с GUI; если вы изменили значение по умолчанию HTTP на HTTPS, будут сгенерированы неподписываемый сертификат и ключ RSA и вы для входа вам будет необходимо подтвердить сертификат.
- WebGUI Address (Адрес WebGUI) выпадающее меню выберите из списка соответсвующие IP адреса для ограничения доступа к административному GUI; встроенный сервер HTTP автоматически привязан к шаблону адреса 0.0.0.0 (любой адрес) и выдаст предупреждение, если указанный адрес станет недоступным.
- WebGUI Port (Порт WebGUI) целое позволяет вам конфигурировать нестандартный порт для доступа к административному GUI
- Language (Язык) выпадающее меню выберите локализацию интерфейса из выпадающего меню; потребуется перезагрузка браузера; вы можете просматривать статус локализации на pootle.freenas.org
- Console keyboard map (Раскладка клавиатуры консоли) выпадающее меню выберите раскладку клавиатуры
- Timezone (Временная зона) выпадающее меню выберите временную зону из выпадающего меню
- Syslog server (Сервер syslog) строка IP адрес или имя хоста удалённого сервера syslog для передачи журналов FreeNAS; после установки, записи журнала будут записываться как на консоль FreeNAS, так и на удалённый сервер syslog.
ПРИМЕЧАНИЕ: по умолчанию, журналы хранятся в RAM, поскольку на встраиваемых устройствах нет пространства для хранения журналов. Важно, что эти журналы удаляются после перезагрузки системы. Если вы хотите сохранять системные журналы, следует сконфигурировать удалённый сервер syslog, создать скрипт для хранения журналов на томе и добавить скрипт в задание cron, или использовать скрипт FreeNAS-Change-Logging (https://github.com/jag3773/FreeNAS-Change-Logging).
Если вы провели любые изменения, нажмите кнопку Save.
Кроме того, данная закладка содержит следующие кнопки:
Factory Restore (Востановить начальные установки): заменяет текущую конфигурацию на значения по умолчанию. Следует помнить, что все ваши настройки будут стёрты, но это бывает удобно, если вы испортили систему и захотите вернуться к исходной конфигурации.
Save Config (Сохранение конфигурации): используется для создания резервной копии текущей базы данных конфигурации в формате «имя_хоста-версия-архитектура». Всегда сохраняйте конфигурацию после внесения изменений и перед выполнением обновления.
Upload Config (Загрузка конфигурации): позволяет вам найти местоположение сохранённого файла конфигурации для восстановления предыдущей конфигурации.
продолжение следует…
UPDATE: 22 September 2018 — Added Drive Data Refreshing
UPDATE: 2 April 2017 — Added support for FreeNAS Corral (FreeNAS 10 and beyond)
UPDATE: 1 November 2020 — Added ID 1 and 7 description for Seagate drives at bottom of Appendix B
This guide covers the most routine single hard drive failures that are encountered and is not meant to cover every situation, specifically we will check to see if you have a physical drive failure or a communications error. If this guide fails to solve your problem, please open a new thread in the Help forum, list your hardware specs (FreeNAS version, Hardware Configuration), your failure and all indications, and specify that you used this guide and the step which failed to help you if appropriate. If there is an error or improvement you would like to suggest to this procedure, contact one of the forum moderators or the author and your inputs will be evaluated.
How to use this guide:
1. It is assumed you have some knowledge on how to open up a Shell window and perform some minor Linux/FreeBSD commands.
2. All the steps in this guide are non-destructive so you can safely perform these steps without further risk to your data.
3. We cannot take into account all formats of an error message but we used “?” to indicate any value. Additionally if we list an error message format, please keep in mind that as the software changes, the format may change and we will not update the guide every time a minor format of a message occurs.
4. The drive identifier in each command will be “ada0” however the user must enter the identifier for the suspect drive such as “ada4” or maybe “da4”. The failure message should indicate the drive identifier.
5. Once you have identified the failed drive serial number, write it down because drive identifiers “ada0” can change and the serial number is the best way to track and replace your drive if required.
6. You may be referenced to use the FreeNAS User Manual to conduct specific procedures.
7. Appendix A: Examples Error Messages
8. Appendix B: S.M.A.R.T. Data, What’s Important to Me?
9. Appendix C: Extra Troubleshooting — Drive Data Refreshing and Bad Blocks
Routine Procedures:
These few procedures will be run often so to minimize placing these steps all over the procedure, they will be written here and the user will refer here when directed to run one of them.
Output SMART Status Results
This procedure will display the hard drive data, including error information.
1) Open a shell (can be done via the GUI or SSH using something like Putty). If using FreeNAS 10 from the GUI Console, type «shell» to enter the shell and type «exit» when completed, for FreeNAS 11.x or greater you may select «Shell» from the lefthand pane.
2) Type smartctl –a /dev/ada0 where “ada0” is the subject drive. If the output scrolls off the screen then enter smartctl –a /dev/ada0 | more and the screen will only fill one page at a time.
3) Note the items asked about in the troubleshooting text.
4) The following output does not mean the hard drive completely passed, this is a terrible summary and all the data must be examined to ensure no errors exist(ed):
Code:
=== START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED
Perform SMART Long Test
A SMART Long Test conducts a test of the drive electronics and a read of the entire drive surface. This test should be run periodically by setting it up in the FreeNAS GUI for automatic accomplishment. Different users have different opinions on how frequently this should be done, the author prefers once a week for the Long tests and daily for the Short tests.
1) Open a shell (can be done via the GUI or SSH using something like Putty).
2) Type smartctl –t long /dev/ada0 where “ada0” is the drive identifier. Note how long it will take for the test to complete. You may still use your system however it will slow down the testing.
3) Once the period of time has lapsed for the testing, obtain a SMART Status Result and return to the troubleshooting text.
What type of failure did you received?
1) Error stating:
a. ID 5 Relocated Sector Count, ID 197 Current Pending Sector Count, ID 198 Offline, Uncorrectable Sector Count, or (?da?:ata?:?:?:?): CAM status: ATA Status Error, Pool is Degraded, or if you just don’t know where to start.
b. Timeout errors or any Communication Errors (ID 199 UDMA CRC Error Count).
2) If “a” then goto step 3, If “b” then goto step 4.
Physical Drive Failure
3) This procedure troubleshoots common physical drive failures.
a. Conduct Output SMART Status Results and record the drive Serial Number, IDs 5, 197, and 198. (Note: For detailed explanation of what each of these IDs represent, visit the S.M.A.R.T. Wiki website)
b. If any of the IDs are greater than zero (0) then the drive has failed for RMA purposes.
c. If ALL of the IDs are zero (0), then run a SMART Long Test and after the test has completed, conduct Output SMART Status Results. If ALL of the IDs are still at zero (0), ensure you are troubleshooting the correct drive and if you are, proceed to step 4 because the hard drive does not indicate a hardware failure at this point.
d. If any of the IDs are 1 to 5 then you may be able to retain the drive however if you’re troubleshooting it, it’s not likely you desire to retain the drive even if it’s slowly failing. If you do retain it, it’s highly recommended that you run frequent SMART Long Tests on the drive to ensure the IDs values do not increase. If they increase at all then replace the drive.
e. If replacing the drive follow the FreeNAS User Guide on how to replace a failed drive. If you have an encrypted drive, ensure you take appropriate precautions per the FreeNAS User Guide.
f. Exit this guide.
Drive Communications Failure
4) This procedure troubleshoots common communications errors for a single drive failure.
a. Conduct Output SMART Status Results and record the drive Serial Number, IDs 5, 197, and 198.
b. Inspect ID’s 5, 197, and 198 and if any value is greater than zero (0), the drive may have an unrelated failure. Goto to Step 3 after finishing this troubleshooting.
c. Replace the DATA cable between the hard drive (utilizing the serial number to identify the suspect drive) and controller. (Note: The data cable is the most common cause of drive communications errors.)
d. If the problem is not fixed, Swap the DATA cables between the suspect drive and a nearby drive (at the drive connections). (Note: We are trying to isolate the problem to the hard drive or something else.)
e. If the problem goes away, it’s likely the DATA cable is still the cause, you may exit this procedure however keep an eye open for future failures. (Note: At times a poor connection may cause this error or a marginal data cable.)
f. If the problem still exists, run the Output SMART Status Results and verify the drive serial number.
g. If the drive serial number changed, continue with step h, if the serial number did not change continue with step j. (Note: If the drive serial number changed then the failure could be the DATA cable or drive controller.)
h. Relocate the DATA cable for the failing drive (remember to use the serial number) to another DATA port on the controller or motherboard that does appear to be working.
i. If the failure still exists then run the Output SMART Status Results and verify the drive serial number that failed. If it has not changed then the DATA cable is suspect. Goto step k.
j. If the problem remains with the same drive then the hard drive electronics are suspect and the drive can be considered defective, replace the drive.
k. If the problem still exists, this is not a common failure and post your failure in the FreeNAS forums.
l. Exit this guide.
APPENDIX A
Example Error Messages
Hard Drive Failure Messages
Email Messages:
CRITICAL: Device: /dev/ada3, 1 Currently unreadable (pending) sectors
CRITICAL: Device: /dev/ada1, 817 Currently unreadable (pending) sectors
CRITICAL: Device: /dev/ada1, 2397 Offline uncorrectable sectors
SMART Results Output
(Note: Items in red are failure indications)
Code:
smartctl 6.3 2014-07-26 r3976 [FreeBSD 9.3-RELEASE-p28 amd64] (local build) Copyright (C) 2002-14, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Western Digital Red Device Model: WDC WD20EFRX-68AX9N0 Serial Number: WD-WMC300411000 LU WWN Device Id: 5 0014ee 6ad787ae3 Firmware Version: 80.00A80 User Capacity: 2,000,398,934,016 bytes [2.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Device is: In smartctl database [for details use: -P show] ATA Version is: ACS-2 (minor revision not indicated) SATA Version is: SATA 3.0, 6.0 Gb/s (current: 3.0 Gb/s) Local Time is: Wed Jan 27 15:41:21 2016 EST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x00) Offline data collection activity was never started. Auto Offline Data Collection: Disabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: (27840) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 2) minutes. Extended self-test routine recommended polling time: ( 281) minutes. Conveyance self-test routine recommended polling time: ( 5) minutes. SCT capabilities: (0x70bd) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 31 3 Spin_Up_Time 0x0027 176 174 021 Pre-fail Always - 4175 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 340 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 16 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 061 061 000 Old_age Always - 28532 10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 148 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 61 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 278 194 Temperature_Celsius 0x0022 120 107 000 Old_age Always - 27 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 42 198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 42 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 28522 - # 2 Short offline Completed without error 00% 28498 - # 3 Short offline Completed without error 00% 28474 - # 4 Extended offline Completed: read failure 70% 28455 - 543988376 # 5 Short offline Completed without error 00% 28426 - # 6 Short offline Completed without error 00% 28330 - # 7 Extended offline Completed without error 00% 28312 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
Hard Drive Communications Error Messages
(ada1:ahcich1:0:0:0): WRITE_FPDMA_QUEUED. ACB: 61 00 90 b2 b9 40 2e 00 00 01 00 00
(ada1:ahcich1:0:0:0): CAM status: Uncorrectable parity/CRC error
(ada1:ahcich1:0:0:0): Retrying command
APPENDIX B
S.M.A.R.T. Data, What’s Important to Me?
When troubleshooting a hard drive failure we utilize the built in SMART diagnostics, part of every hard drive. These results can be used to justify an RMA as well. A SMART test will not isolate communication errors, it will only validate the physical hard drive. If you want to get some good information visit the Wiki for S.M.A.R.T at this link: https://en.wikipedia.org/wiki/S.M.A.R.T.
The important data we look at are as follows:
1) Serial Number
2) ID 5 Relocated Sector Count
3) ID 197 Current Pending Sector Count
4) ID 198 Offline Uncorrectable Sector Count
5) ID 199 UDMA CRC Error Count
Other notable data are:
6) ID 194 Temperature
7) ID 200 MultiZone Error Rate
8) Extended Self-test Time (value in minutes)
9) SMART Self-test logs, specifically the results of the self tests
If ID’s 5, 197, or 198 have any value greater than zero (0) then there has been some defect identified in the media. If ID 194 Temperature is above 40C then you may have a cooling issue and this could shorten the life of your drive. Many manufacturers will not accept an RMA if the temperature of the drive exceeds a certain value (manufacturer specific) as this voids the warranty.
ID 199 is a communications error between the drive electronics and the drive controller. The drive controller is part of your motherboard or an add-on card. Typically this error code results in replacement of the SATA cable to correct the situation. This wouldn’t typically be a condition to RMA a drive however it is possible that the hard drive electronics has failed or someone broke the SATA connector on the drive, but that is not the typical failure we see.
ID 200 MultiZone Error Rate can be the cause of a drive failure although a value in this location doesn’t always mean it’s the fault. It is notable if there are no other failing indications.
Wear Level (ID# is manufacture specific) is the indication of the percentage of how many write operations are left. In a typical SSD you have approximately 2000 erase/write cycles per memory block (4k block) however better SSDs are being manufactured that will last longer and over-provisioning creates the illusion of longer life. If your wear level drops to zero then you will not be able to write again to your SSD and it may fail to operate at all.
The SMART Self-test logs indicate the last time you conducted a SMART test, the type of test, it’s completion status, how far it completed, and the hours of the results (Hours is a value in relation to the ID 9 Power On Hours value.)
It is always a good thing to run a SMART Long test if you doubt the integrity of your drive.
What data is not important?
Much of the other data is manufacturer specific so even if they look like they could be accurate data, odds are they are not important since there are other well known values that do maintain meaning. Let me provide you a great example of what I’m talking about, ID 1 — Raw Read Error Rate. This value represents errors in reading data, right? Yes is the answer however how the manufacturer does this is different between manufacturers and it’s all due to design. Let me explain (this is likely not accurate but it’s an attempt to show that drives handle internal functions differently):
Drive «A» is told to read XX sectors of data and it returns those sectors + the next YY sectors of data in it’s internal buffer.
Drive «B» is told to read XX sectors of data and it returns those sectors + the next YY sectors of data in it’s internal buffer.
Drive «A» next finds out that the extra YY sectors worth of data isn’t required and since it provided exactly what was requested of it, all is good in the world and it completed the operation.
Drive «B» next finds out that the extra YY sectors worth of data isn’t required but this drive is programmed differently and it has more data to provide and this creates an internal issue as the drive now thinks it read the wrong data or too much data, something. The end result is the ID 1 value is incremented.
If ID 1 is a low value then it is likely a value you could use as a failing indicator however if it’s a high number that is always changing a lot, you can just ignore it.
There are other values you can ignore and some values you should pay attention to however the most important values are listed above.
UPDATE (1 Nov 2020): How to read Seagate drive ID’s 1 and 7, but note that even if these values turn out to be greater than zero after the conversion, they are still not important unless you have other key indicators of failure:
Written by sdx1
Seagate hard drives often report extremely high read and seek error rates in SMART data. After pronouncing many such drives defective, I did some research on the subject and found that Seagate drives use non-standard formatting for read and seek error rates, and every piece of software I’ve used reports these values incorrectly. While the easiest advice on this subject is to ignore these values in the absence of other drive issues, there is a way to read them.
The Process
The vast majority of programs that read SMART data rely on smartctl (Windows download), which we’ll use to read these values.
Assuming that our disk is located at /dev/hda (which is typical for smartctl on Windows and older Linuxes), we can get the disk status using smartctl -A /dev/hda. The raw read error rate will be reported as something like 130917967 and the seek something like 13219996990. This is clearly wrong, because the drive hasn’t failed or reported any SMART errors, and the normalized value still shows this attribute to be within acceptable margins.
This is because the read and seek error rates are actually recorded as 48-bit hexadecimal values, where the first 16 bits (4 hexadecmal digits) represent the total number of read or seek errors and the last 32 bits (8 hex digits) represent the total number of reads or seeks attempted. We can get these values with the command smartctl -v 1,hex48 -v 7,hex48 -A /dev/hda.
Using this command, our read and seek error values become 0x000007cda64f and 0x000313f9253e respectively. The first four digits following the x (emphasized) are the total number of errors. As you can see, read and seek errors are only 0 and 3 respectively for this particular drive. And the total number of reads are 130917967 and 335095102 respectively, obtained by taking the last eight digits and converting from hexadecimal to decimal numbers.
APPENDIX C
Extra Testing — Drive Data Refreshing and Bad Blocks
Drive Data Refreshing
If you are having a few Pending Sector Errors during a SMART Test then you could try to simply refresh your data to your hard drive. I can’t tell you that this will make your hard drive all better but it should not hurt, provided you enter the commands properly. What this does is read all the hard drive sectors and write them back in the same locations and this is important to know as this does not read just the data you have stored, it reads the entire hard drive surface area and writes it back. This means that it is a long process (many hours) and the time it takes to complete is dependent on the size of the hard drive and how fast the hard drive is at reading and writing and any other operations the drive is doing.
1) First we need to allow you to perform RAW Write operations otherwise you will get an error message stating the operation is not permitted. Type sysctl kern.geom.debugflags=0x10 and hit Enter.
2) Next we need to use the «dd» command to read the hard drive data and then write it back thus refreshing the data. Use dd if=/dev/ada0 of=/dev/ada0 bs=1m
3) Once you are done you need to either reboot FreeNAS or type sysctl kern.geom.debugflags=0x00 and hit Enter to restore the write protection of the mounted drive. My personal preference is to reboot FreeNAS as they you know that it is returned to normal operations.
BAD Blocks
While I personally would prefer to RMA my hard drive or install a new replacement, some people may decide that they want to run some further testing on their hard drives such as Bad Blocks because they have an issue which drove them to this hard drive troubleshooting in the first place. There is a nice thread here which documents quite a bit on how to run Bad Blocks for burn-in testing but here are the instructions for just a single drive.
I would also recommend that the drive in which you are testing is not part of an active pool/vdev, remove it first.
Drive «ada0» will be used in our example here with a Long Read Test failure at LBA 1144448. Also, read this entire section before running the test, there is nothing worse than destroying the wrong drive.
Because Bad Blocks takes generally several days to run (likely a full week) on a hard drive, I have broken down the troubleshooting into what I feel are reasonable steps in order to test the drive as quickly as possible. If you had a SMART Short or Long read test failure then we will test that section of the hard drive first because if it keeps failing then the drive is not salvageable. If you did not have a SMART read failure and just want to test the entire drive, well I’ve written the procedure to allow for that situation as well.
Record the failing LBA and then add at least 100,000 and subtract at least 100,000 to that count. These will become the ending and starting LBAs. You can subtract or add a larger value than 100,000 and it’s not a bad idea if you get zero errors during your first run. Once you are all done with the troubled area you can run badblocks on the entire surface and ensure there are no other problem locations.
There is one assumption and that is that you are running this testing on your FreeNAS system. You can place your hard drive on any other computer and boot up FreeNAS on a USB Flash drive or use Ubuntu Live CD or some other piece of software, the instructions are basically the same.
After all of this testing and fixing of your hard drive, if you have another failure several months down the road, you can rest assured that drive is having physical component failure and you can toss the drive into the recycle bin, after you take it apart and get those high strength magnets out and stick them to your refrigerator. They are painful to get back off!
WARNING: THIS IS A DESTRUCTIVE TEST, VERIFY YOUR DRIVE BY THE SERIAL NUMBER!
Setup:
Because this is destructive you should take precautions to prevent accidental damage to your good hard drives containing data. Power off your system and physically disconnect all your good hard drives from the system, leaving the suspect drive connected. Use your serial number to ensure this. Now you can power on FreeNAS and your system should boot up. If desired you can boot to an Ubuntu Live CD/ISO if you like, open a terminal window, and then go to step 3 below. If you are using Ubuntu Live, I will assume you have a clue what you are doing and do not need step by step instructions so below is just a guide for those people.
1) Open up an SSH window.
2) Note added by @wblock 2018-01-22: this section recommended enabling the kern.geom.debugflags sysctl. Many people still think it has something to do with allowing raw writes. It does not. Instead, it disables a safety system that is intended to prevent writes to disks that are in use (say, by having a mounted filesystem). From man 4 geom:
0x10 (allow foot shooting)
Allow writing to Rank 1 providers. This would, for example,
allow the super-user to overwrite the MBR on the root disk or
write random sectors elsewhere to a mounted disk. The
implications are obvious.
To summarize, this option should generally not be needed. It only makes it possible to harm data. Any disk you are going to overwrite with data should not be mounted or have anything you wish to keep. In fact, best practice is to not be erasing or stress-testing drives on a system that has actual data on it. Since those disks will not have mounted filesystems, this sysctl will not affect being able to write to them. In fact, it will only make it possible to blow away things that are in use.
2) First we need to allow you to perform RAW Write operations otherwise you will get an error message stating the operation is not permitted. Type sysctl kern.geom.debugflags=0x10 and hit Enter.
Now comes the destructive part…
3) If you did not have a SMART read failure or just want to run badblocks and walk away, goto step 8.
4) At the end of the command line is the ending LBA and then the starting LBA, in that order. We will run the test 10 times. Type badblocks -b 4096 -wsv -c 64 -p 10 /dev/ada0 1244448 1044448.
Note: The «-p 10» identifies how many times to run the test after a pass and you can increase or decrease this. I chose a value of 10 for no real reason other than I want to be very sure the surface holds up.
5) So lets say step 4 identifies a few more blocks and fixes (I use that term loosely) them. Next you should adjust the ending and starting LBA number for a larger area such as +/- 200,000. If you don’t have any failures there, then go to step 6, otherwise you go back to step 4 until you have no errors.
6) Now we need to run another SMART Long test to see if there are any more offending sectors which can be quickly picked up. Type smartctl -t long /dev/ada0
7) If the SMART Long test fails the Extended Read test again,
using the new LBA
jump back to step 4, otherwise continue to step 8.
8) Now that we can get through an entire SMART Long Read test we are ready to run Bad Blocks on the entire hard drive surface. This testing will take considerable time to run, likely several days. Type badblocks -b 4096 -wsv -c 64 /dev/ada0.
Once you are able to get through the entire badblocks program you can perform step 9 or reboot the machine, I prefer to reboot.
9) If you are not running Ubuntu Live, Type sysctl kern.geom.debugflags=0x00 and hit Enter.
Good Luck!
Resource icon by Evan-Amos @ Wikimedia Commons
What you need is the sas2ircu utility from LSI (now Avago).
LSI maintains versions for FreeBSD, Linux and Windwos. With FreeNAS you will need the FreeBSD version.
To try it you would put it in the /tmp directory and make it executable first.
Step one is discover the ID of your SAS HBA (example):
/tmp# ./sas2ircu list
LSI Corporation SAS2 IR Configuration Utility.
Version 19.00.00.00 (2014.03.17)
Copyright (c) 2008-2014 LSI Corporation. All rights reserved.
Adapter Vendor Device SubSys SubSys
Index Type ID ID Pci Address Ven ID Dev ID
----- ------------ ------ ------ ----------------- ------ ------
0 SAS2008 1000h 72h 00h:04h:00h:00h 1000h 3020h
SAS2IRCU: Utility Completed Successfully.
Step two would be generate a list of all your devices you can examine later:
/tmp# ./sas2ircu 0 display > disklist.txt
Step 3 is examining your disk list. It will look similarly to:
/tmp# vi disklist.txt
LSI Corporation SAS2 IR Configuration Utility.
Version 19.00.00.00 (2014.03.17)
Copyright (c) 2008-2014 LSI Corporation. All rights reserved.
Read configuration has been initiated for controller 0
------------------------------------------------------------------------
Controller information
------------------------------------------------------------------------
Controller type : SAS2008
BIOS version : 7.37.00.00
Firmware version : 19.00.00.00
Channel description : 1 Serial Attached SCSI
Initiator ID : 0
Maximum physical devices : 255
Concurrent commands supported : 3432
Slot : 4
Segment : 0
Bus : 4
Device : 0
Function : 0
RAID Support : No
------------------------------------------------------------------------
IR Volume information
------------------------------------------------------------------------
------------------------------------------------------------------------
Physical device information
------------------------------------------------------------------------
Initiator at ID #0
Device is a Enclosure services device
Enclosure # : 2
Slot # : 24
SAS Address : 5003048-0-00d3-a87d
State : Standby (SBY)
Manufacturer : LSI CORP
Model Number : SAS2X36
Firmware Revision : 0717
Serial No : x36557230
GUID : N/A
Drive Type : Undetermined
Device is a Enclosure services device
Enclosure # : 3
Slot # : 0
SAS Address : 5003048-0-00ca-7bfd
State : Standby (SBY)
Manufacturer : LSI CORP
Model Number : SAS2X28
Firmware Revision : 0717
Serial No : x36557230
GUID : N/A
Drive Type : Undetermined
Device is a Hard disk
Enclosure # : 4
Slot # : 0
SAS Address : 5003048-0-00d3-a8cc
State : Ready (RDY)
Size (in MB)/(in sectors) : 1907729/3907029167
Manufacturer : ATA
Model Number : WDC WD20EARS-00M
Firmware Revision : AB51
Serial No : WDWCAZA1037887
GUID : N/A
Drive Type : Undetermined
Device is a Hard disk
Enclosure # : 4
Slot # : 1
Step 4 is identifying your failed drive — you will know which by the missing or damaged information reported on the drive. Get the Enclosure # and The Slot # and use them to blink the tray LED in
step 5 : To locate Enclosure # 4, Slot # 0
/tmp# ./sas2ircu 0 locate 4:1 ON
To turn the LED off after replacing:
/tmp# ./sas2ircu 0 locate 4:1 OFF
I hope this helps!
Содержание
- Что такое SMART дисков
- Как посмотреть состояние диска
- Установка
- Использование смартктл
- На какие значения мне смотреть?
- Состояние дисков в QNAP NAS
Что такое SMART дисков
Все жесткие диски и SSD-накопители оснащены технологией SMART, также известной как SMART, что означает «Технология самоконтроля, анализа и отчетности». Эта технология, включенная в прошивку жестких дисков и твердотельных накопителей, заключается в обнаружении возможных сбоев в жестком диске с целью прогнозирования физических ошибок на жестком диске или неожиданных сбоев в твердотельных накопителях из-за записи во внутреннюю флэш-память. . Цель SMART — предупредить пользователей, чтобы они могли создать резервную копию и заменить диск без потери данных. Если мы будем игнорировать SMART, придет время, когда жесткий диск сломается, и мы потеряем данные, поэтому важно всегда обращать внимание на данные SMART дисков.
Чтобы использовать SMART, абсолютно необходимо, чтобы BIOS или UEFI сервера были совместимы с этой технологией и чтобы она была активирована, кроме того, также абсолютно необходимо, чтобы диски включали ее. Сегодня все серверы, операционные системы и диски используют эту технологию для обнаружения проблем с жестким диском, можно сказать, что она «универсальна» и используется всегда.
Эта технология отвечает за мониторинг различных параметров жесткого диска, таких как скорость пластин диска, сбойные сектора, ошибки калибровки, проверка циклическим избыточным кодом (типичные ошибки CRC), температура диска, скорость чтения данных, время запуска (отжима). up), счетчик перераспределенных секторов, скорость поиска (время поиска) и другие очень продвинутые параметры, которые позволяют узнать, что важно: скоро ли выйдет из строя жесткий диск.
Внутренне SMART имеет диапазон значений, которые мы можем считать «нормальными», и когда параметр выходит за эти значения, то есть когда срабатывает сигнал тревоги, BIOS/UEFI обнаружит это и уведомит операционную систему о сбое. в системе. диск, и это может быть серьезно. В операционных системах Linux у нас есть возможность проводить тесты SMART, чтобы проверить, правильно ли работает диск, кроме того, у нас есть возможность запрограммировать эти тесты, чтобы минимизировать влияние на производительность.
Как посмотреть состояние диска
В большинстве дистрибутивов на базе Linux есть пакет под названием smartmontools. Иногда этот пакет предустановлен в нашем дистрибутиве, а иногда нам приходится устанавливать его самостоятельно. Этот пакет состоит из двух разных программ:
- смартктл : это программа командной строки, которая позволяет нам проверять жесткие диски и твердотельные накопители по запросу, или мы можем запрограммировать ее работу с помощью обычного cron в операционной системе.
- умный : это демон или процесс, который проверяет, что жесткие диски или твердотельные накопители в указанный интервал времени не имели сбоев. Он способен регистрировать любой тип предупреждений или ошибок диска в основной системный журнал сервера, а также позволяет отправлять эти же предупреждения и ошибки по электронной почте администратору, чтобы он мог убедиться, что все правильно.
Пакет smartmontools отвечает за мониторинг жестких дисков и SSD-накопителей, независимо от того, используют ли они интерфейсы SATA, SCSI, SAS или NVME, он поддерживает любой тип интерфейса данных. Разумеется, эта программа совершенно бесплатна.
Установка
Установка этой программы, если она не установлена по умолчанию в вашем дистрибутиве Linux, осуществляется с помощью менеджера пакетов вашего дистрибутива. Например, в операционных системах Debian с apt это будет так:
sudo apt install smartmontools
В зависимости от менеджера пакетов вашего дистрибутива вам придется использовать ту или иную команду, важно то, что этот пакет доступен для всех дистрибутивов на основе Unix, а также для Linux, поэтому вы также можете без проблем установить его на FreeBSD.
Использование смартктл
Чтобы использовать эту программу и проверить состояние нашего жесткого диска, первое, что мы должны сделать, это узнать, сколько у нас жестких дисков и каков путь для проверки этих жестких дисков или твердотельных накопителей. Чтобы узнать, где находятся диски, мы должны выполнить следующую команду:
df -h
Мы также можем использовать fdisk для получения списка дисков, которые есть на нашем сервере:
sudo fdisk -l
Эти команды покажут нам список устройств, а также разделов. Мы должны использовать эту программу на уровне жесткого диска или SSD, а не на уровне раздела. Обычно в системах Linux мы находим диски по пути /dev/sdX.
Как только мы узнаем, какой диск мы собираемся проанализировать, чтобы проверить его работоспособность с помощью SMART, мы должны знать, что в общей сложности есть два разных теста, которые мы можем выполнить:
- Короткий тест – Этот тест чаще всего используется для выявления проблем с дисками. При выполнении этого теста он покажет нам самые важные ошибки и предупреждения, без необходимости подробно анализировать весь диск. Мы можем запланировать этот короткий тест через cron еженедельно, таким образом, один раз в неделю он будет выполнять этот анализ и уведомлять нас, если обнаружит какие-либо ошибки. Желательно делать этот тест в то время, когда толку мало или совсем нет, не рекомендуется делать его в рабочее время, лучше на рассвете.
- Длинный тест – Этот тест может занять довольно много времени, в зависимости от накопителя и его емкости. Выполнив этот комплексный тест, он покажет нам все предупреждения или ошибки, обнаруженные на всем диске. Мы можем запланировать этот длинный тест с cron, чтобы он выполнялся ежемесячно, то есть один раз в месяц мы будем выполнять этот тест для проверки работоспособности диска. Желательно делать этот тест в то время, когда диск мало используется, например, на рассвете, потому что в противном случае производительность чтения и записи, а также задержка доступа к данным значительно возрастут.
Как только мы узнаем два типа тестов, которые мы можем использовать, первое, что нам нужно знать, это то, включен ли SMART на жестком диске или твердотельном накопителе:
sudo smartctl -i /dev/sda
В случае, если диск поддерживает SMART, но не активирован, мы можем активировать его, выполнив следующую команду:
sudo smartctl -s on /dev/sda
Чтобы увидеть все атрибуты SMART производителя рассматриваемого диска, мы можем выполнить следующую команду:
sudo smartctl -a /dev/sda
Чтобы выполнить короткий тест, мы выполняем следующее:
sudo smartctl -t short /dev/sda
Чтобы выполнить длинный тест, мы выполняем следующее:
sudo smartctl -t long /dev/sda
После того, как мы выполнили короткий или длинный тест, мы можем выполнить следующую команду, чтобы увидеть все результаты:
sudo smartctl -H /dev/sda

Мы рекомендуем прочитать справочные страницы smartctl, где вы найдете все команды, которые мы сможем выполнить, чтобы использовать возможности SMART, однако основные команды — это те, которые мы вам объяснили.
На какие значения мне смотреть?
Когда мы проведем SMART-тест, появится большое количество атрибутов нашего жесткого диска или SSD. Некоторые из этих значений являются критически важными, на которые мы обращаем пристальное внимание, потому что они могут дать нам «подсказки» о том, что диск очень скоро выйдет из строя:
- Reallocated_Sector_Ct: количество секторов, которые были перераспределены в другие области диска из-за ошибок чтения. Эта ошибка очень типична, когда диск очень старый и срок его полезного использования подходит к концу.
- Spin_Retry_Count: это количество попыток, которые были необходимы для загрузки диска, это указывает на серьезную аппаратную проблему на диске, и он может не загрузиться в следующий раз.
- Reallocated_Event_Count — количество успешно или неудачно выполненных перераспределений. Чем выше число, тем хуже состояние жесткого диска.
- Current_Pending_Sector: количество секторов, ожидающих скорого перераспределения.
- Offline_Uncorrectable: количество неисправимых ошибок при доступе (чтении или записи) к различным секторам диска.
- Multi_Zone_Error_Rate: общее количество ошибок при записи сектора.
На следующем изображении вы можете увидеть состояние жесткого диска WD Red 4 ТБ из нашего NAS с операционной системой XigmaNAS:

На предыдущем снимке экрана вы можете увидеть много информации, но мы должны знать, является ли это изолированным сбоем или наш диск может скоро выйти из строя.
Состояние дисков в QNAP NAS
Если у вас есть NAS-сервер QNAP, Synology или ASUSTOR, вы также сможете видеть SMART-статус ваших жестких дисков и твердотельных накопителей через операционную систему с веб-доступом, нет необходимости входить через SSH или Telnet и выполнять какие-либо команды . В приведенном ниже примере мы использовали NAS-сервер QNAP, но процесс с другими производителями был бы очень похож.
Первое, что нам нужно сделать, это перейти в « Хранилище и снимки », оказавшись здесь, нажмите « Хранилище / Диски » и мы увидим что-то вроде этого:

Если мы нажмем на « Состояние диска », нам придется выбирать, какой диск из всего мы хотим посмотреть. Мы можем выбрать как жесткие диски HDD, так и SSD-диски, независимо от их типа, потому что они также имеют внутреннюю информацию SMART, чтобы увидеть, есть ли ошибка диска.

В меню «Сводка» мы можем увидеть общее состояние диска, если есть какая-либо ошибка или серьезное предупреждение, мы также можем легко и быстро увидеть общее состояние, без необходимости проводить подробный анализ SMART. значения . Конечно, мы также можем увидеть историю доступа к диску и узнать, были ли какие-либо проблемы.

Хотя QNAP предоставляет нам очень простую для понимания информацию, если мы хотим увидеть все необработанные значения, мы также сможем сделать это без проблем. Кроме того, у нас будет дополнительный столбец, который сообщает нам «Статус» и хороший он или плохой.
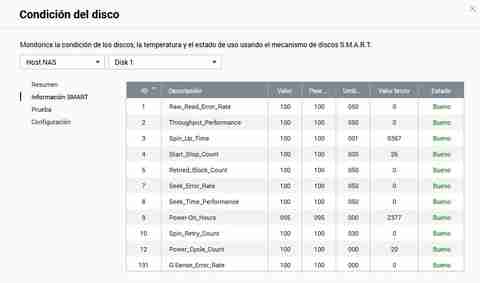
Здесь мы сможем проводить быстрые или полные тесты, нам просто нужно выбрать метод тестирования, а затем нажать кнопку «Тест».

Наконец, мы также можем запрограммировать эти тесты очень простым способом, нам просто нужно активировать быстрый или полный тест и выбрать частоту: ежедневно, еженедельно или ежемесячно, кроме того, мы можем определить время начала этого теста.

Как видите, проверка состояния жестких дисков и твердотельных накопителей на сервере очень важна для предотвращения потери данных. При возникновении любой ошибки очень важно купить новый диск и сделать резервную копию, чтобы избежать потери данных. Кроме того, мы также должны проверить состояние RAID, потому что мы можем привести к потере всего пула хранения, особенно если мы настроили ZFS RAID 0 или Stripe.